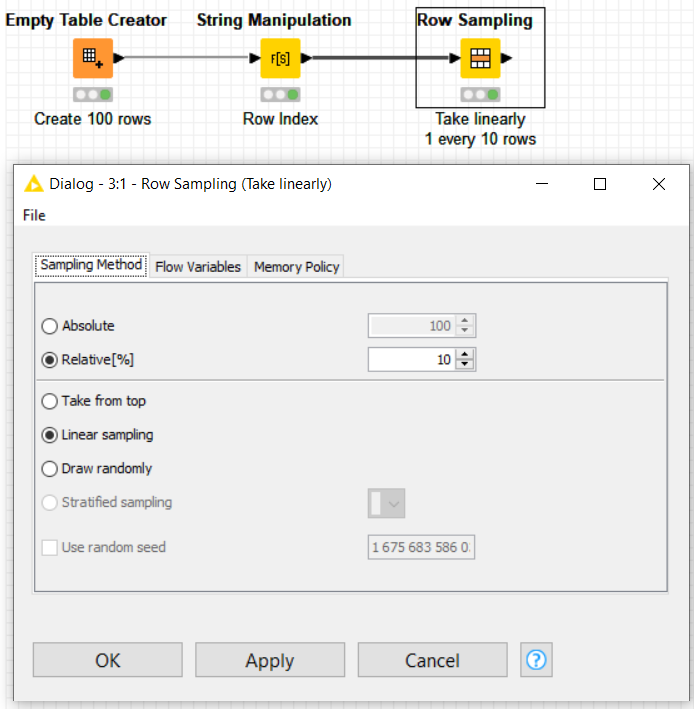
I’m looking for a way to filter out every x:th row from a table, f. ex. to reduce a table by a factor.
I was thinking of using the row-based filter and an expression like
$$ROWINDEX$$ % 10 = 0 => TRUE (i.e. modulo of rowindex, this would keep every 10th row)
but I can not get it to work. Any suggestions on how to achieve this?
Thank you @aworker and @gonhaddock for the solution(s), and also for the welcome.
Both solutions are appreciated, it’s good to know that there are dedicated nodes as well as a more generalized way to solve it. I have marked Ael’s answer as the solution, but both are valid. (As a sidenote, I guess it’s more efficient to use the dedicated node(s) when applicable, as there is no need to create an extra column and an extra step.)
Thank you @Quaqq for having validated the solution.
As mentioned in your last post of the thread, using a dedicated node is often the fastest solution, specially if the alternative to the dedicated node is a combination of nodes. The reason is that the same table needs to be scanned as many times as nodes are serially connected.
Having said this, one can monitor the efficiency of a node or set of nodes using the following monitoring node:
This may also allow you to compare @gonhaddock solutions to the -Row Sampling- and -Partitioning- nodes too.