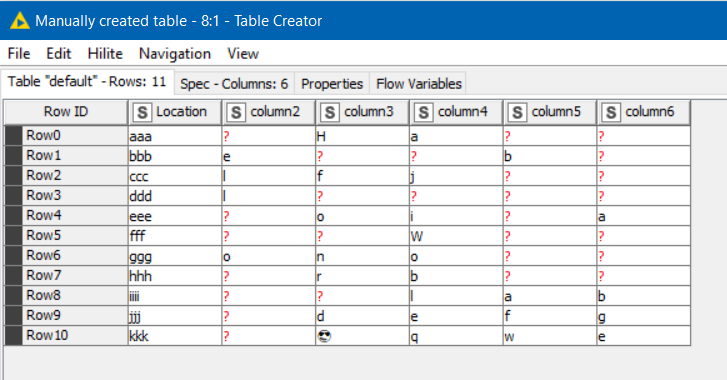
I have a list of email addresses, each stored in different column labeled by the type of contact (e.g. teacher, department head, principle, etc.)
Each row is a unique location.
I have the columns prioritized from most important to least important (left to right if it matters)
Many columns have lots of missing values
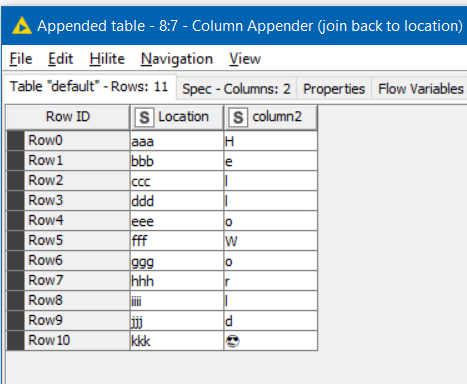
I would like to create one column labeled “highest priority contact” that retrieves only one value for each row: the highest priority email address.
This seems like it should be very straightforward. I can do it in Excel with a long series of if-then statements… but I’m trying to learn KNIME and I’d like to use a loop and a flow variable to do it (rather than construct a long series of if-then statements.)
Generally for something like this if you can upload a sample data file (with dummy data) it allows us to work on the problem more easily rather than having to create our own data to work with, as often a solution involves a little trial and error rather than an immediate idea of how to do it.
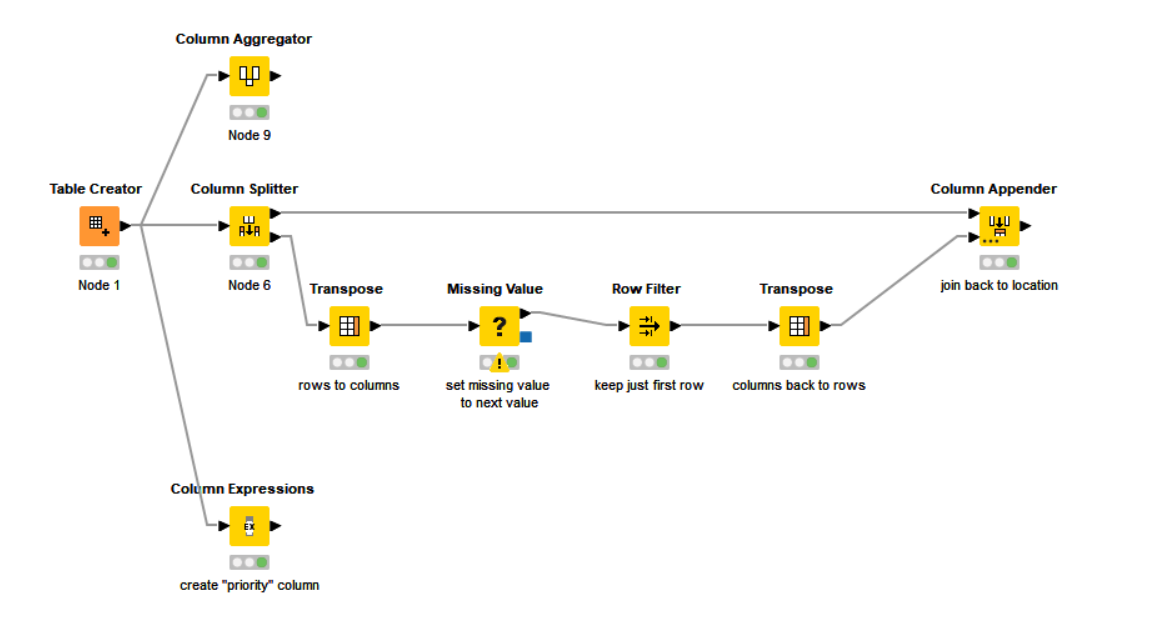
In this case, you don’t need loops or flow variables. By turning the table 90 degrees, it is possible to make use of nodes which are better at handling rows than they are at handling columns. At the other end of the process, it can be “rotated” back again.
[Edit: I’ve updated this as I completely overlooked the simple one-node solution, using Column Aggregator or Column Expressions (if you have KNIME Expressions extension installed)]
If you really want to find a solution with loops and flow variables (for learning purposes), let us know. I only use loops when I see no other option, because loops are a lot slower than non-loop solutions especially on large data sets). Currently I’m struggling to find a loop solution that doesn’t feel horribly contrived!