I have two sets of data, RULES and DATA.
DATA consists of some variables and RULES is the definition of how to count DATA table in several ways and the target counts desired.
DATA
text
var1
var2
var3
var4
weight
aaa
1
1
1
4
1
bbb
1
2
2
3
1
ccc
2
1
3
2
1
…
…
…
…
…
…
…
…
…
…
…
…
zzz
2
1
3
2
1
RULES
rulename
rule
target
rule1
var1 = 2
75
rule2
var2 = 2
50
…
…
…
…
…
…
ruleN
var3= 1 AND var4=2
80
The mundane flow should be as follows:
Count number of rows in DATA matching rule1 in RULES, update the weight columns in matching rows of DATA to the value that would make the count match the target in RULES table.
Proceed to rule2 in RULES and continue until all rules are completed.
The ideal approach would be to have a sort of self-correcting iterative loop to do this several times, perhaps with randomly changing starting rows since it might have an effect on the outcome. Then compare different runs and end up with minimum varying weights from 1.
I honestly have trouble posting the full process since I can’t imagine how to put what I have in mind into the board. Would you have 5-10 minutes for a call where I can show the live-process in Excel for example and if you can solve it, we can then post the solution here?
so let me try to make an example if i got it right:
For rule 1, I would find 2 rows (ccc and zzz). The target is 75, so i would have to 75/2 = 37,5 as a weight in row ccc and zzz correct? than proceed to rule 2, find row bbb and target 50, but the actual weight is 37,5 so would I update it to 50 or do (37,5+50)/2?
This should be an iterative process, once all the rules are processed, it should run more times based on some conditions like min-max weight etc.
Since this is a sequential process, I was dreaming about running this with randomized rule order and comparing multiple set of runs against each other and select best performing (again based on min-max weights)
Thank you for posting the expected output, now it’s clear what you need.
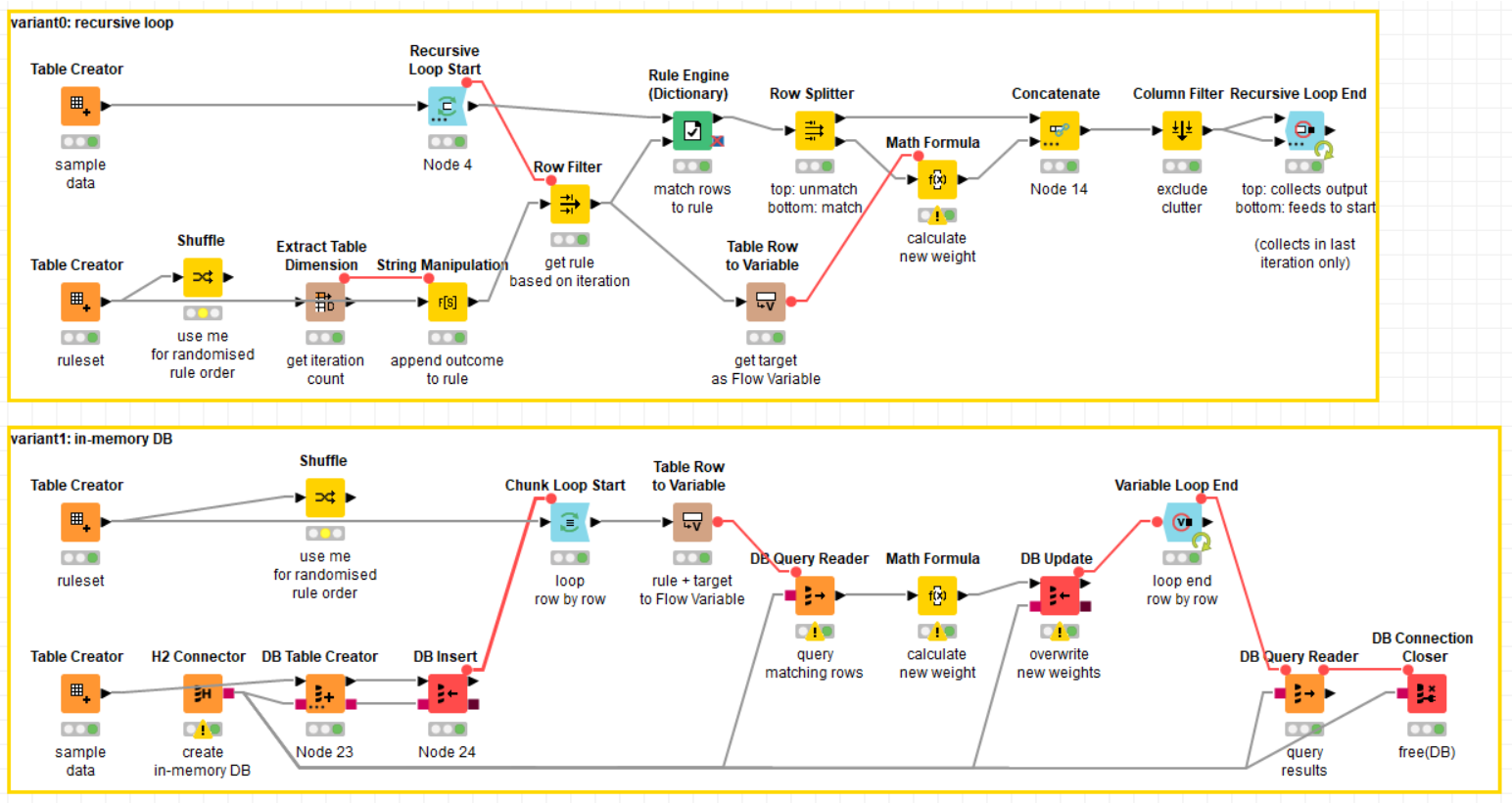
This can be done with a Recursive Loop, a Rule Engine (Reference), Row Filters, GroupBy and Math Formula nodes. For randomising the rule order there’s a node that shuffles the table.
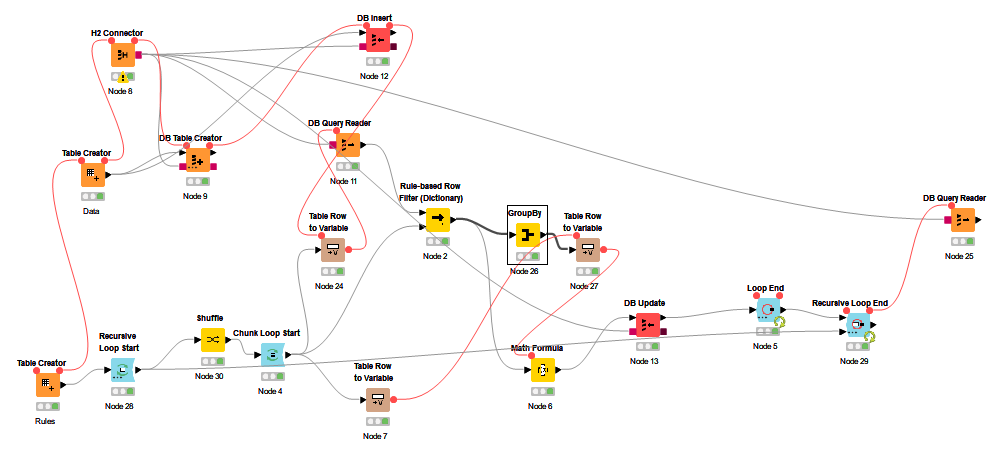
I build something, because I thought this a fun brain teaser. My main problem was to use the updated table in the loop again. Because I don’t know better I used a in memory database.
The workflow is not beautiful but it seams to work. You just have to execute the last “DB Query Reader”. In the Recursive Loop End" you can modify the amount of iterations.
First of all, I really like the idea of using a temporary DB to feed the manipulated data back to the loop start. This effectively provides recursive loop functionality. @goodvirus I’m wondering whether your Recursive Loops are an artefact from building the WF? It’s set to 1 iteration, so it doesn’t do anything
I Node Golfed your idea, this can be useful for other problems as well.
I also noticed you’re using the Rule-based Row Filter (Dictionary). That’s a new one. I wanted to use it, but the DB Query Reader can be fed the rules directly.
Now to my solution: I’m using the Recursive Loop Start/End. The central idea is to process one rule, then feed the table with the updated weights back to the loop start. The loop runs for as many times as there are rules (controlled via Flow Variable).
Row Filter gets one rule using the current iteration
Rule Engine (Dictionary) matches data against rule (Rule-based Row Filter (Dictionary) would work as well)
Row Splitter to bypass non-matching rows
Math Formula to update weights. (it can do sum of column and other basic aggregations)
Concatenate bypassed rows, Column Filter, rinse and repeat
@Thyme: Thank you for the updated flow, it helps me to learn! I wanted to mix recursive loop and in memory table (to get and experience with both ;)) The iteration is 1 on purpose to verify that I get the right results that @Bahadurma predicted, but i have testet it with a lot more iterations.
What would be interesting is which option would be faster when we have a lot of rules and a large data table. I guess the database option because it could work faster with indices for a big dataset, but maybe the new column backend takes the lead.
Wow! I’m even being given options to choose from, what a far cry from where I started myself
@goodvirus and @Thyme thank you both for your time, I am kind of happy to see that this gave you both some ideas for other purposes at least.
Now like a spoiled child, I will remind the last paragraph of my initial post hehe
If I treat your solutions like a single item, I should be able to somehow wrap it in another loop and then compare the weight column statistics of multiple loops of the same flow with shuffles rows I’d guess, right? I assume there will be different solutions based on different row order and I’d like to test 30-50 to arrive at minimum weights.
@Thyme , yeah I’ve just used the “use me for shuffled rows” outputs and the output changes drastically based on row order (with this very limited sample data). I will try to see what happens if I place the whole thing into a bigger loop with 10 total iterations over the whole rules table.
Paul, you’re right, if you use the Recursive Loop with more than 1 iteration, it’ll actually do something: The DB Insert is not part of the loop, so the Recursive Loop uses an ever-changing table. I never heard of RIM weighting before, but if the weights converge to some fixed value, then that’s exactly what the algorithm is supposed to do? None of my versions can do that out of the box.
A Generic Loop Start with a Variable Condition Loop End wrapped around the Chunk Loop should do the trick though (it’s the same thing as the Recursion Loop in this case).