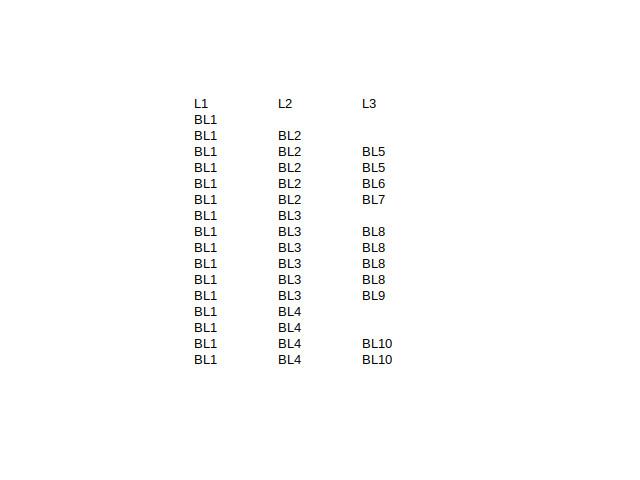
Hi, I have a hierarchical dataset with missing values in multiple rows which needs to be populated based on checking in the column to it’s left if the value is the same as the previous value in the column. If the value is the same, then the missing value can be populated with previous value, else it needs to be left blank. Here’s a description of the current and desired datasets.
In the attached datasets, L1, L2 and L3 are column headers. I have tried solving this problem by concatenating missing value nodes for L2 and L3 columns to populate previous values but this is giving an error as the missing value note does not know where the previous value should not be entered (i.e. where the value in the left column changed). Could you please guide on the right way to build this workflow?