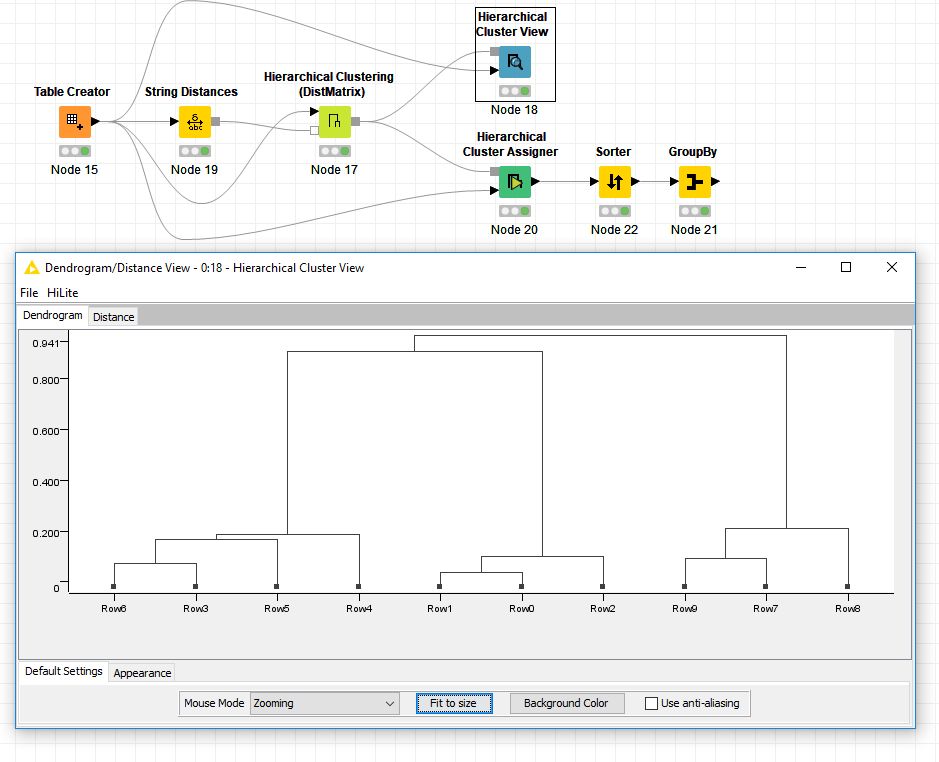
Another option if you’re not confident all companies will have a count above your cut off or if they might have multiple spellings above your cut off would be to use a clustering approach. If you use hierarchical clustering you can set a string distance cut off instead of a cluster number.
After everything is clustered you can group them by the most common spelling and sum of counts. Attached an example below. You can see how close the spellings are in string distance to each other in the hierarchical cluster viewer.
Loving how many different ways we can tackle this problem!
Typo Correction.knwf (14.2 KB)