Hi, all. I’m running into an issue with importing space-delimited data from a flatfile, and it’s not totally clear how best to go about it.
In the flatfile, each line is formatted as follows:
abc def ghi jkl mno pqr stu natural_language_sentence(s)
All fields are space-delimited strings of varying lengths. The eighth contains sentences written in plain English, which in turn contain spaces of their own.
Because the first seven spaces are always present, I would like to replace those with tabs. It should then be easy to process the result into eight separate columns.
What I can’t figure out is where in any of the nodes I’ve looked at this can be accomplished, and while I’ve found some examples that get close to what I’m looking for, none really fit the bill. Any assistance would be appreciated.
I’m not sure if I understood your question well. But it looks like you want to split a string based on a space-delimiter to convert it into columns. Have you checked the Cell Splitter node?
But better is to provide a sample/dummy dataset that is like your input and an example of your desired output.
gr. Hans
Sorry, I could’ve been clearer about this. I understand what you’re saying regarding the cell splitter, but I’ve realised that my data will need to be preprocessed before I can run it through the cell splitter. This is because the file is space-delimited, but one of the resulting cells will contain data that itself has spaces in it.
Let me see if I can describe the data structure better:
Every underscore between ‘abc’ and ‘stu’ represents a space that I’d like to convert to a tab. This also applies to the underscore between ‘stu’ and ‘natural’.
Every underscore after ‘natural’ should remain unchanged. Basically, this means only changing the first seven instances of a space in the line, and ignoring any after that.
Each line follows this format, so there will always be seven delimiting spaces before the free-form string data that I don’t want to change.
Does this help to describe what it is I am attempting to do? Essentially, it comes down to, “convert the first seven spaces found in the line to tabs, then move on to the next line.”
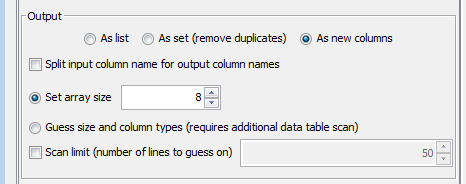
Maybe I’m missing something but if you read your file as one column and then use Cell Splitter with array size 8 shouldn’t you get your 8 columns separated properly?
What you’re saying makes sense, but when I tried it a cell was created at every space. For the first seven cells this was fine, but depending on the contents of the eighth cell this could result in up to a couple of hundred cells being created.
It seemed odd to me, but as I’m new to KNIME I just put it down to not being familiar with how it handles operations like that.
 (You can mark the topic solved)
(You can mark the topic solved)