Hi @devrajr
Following your question:
related I guess to this thread, please be aware that if you have done variable selection based on the -Feature Selection for Random Forest Classification- workflow,
https://forum.knime.com/uploads/short-url/fOhd6B1lL01pyVQswnLy8SILH4R.knwf
then the final selected variables are those that one should use to train a -Naive Bayes- or a -Support Vector Machine- model.
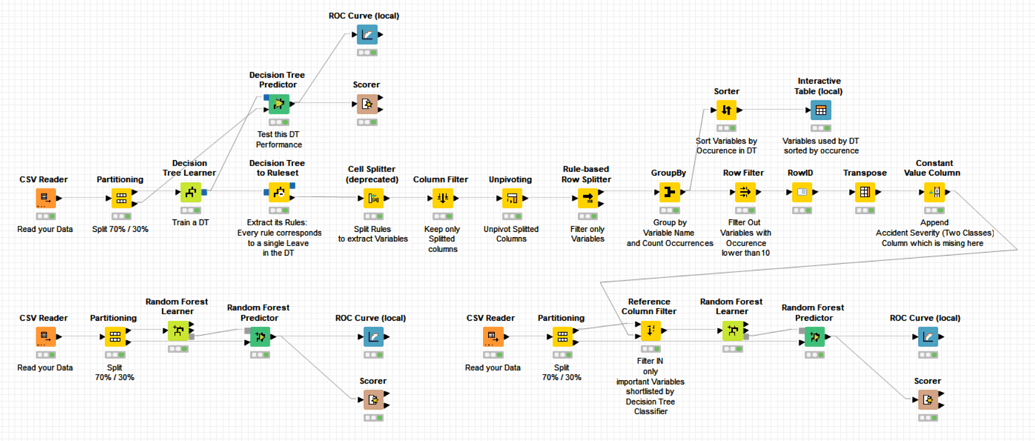
In general, variables that have been selected based on a DT VS scheme should be also appropriate to use in a -Naive Bayes- model.
This is also true for -SVM- with the restriction that -SVM- models only accept numerical variables and therefore, any informative qualitative variable selected by a DT would not be suitable to use as direct input data in a -SVM- model which is a pity. If the qualitative variables sound to be really significant to solve your clasification problem, then go for a model that accepts them as input variables, for instance any Tree based model (DT/RF/Xgboost/etc).
As an extra information, linear -SVM- models are capable of variable selection because they set to zero the multiplicative coefficient of useless variables in the final linear equation. However, the linear -SVM- VS should not be considered as valid in the case of problems which are not linear because the underlying -SVM- model is not linear and would only capture linear relationships between variables and classes.
DT and RF in general implicitly do non-linear VS and hence can capture non-linear relationships between input variables and the class to predict.
To summarize and in general, I would use as preliminary VS method the workflow you found called -Feature Selection for Random Forest Classification- and then I would apply and compare the panoply of classification methods of your choice based on this preliminary VS.
Hope it helps.
Best
Ael