I need to perform a comparison of rows of my data and I am struggling with the logic/nodes that I need to use.
With reference to the below table, what I need to do is:
Example, I need compare the data in the 2 rows, and if all the rows are the same except [“Type de carton” and “Desc carton” and “box_lab_nbr”] i want to keep the row where [“box_lab_nbr” = 2] .
Once the comparison has been completed, I need to loop through all my table
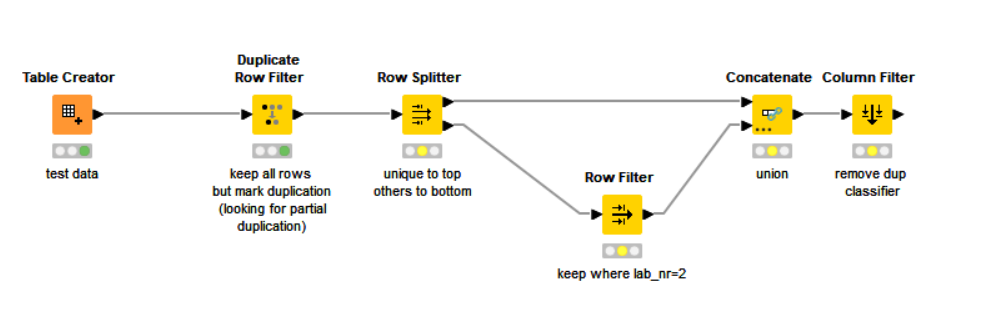
You can choose which columns to include for the duplications check. Have it retain all rows but mark with a “duplicates classifier”. Then split rows between those marked as “unique” and the remainder. Of the remainder (lower port on the row splitter) keep only those where lab_nr=2. Then reassemble as a single table and filter off the duplicates-classifier column.
No need to loop. This will handle the entire table in one go.