Hi @andymesmo , the padLeft() function is used for padding something, in this case, to the left.
For example padLeft("1", 3, "0") means I want to have at least 3 characters, and fill up with “0” if the input data is less than 3 characters. So “1” will become “001”.
Similarly padLeft("11", 3, "0") will become “011” and padLeft("111", 3, "0") or padLeft("1111", 3, "0"), etc will remain as original data, since they are already 3 or more characters.
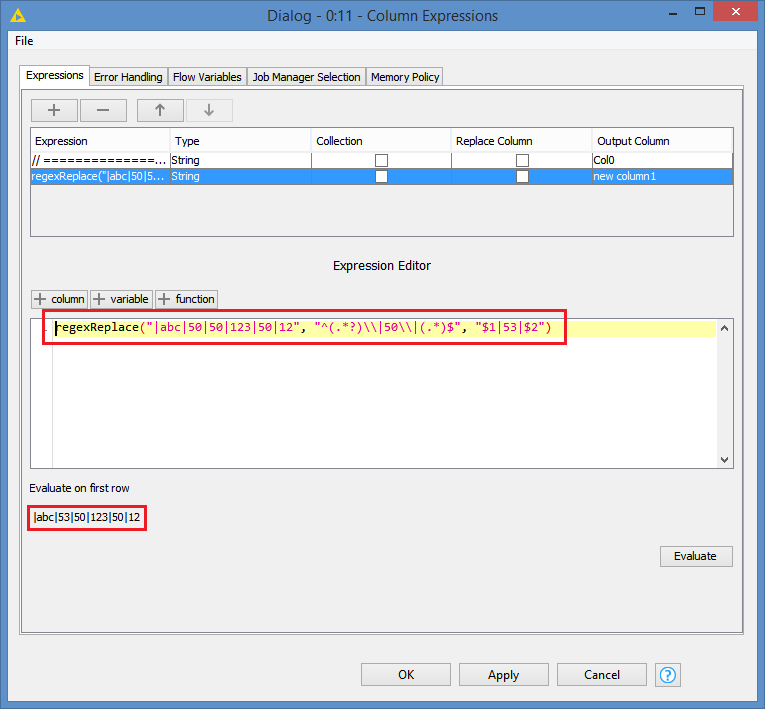
I haven’t looked at your workflow, but I can’t see how padLeft can be used based on the explanation of “change to the first occurrence of the specific lines when I encounter a string |50| and change to |53|”. Could it be that you misunderstood what the padLeft function does?
EDIT: I downloaded your workflow. In your expression:
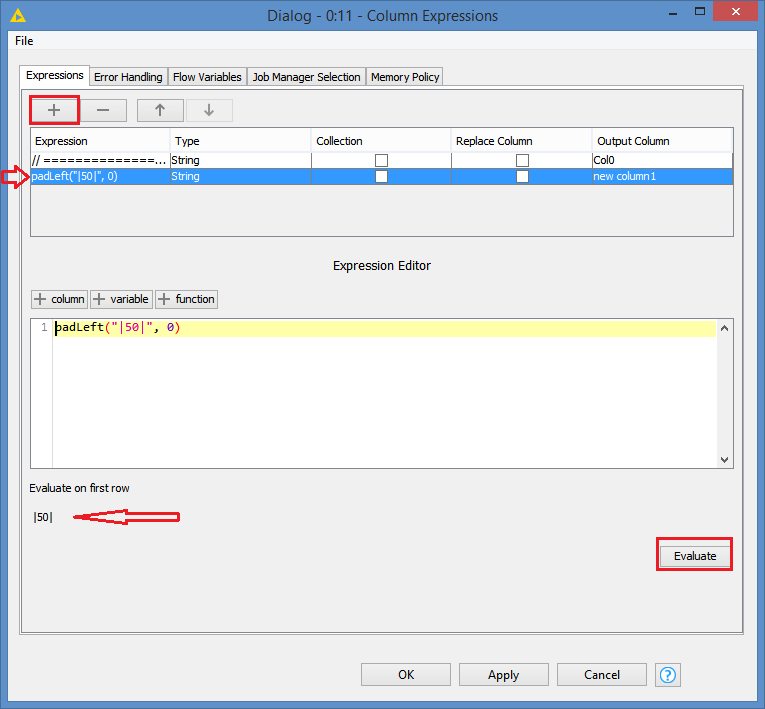
replace(column("Col0"), padLeft("|50|", 0),"|53|")
padLeft("|50|", 0) basically would be just the same as the original string “|50|”.
So your expression is the same as:
replace(column("Col0"), "|50|", "|53|")
which means replace all instances of “|50|” with “|53|”, provided the if conditions are met that is.
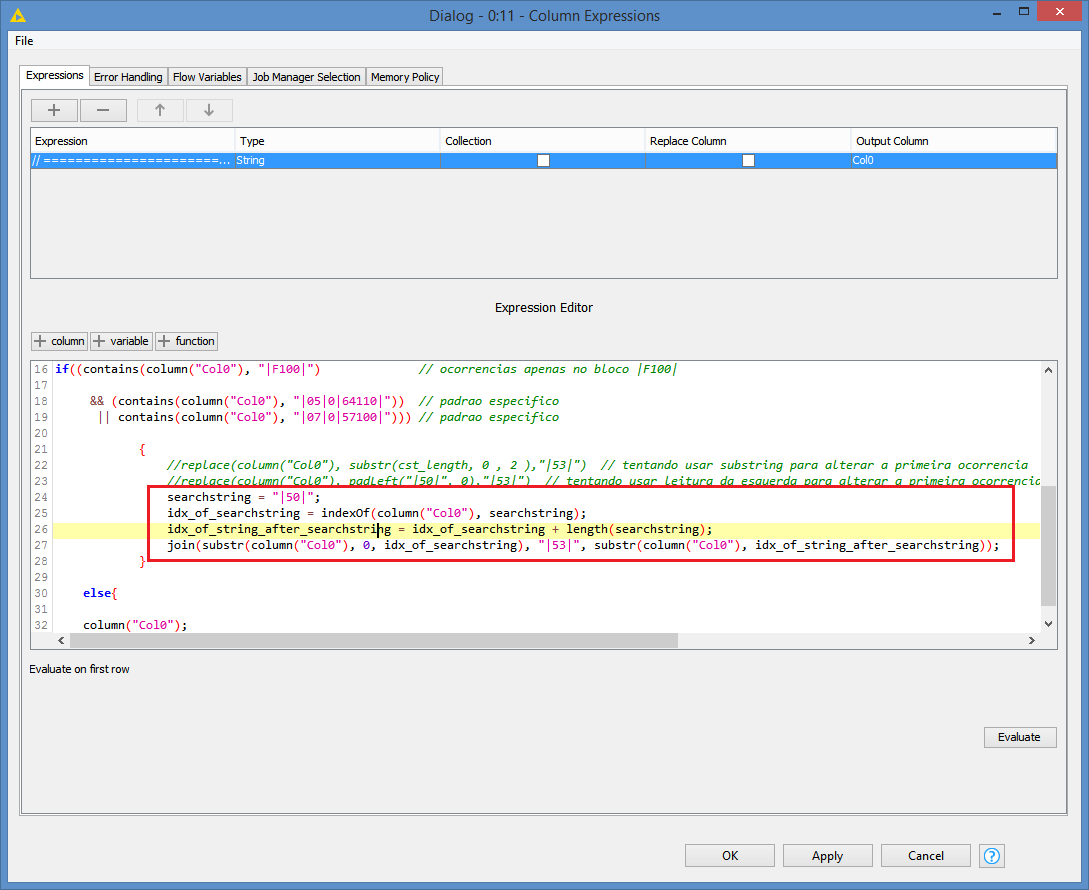
What exactly did you want to change? Can you explain a bit? It sounds like not all “|50|” should be change. In which case should it change?