Hello, thanks for the help & patience.
PDF parsing runs into a data problem I’m not familiar solving with KNIME. Maybe there’s a tool or set of tools I’m missing. I’m eager to parse a PDF a certain way, I feel I’m missing something.
Goal, incoming data is a PDF. We get it to this point and I noticed a pattern in the data that I want to be able to capture into columns for debits/credits/balance to a bank account.
(can’t share data, only examples)
4/4 Recurring Payment authorized on 04/03 Netflix_Com Netflix_Com 10.81
Splitting per space generates:
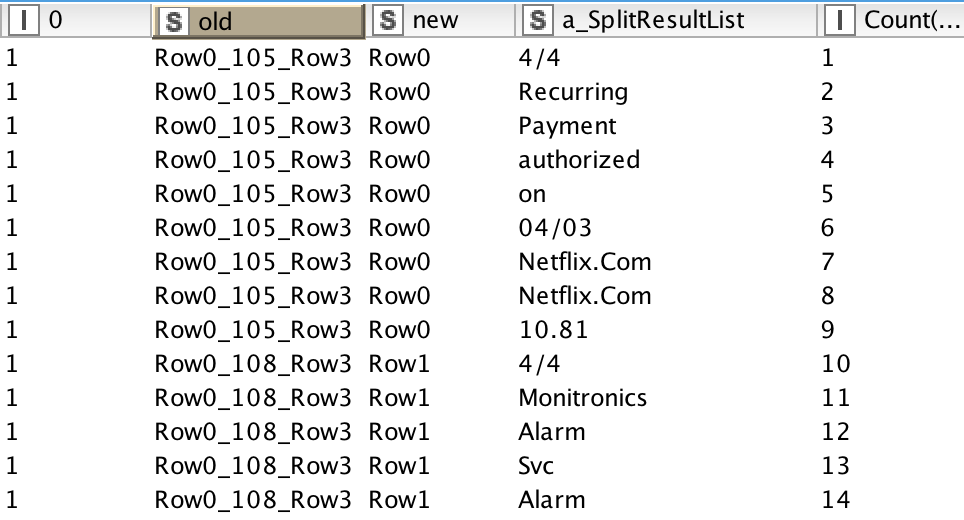
Far right row id, if I could restart the rowid per column [new], like a group by, that would be perfect.
4/4 Recurring Payment authorized on 04/03 Netflix_Com Netflix_Com 10.81
5/4 Recurring Payment authorized on 04/03 Netflix_Com Netflix_Com 10.81
6/4 Recurring Payment authorized on 04/03 Netflix_Com Netflix_Com 10.81
At the end of every purchase, there’s always 1 or 2 sets of numbers.
The split on SPACE gives me a potential of saying “what’s my max value” of a running sum of 1. I want to understand other options to increase my ability to solve these problems faster. Seems I’m getting warmer but probably googling the wrong keywords to find the right node for the solution.
4/4
Recurring
Payment
authorized
on
04/03
Netflix_Com
Netflix_Com
10.81
Sometimes there’s two numbers… (fake sample)
4/4
Recurring
Payment
authorized
on
04/03
Whatever_Com
Some
random
text
Whatever_Com
10.81
20.20
Sometimes the number is a credit and sometimes the number is a debit, if the last two are numbers, it’s always…
10.81 (negative from balance)
20.20 (your balance after the purchase)
My question:
When trying to find the max value of a running sum(1), or the last two values, I find myself wanting to do a running sum of 1, grouped by the duplicated rowid column. Shown in the screenshot. The rowid is duplicated similar to this sample data source below…
| id | text |
|---|---|
| 0 | 4-20 |
| 0 | text |
| 0 | text |
| 0 | 24.5 |
| 1 | 5-21 |
| 1 | text |
| 1 | text |
| 1 | 5-20 |
| 1 | text |
| 1 | 55.5 |
| 1 | 200.20 |
| 2 | 6-1 |
| 2 | text |
| 2 | text |
| 2 | text |
| 2 | 6-3 |
| 2 | text |
| 2 | text |
| 2 | 60.40 |
| 2 | 520.10 |
The goal would be to learn how to do the repeating row id, or restarting moving aggregation or whatever we want to call it. Maybe there’s a tool i don’t know about. I feel the loop tool can handle it, but I’m curious what are the options.
End objective.
| id | text | desire |
|---|---|---|
| 0 | 4-20 | 1 |
| 0 | text | 2 |
| 0 | text | 3 |
| 0 | 24.5 | 4 |
| 1 | 5-21 | 1 |
| 1 | text | 2 |
| 1 | text | 3 |
| 1 | 5-20 | 4 |
| 1 | text | 5 |
| 1 | 55.5 | 6 |
| 1 | 200.20 | 7 |
| 2 | 6-1 | 1 |
| 2 | text | 2 |
| 2 | text | 3 |
| 2 | text | 4 |
| 2 | 6-3 | 5 |
| 2 | text | 6 |
| 2 | text | 7 |
| 2 | 60.40 | 8 |
| 2 | 520.10 | 9 |
Now I can find these max values easier. Maybe there’s a better solution. Would love to know.
Thanks for your time.
Thanks
Tyler
edits - fixing links to have underscore VS netflix dot com.