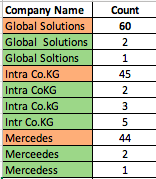
i am working on a small project at school. Actually i am at one point where i have no clue how to go further. I have a column with company names where due to spelling mistakes the company name can be spelled wrong. For example the company name has 2 instead of 1 space, a letter is missing or the dot notation is wrong. In this case i have done a count on the company names and the one with the most hits is the right name.
I would like to change all the other columns that are similiar to the one with the highest count to the right name of the row with the highest counts. Attached you can see example (the green fields should be renamed in the oranged one). Maybe some of you guys have a better idea how to solve this Every hint would be a lot of help for me. I have tried different things from Manipulation until Regex, but nothing works out…
thank you for the advice. I already had a look on it, but my problem is that i only have one table and i dont know how to get the right names out of it to get into the fuzzy matching.
I only have the information that the right company name is the one with the hightest number of counts.
I think you just need to create a lookup table based on strings with large counts. There may be a bit of nuance to this - you’ll have to arbitrarily pick some cutoff based on your dataset - and it may not work 100% for company names with small n. But you could use the Numeric Row Splitter node to make such a lookup table.
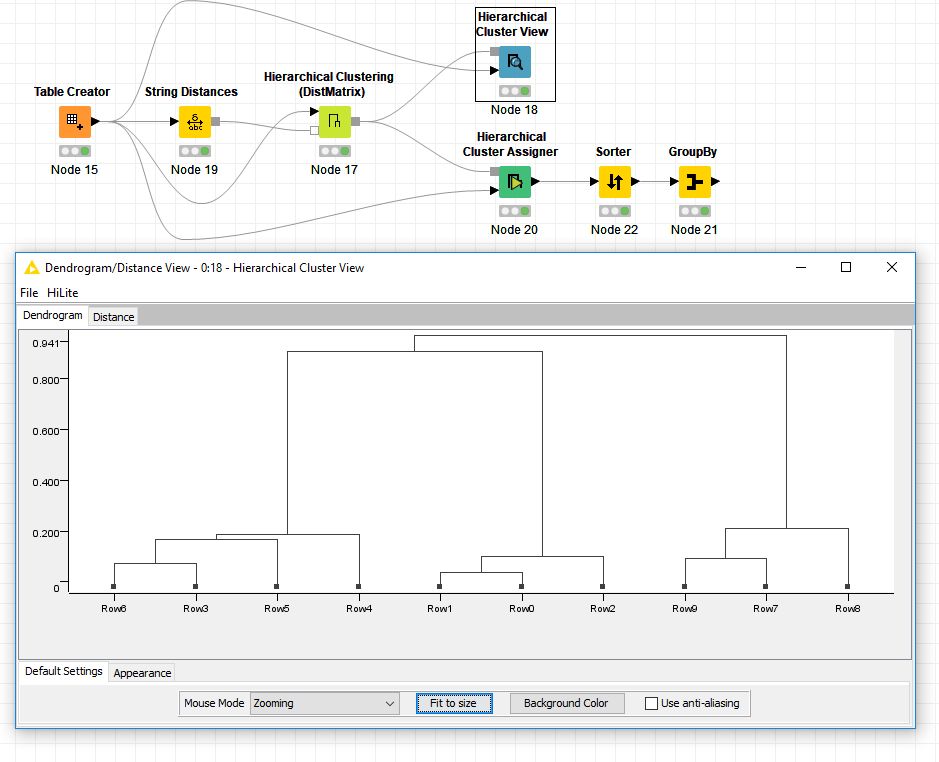
Another option if you’re not confident all companies will have a count above your cut off or if they might have multiple spellings above your cut off would be to use a clustering approach. If you use hierarchical clustering you can set a string distance cut off instead of a cluster number.
After everything is clustered you can group them by the most common spelling and sum of counts. Attached an example below. You can see how close the spellings are in string distance to each other in the hierarchical cluster viewer.
Loving how many different ways we can tackle this problem!
 Every hint would be a lot of help for me. I have tried different things from Manipulation until Regex, but nothing works out…
Every hint would be a lot of help for me. I have tried different things from Manipulation until Regex, but nothing works out…