I am working on a data set that has Missing Values for Age and another boolean column. Is it fine to replace Age with mean/median/mode or is there a better method to replace missing Age?
Also, What is the best method to replace Boolean missing values?
Hi @devrajr , replacing the missing values with the average value is acceptable in academic works. It even has its own term - mean substitution - in the academia. But if you want to be critical, refer to the discussion on missing values replacement here: The prevention and handling of the missing data - PMC At the end of the day, it’s up to the researcher to evaluate the best method to deal with the case, with justifications he/she deemed proper.
Thanks for sharing! I knew some methods in R and Python, like MICE. Not aware right now of how to implement that in KNIME. Will look for the options available in the MissingValue Node.
This other article demonstrates a case where MICE is better than mean substitution.
And, this this workflow by @Kathrin might help you out on how to do it in KNIME if you decide that MICE is suitable for your dataset based on the info learned from the article.
Simply replacing missing values with, for example, an average is always possible.
But I would modify the method according to the use case I have.
Suppose you want to select people who are older than x-Age (because then they receive a discount), that does not always go well with an average age.
If a feature is important I would pay some attention to do an analysis of why (in what case) the value is missing.
The lack of age may not be randomly distributed, but may be more common within some groups in your dataset. And perhaps this insight can help you choose a different (better?) strategy to replace your missings with some estimated value (from an algorithm).
gr. Hans
Thanks @badger101 for the very interesting links you have shared here.
@devrajr, as stated by @badger101 & @HansS, replacing missing values is context dependent and might have a crucial impact on what one does with the data afterwards.
What is the aim of your missing data replacement ? Is it just just to guess the most plausible values and then fill the gaps or are you building a model from the data after missing data replacement ?
Based on the goal, the best method to use may be very different too.
I have a dataset of 5000 odd rows on which I am looking to develop a classification model for prediction. The Age column has 500 missing values and another boolean column has 1500 missing values, so I was looking at methods to replace those missing values in KNIME.
@devrajr you could try and use R’s “Amelia” package to impute missing values. I am working on some additional missing value replacement wrappers for Python packages in KNIME.
Have you estimated the importance of these two variables before doing missing variable replacement (MVR)? If they are not significant to the model, then there is no need to replace the missing values a priori.
For instance, you could check it by removing first any sample with missing values and then evaluating the variable importance on the rest of the data set. An easy way of checking for variable importance is to use a DT and check whether your “Age” and “Boolean” variables are retained to build the DT. Otherwise train your chosen model with and without these two variables in this reduced data set to compare and see whether there is a significant difference between the model statistics in a CV or K-Fold test set scheme.
If this proves that the two variables are not needed, then you would not need to care about MVR. Otherwise, the previous cited MVR schemes by @mlauber71, @HansS & @badger101 are all good MVR candidates with different levels of complexity.
Just a last comment with respect to these methods. If you apply them, make sure that the MVR is done without using for it your final Test data set or at least the column to predict in order to avoid any data leakage and hence an over estimated biased performance of your final model.
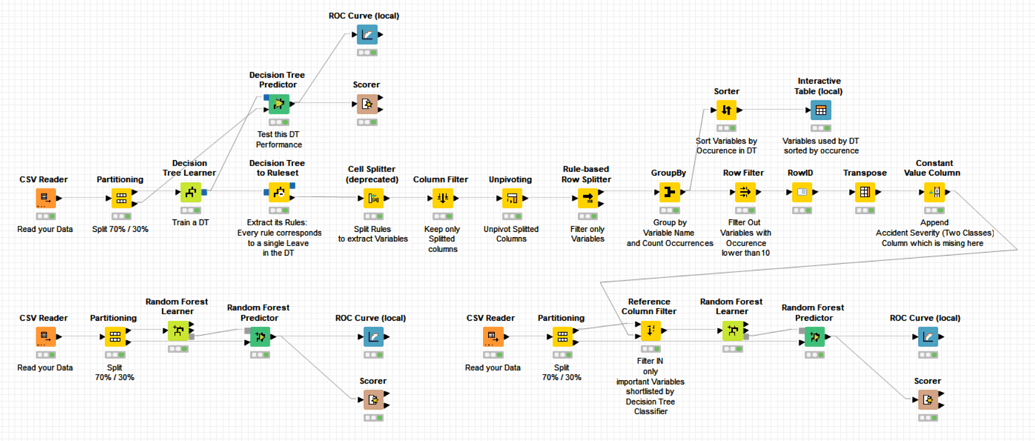
related I guess to this thread, please be aware that if you have done variable selection based on the -Feature Selection for Random Forest Classification- workflow,
In general, variables that have been selected based on a DT VS scheme should be also appropriate to use in a -Naive Bayes- model.
This is also true for -SVM- with the restriction that -SVM- models only accept numerical variables and therefore, any informative qualitative variable selected by a DT would not be suitable to use as direct input data in a -SVM- model which is a pity. If the qualitative variables sound to be really significant to solve your clasification problem, then go for a model that accepts them as input variables, for instance any Tree based model (DT/RF/Xgboost/etc).
As an extra information, linear -SVM- models are capable of variable selection because they set to zero the multiplicative coefficient of useless variables in the final linear equation. However, the linear -SVM- VS should not be considered as valid in the case of problems which are not linear because the underlying -SVM- model is not linear and would only capture linear relationships between variables and classes.
DT and RF in general implicitly do non-linear VS and hence can capture non-linear relationships between input variables and the class to predict.
To summarize and in general, I would use as preliminary VS method the workflow you found called -Feature Selection for Random Forest Classification- and then I would apply and compare the panoply of classification methods of your choice based on this preliminary VS.