Hi all,
I am facing this issue with my information.
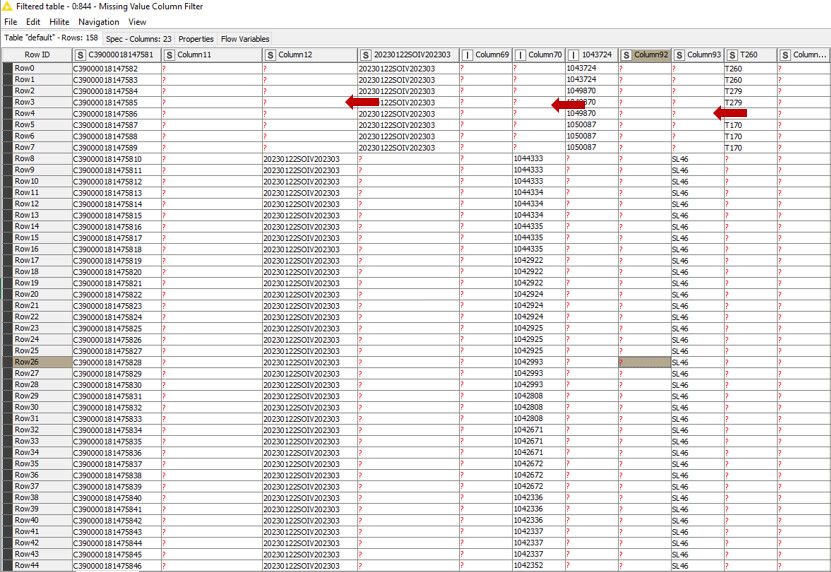
After split information by space, appears a lot empty information and I would like to adjust columns moving fields in a vertical way.
I attach screenshot, hope you can help me with this problem
Hi all,
I am facing this issue with my information.
After split information by space, appears a lot empty information and I would like to adjust columns moving fields in a vertical way.
I attach screenshot, hope you can help me with this problem
Hi @BrandonBasurto , considering your table size is small, here’s one way to do it:
Step 1. Convert the integer types to strings using a Number to String Node.
Step 2. Transpose the table using a Transpose Node.
Step 3. Use a Missing Value Node to instruct all missing values to be replaced with the values from ‘Next Row’.
Step 4. Repeat step 2 to re-transpose the table.
Let me know if you have any issues with this workaround. By the way, you might want to revisit how you perform the splitting process, to avoid this issue from happening in the first place.
You could fulfil this modification with the Rule Engine node.
You have to implement a Rule Engine node into your workflow for each column, what you would like to modify.
In the settings of the node you have to define which column would you like to use in case of missing values, and as default (if there is value in the original column in given row) you have to use the values of the original column.
I hope it helps, if my description is not clear, please attach a sample dataset and I will upload a workflow to show how it works.
Roland
Hello @BrandonBasurto
There are few issues that I cannot understand, on how did you get into column mess as in the image.
Split work in KNIME would lead a column ‘Array’ type naming; but some columns are standard column numbering whilst some other are taken a row register from your data, so this is the first issue you may want to check in the workflow. Importing the data with option data has not headers, can help at this stage.
If the image is the result of a concatenate operation, you can use a Column Rename node before row binding.
If the splitting is the referred to an ascii type file, resulting from a previous binding, Rule Engine for each column as anticipated by @rolandnemeth can work. Some other valid workarounds are doable as @badger101 mentioned.
The approach that hasn’t been mentioned is:
regexReplace($Concatenate$, "\\|+", "\\|")Hope this helps
BR
PS.- Reading the data without splitting and remove consecutive spaces before splitting, can work as well.
sample data would be helpful. Maybe the issue can be fixed in a prior node already
Hi guys, thank you for your support.
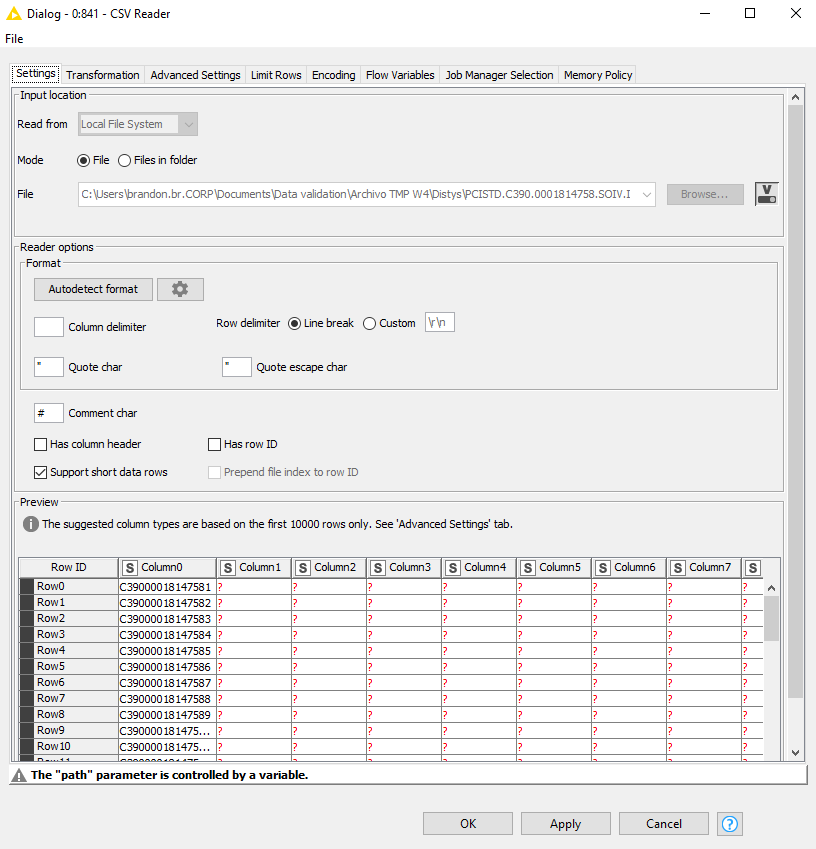
I have tried each solution than you sent to me, let me share to you my current csv reader node configuration, as you mentioned maybe the issue comes from it.
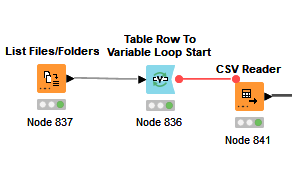
I am using a loop to read some files in folders
CSV Reader configuration is the next screenshot
After tried all your solutions the close solution could be:
But loop does not work
Do you have any idea to solve issue in the CSV Reader? or make loop works?
Thank you a lot
@BrandonBasurto upload your existing workflow and a bunch of your csv files in order to help to you
Can’t really tell too much just from the images, but you appear to have 2 loop starts in there and 1 loop end. Also, are your CSV files a bunch of different table structures? If so, you are going to have to build in a methodology to access the structures and process them so they concatenate or join up cleanly. You can use conditional tests and If Switch nodes to route the different table structures though different processing paths.
Typically I would read in an individual file of each structure and get a clean workflow going before I tried to read a bunch of files in via a loop.
If you decide to go the route of just cleaning up the null values by referencing the other columns then you can also use the column expressions node with a formula similar to below.
if(isMissing(column("1”)))
{column("2”)}
else
{column("1”)}
Go to loop end settings and allow “changing table specifications”
br
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.