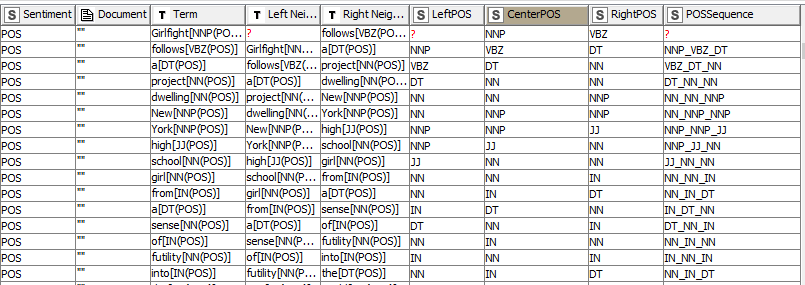
I am wondering if there is a convenient way to analyse sequences of words in terms of the POS tags rather than just their lexical meanings. For instance, I want to know how often certain grammatical constructions appear, such as “pronoun adverb” or “verb adjective”. Basically, I want something like the ngram creator, but with the option of analysing the tags instead of (or as well as) the terms.
Another approach would be to modify the document terms so that they include the POS tag as part of the word. Then I could use the the existing ngram creator and separate the terms and tags myself using string manipulation rules.
Actually I am currently simulating the latter approach by splitting my text into sentences, tagging the POS, then using the bag of words output together with the dictionary replacer to append the POS tags to the terms (for example, ‘strange’ would become ‘strange_JJ’). But this method has obvious limitations, the main one being that you have to guess which POS tags match up with which instances if terms occur multiple times in a document. It also involves a lot of extra processing. It is not a proper solution.
I note that another user asked a similar question a few years back here and here. That specific problem might now be solved with the term neighbourhood extractor, but that is only helpful if you are interested in a few specific terms rather than recurring generic patterns.
It seems a shame not to be able to get the full value out of the tagged text. Or is there a feature I have missed?
Thanks.