Replacing multiple columns of text strings with new columns of text strings. Text strings vary from single word to six words for each string. There are hundreds of these text descriptions throughout 40 columns.
Obviously, Dictionary Replacer fails as it can only replace one column at a time, and I cannot make it work on multi-length word text descriptions.
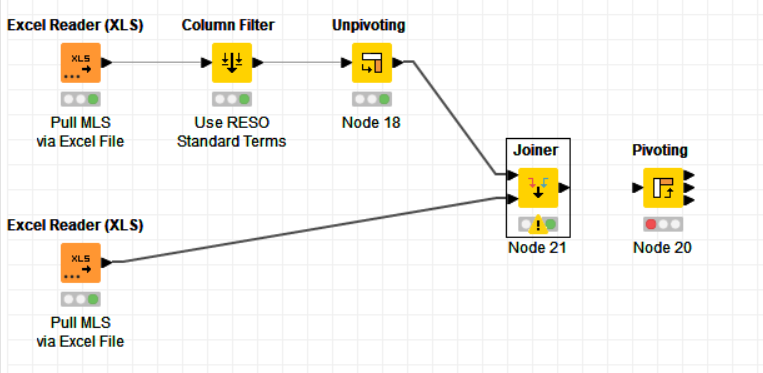
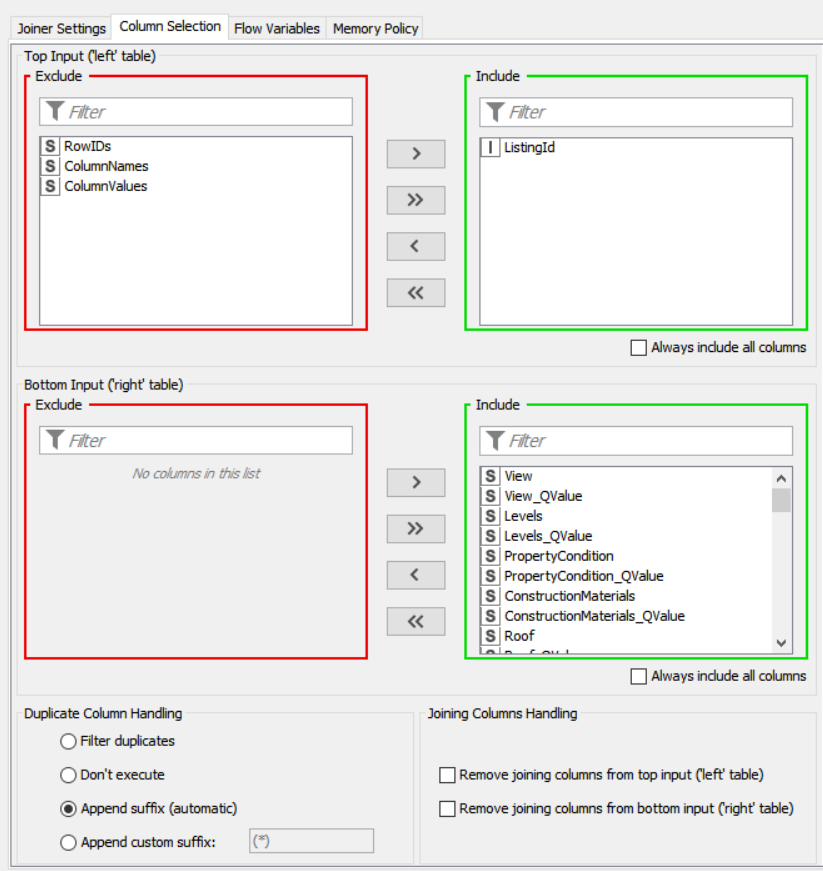
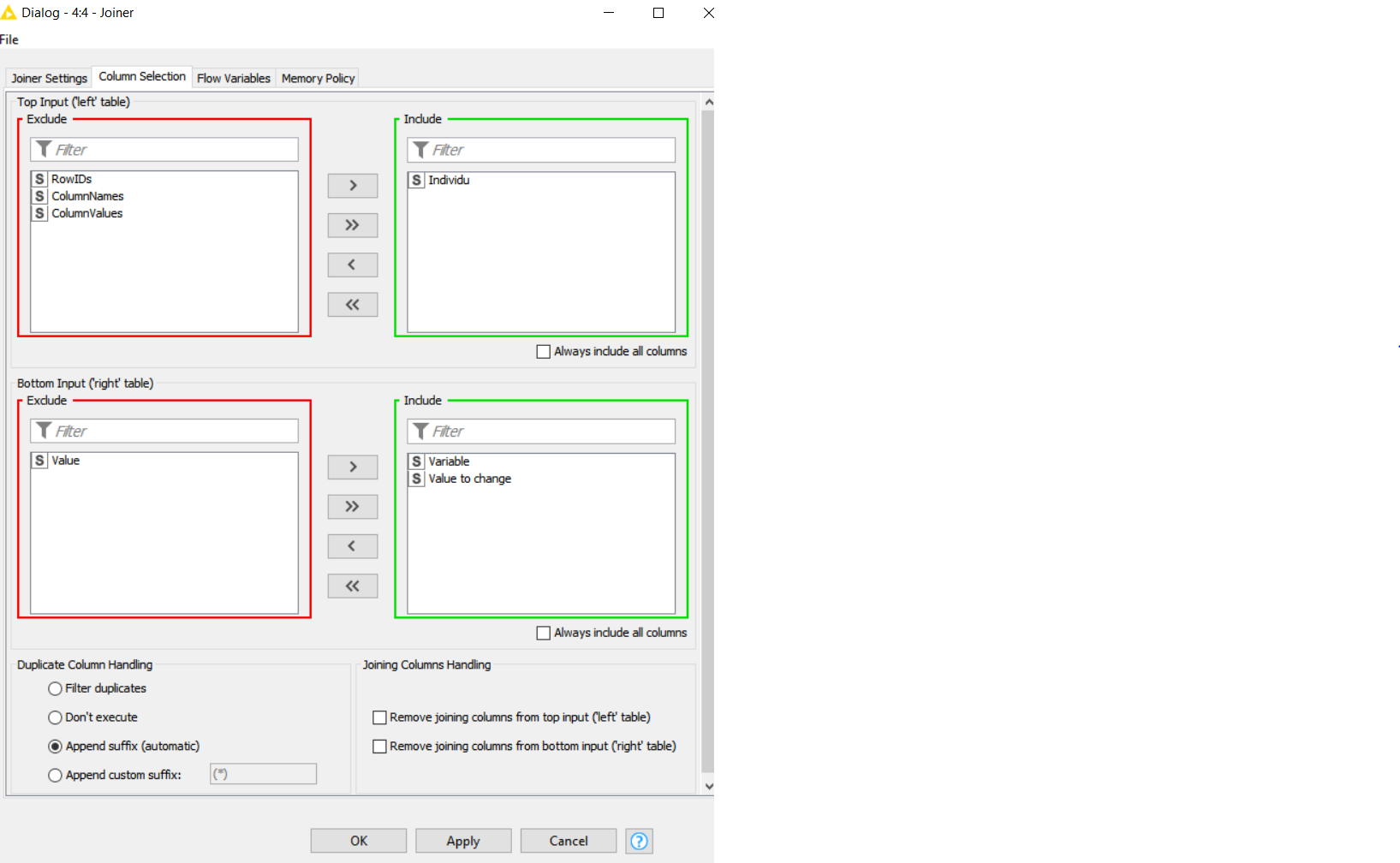
I’ve tried many times using Unpivoting+Dictionary+Joiner model—then Pivoting to work (first graphic below). But I receive an empty set at the Joiner outcome. I believe it is because I am unable to place S:Value in the lower left box in the Joiner Column Section (second graphic below). The example I was mimicking is the third graphic below.
Four questions:
How can I fix the above described failing?
Do I also need to convert Strings to Terms for this endeavor?
Some columns have a single series of these multi-word text descriptions—but other columns contain many of these multi-word text descriptions separated by commas (I download data from the source as CSV, but am converting it to Excel and using the Excel Reader node).
After I replace the original text descriptions to the new text descriptions, I will need to complete an additional replacement of the new text descriptions to numeric codes. What additional nodes will I need to add to the model to complete this text to number task?
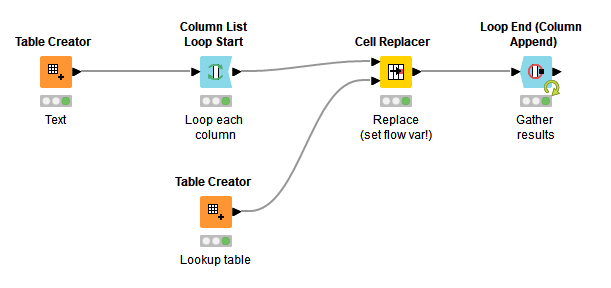
Maybe this will help you get started. I think the key here is to use a Cell Replacer inside an appropriate loop setup. This way you can avoid using the text processing nodes, as well as the pivoting/unpivoting approach you were thinking of.
This is just a simple example that I put together in five minutes, but see if you can adapt it to your real data. (Sounds like you may need to do some additional preprocessing on your lookup table first.)
I’m brand new to using KNIME and simply found a quick excel solution that worked for reading the files. No further grand logic. This portion of the project is simply pulling the source data, converting the source text descriptions to my “standardized” text descriptions (several front end uses for this), then converting my standardized text descriptions to numeric tokens for clustering and regression analyses.
I am attaching some files for you here.
The first two related to “hilltop” are in CSV and XLS. These are my downloaded source files for now. One day, if I can get the full system working “manually”, this will all me move to an automated production mode. Also attached is my initial “dictionary” for the text-to-text conversion and my text to numeric conversion.
Thanks for your help while I begin to learn the many KNIME options available.
(Hmmm, a note from this chat does not allow CSV upload so I’m attaching the excel files only “Sorry, the file you are trying to upload is not authorized (authorized extensions: jpg, jpeg, png, gif, knar, knwf, zip, xls, tiff, tif, xlsx, txt, log, lsm, doc, docx, json, xml, pptx).”
I have checked your data a bit and this seems like big proper project at first. There’s a lot of data and lot of mappings to do. You’ll probably need to do some data preparation before mapping starts at all. My recommendation is to start with smaller and simpler data that mimics real data in format and then scale it up once you got it running to some degree.
Good luck and if you’ll have any questions feel free to ask!