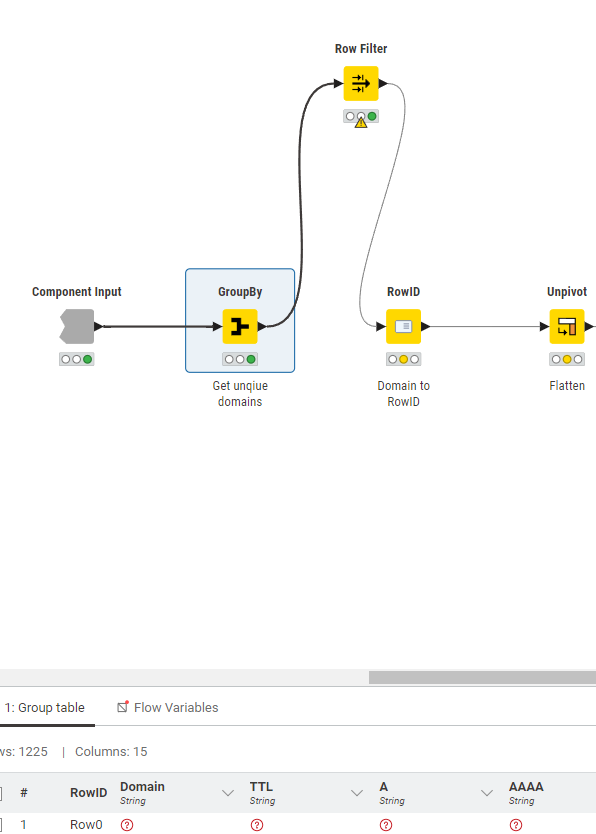
It seems the rules are not applied sequentially … or I struggle to properly write down my idea.
PS: It just incurred to me the, if followed strictly, it could throw a wrench in the gearbox as boundary filtering, i.e. row 2 to 10, would not quite work.
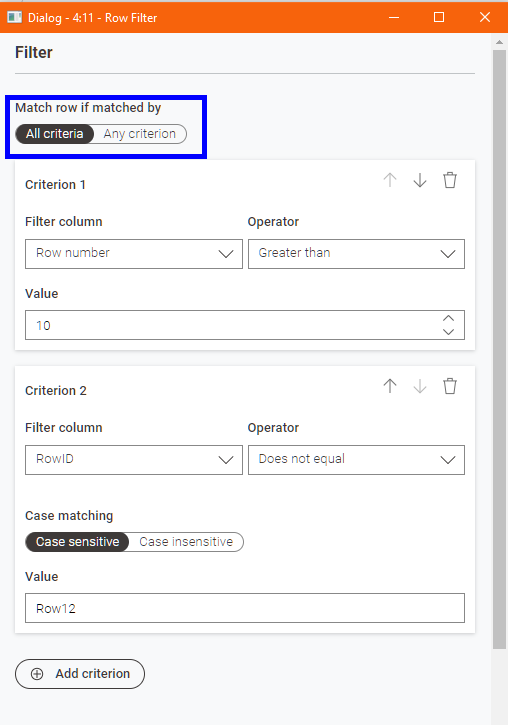
I think you may have posted the wrong screenshot for the conditions but I hope I understand what you are saying.
My understanding is that in the new Row Filter, the rules are applied according to the choice at the top of the configuration which is whether “All rules apply” or “Any rules apply”.
So I believe there is no sequence, as such, to the conditions
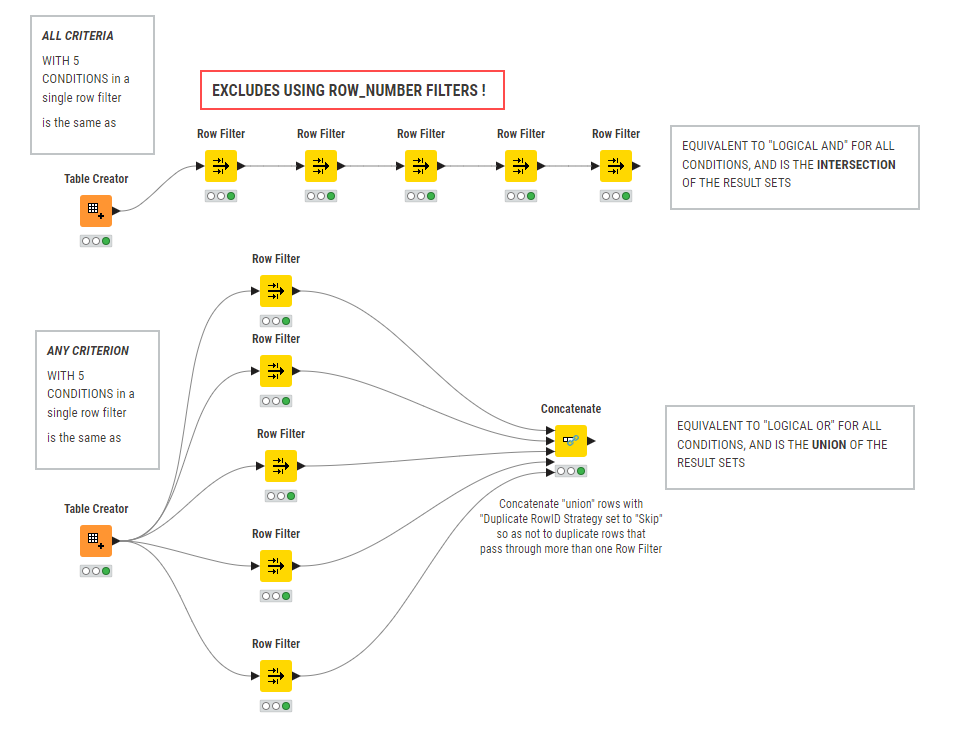
All Criteria
Condition 1 AND condition2 AND condition 3…
Any Criterion
Condition 1 OR condition2 OR condition 3…
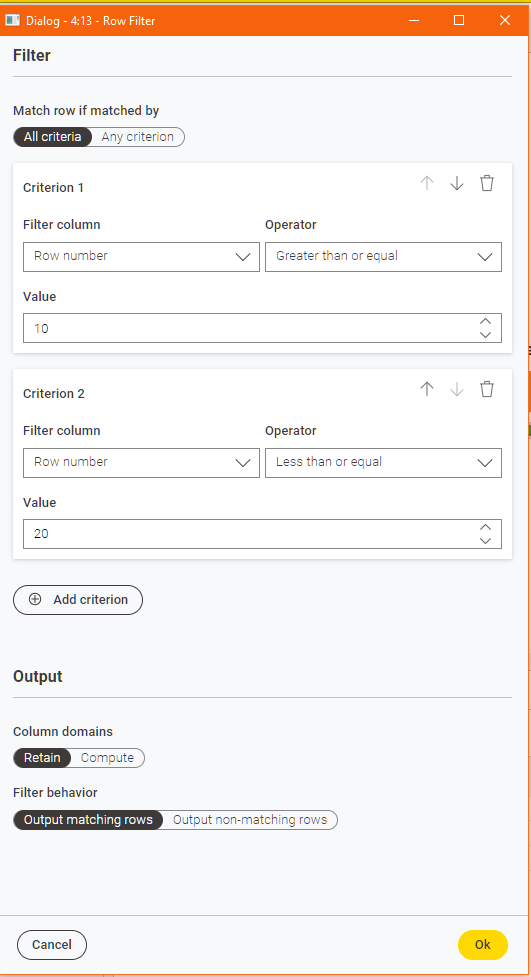
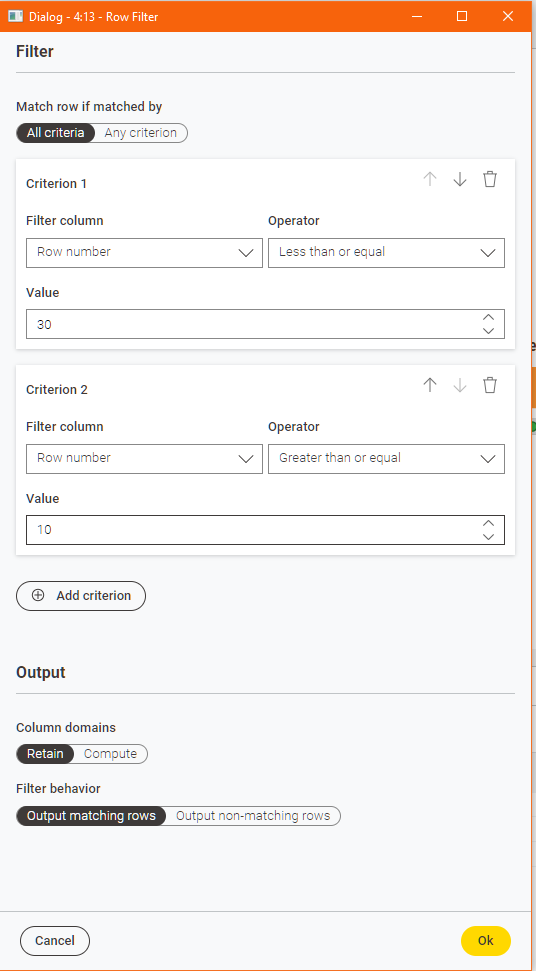
So for a boundary you would require 2 conditions with “All Criteria” selected; one condition is for value >= lower boundary, and the other condition for value <= upper boundary
It’s possible to include other special conditions, provided all apply. So it could be…
return rows between row number 10 and 20 and fruit= “apple”
return rows between row number 10 and 20 and fruit not equal “apple” and currency = “USD”
… so there is some flexibility over what the old node could achieve, but still no fancy mixing of AND / OR in the conditions. For that there will be the Expression Row Filter, as you will know from hacking 5.4
The criteria are all “in a bag” and not sequential on purpose, so we can apply some optimization techniques. For example, all Row number criteria are grouped together to enable efficient slicing of the input table. On the columnar backend, this is very efficient to evaluate.
If you need sequential processing, it is best to chain some Row Filters one after the other, such that the structure of the workflow tells the story as much as possible. In case a more complex filter criterion is needed, the Expression Row Filter will provide that option starting in AP 5.4. I haven’t used it personally yet, but I think expressions can refer to previous expressions, so in that case you should be able to sequentially chain your filter criteria.
I understand your desire to express complex criteria in the Row Filter, but we decided to keep the Row Filter simple and offer the Expression Row Filter for more complex use cases.
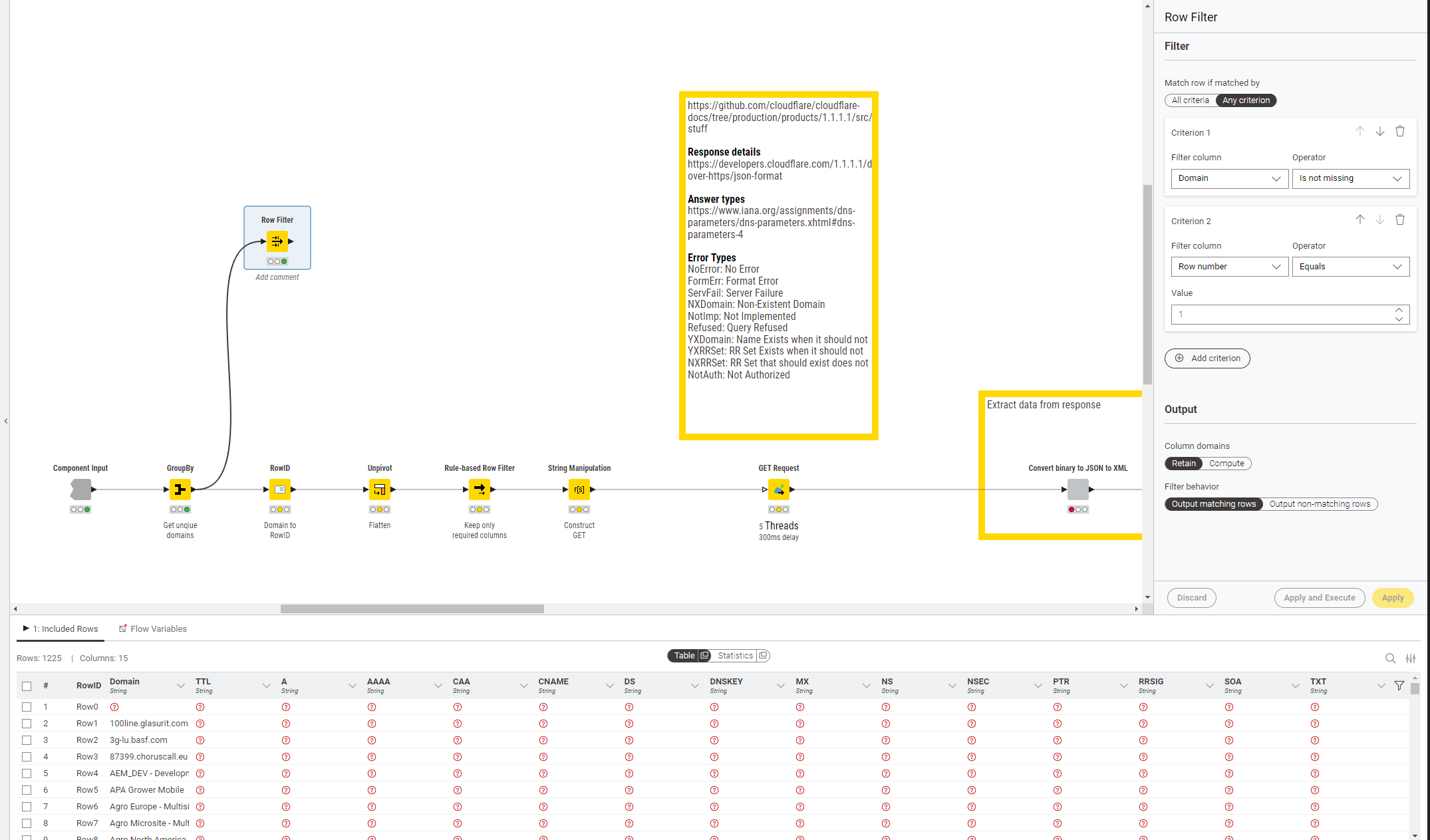
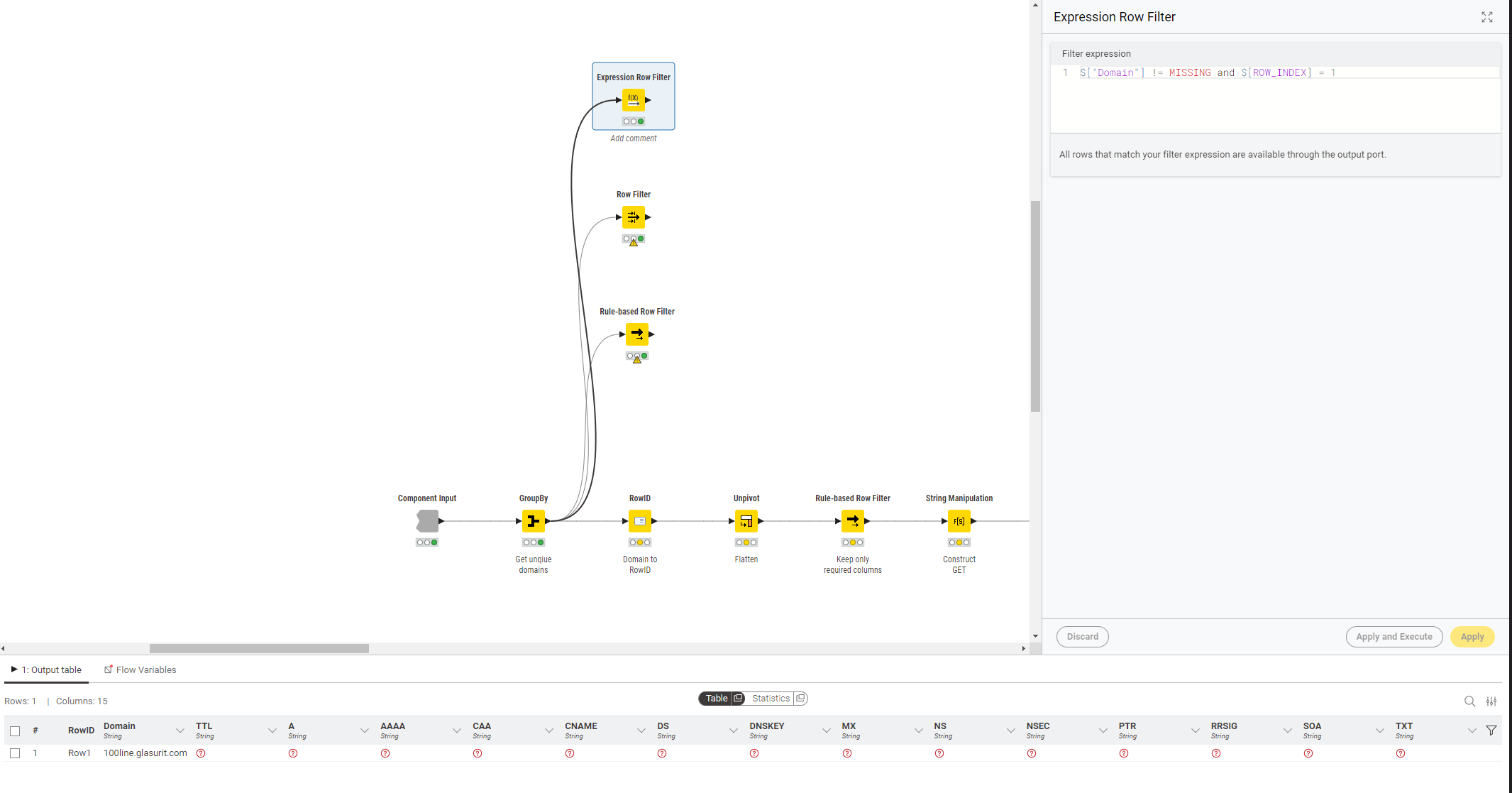
In your example, you chose Any criterion: the first row of the output is returned because of Criterion 2, all the other rows are returned because their Domain is not missing. If you include a second row with a missing Domain, you will find it will be filtered out.
Regarding the “boundary” filtering, we are planning to (re-)offer the “Between” operator that has two input fields to specify the range. This should make some combinations with OR possible that are currently not (since you need the AND to combine the “boundary”).
Thanks for the clarification. I believe the “simplicity” of the new row filter encourages to chain filters and, as brains work, apply rules differently. I saw the table with a missing value and created the filter to remove than and then return the first row.
Though, this is idea or the UI misleading as the temporary results (it’s row index / number), after the first rule was applied, is not recalculated.
I was playing around and just followed my thoughts as if I’d be a newbee or someone trying to test the boundaries.
The new Expression Row Filter I checked as well and found it … not quite there yet. It contains functions to transform, which could be helpful but is rather misleading. It seems to lack the option to negate compared to the rule engine row filter “NOT” and the usability is, not quite comfortable. Sorry for the bashing of the node but it did not convince me the slightest. Waiting for the 5.4 release to open a ticket for the feedback.
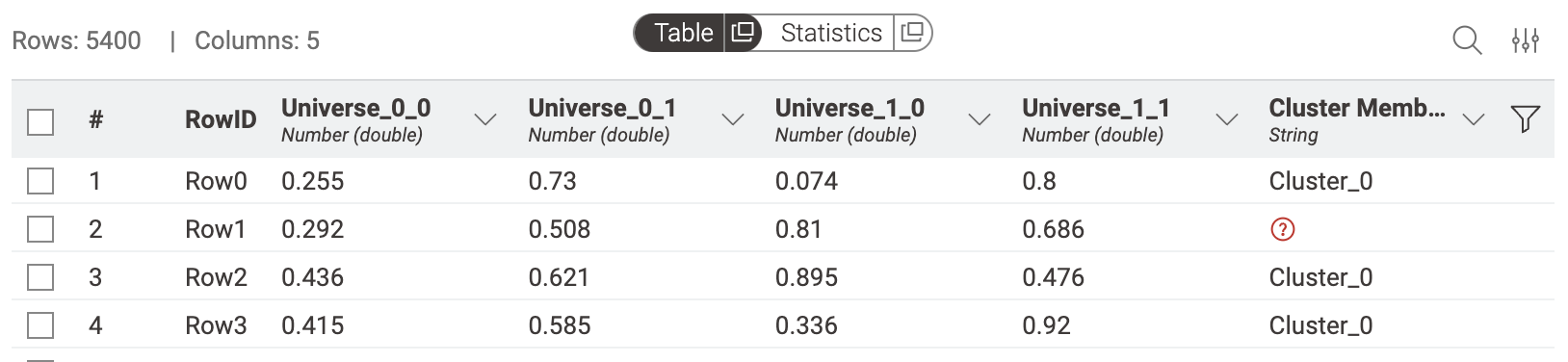
PS: The New Expression Row Filter node exactly yields the expected results Cross verifying that with the rule based row filter, which “fails” expectably since “one line equals one statement” (or as you wrote “in a bag”)
Quite an interesting result as one would expect the same outcome, wouldn’t you?
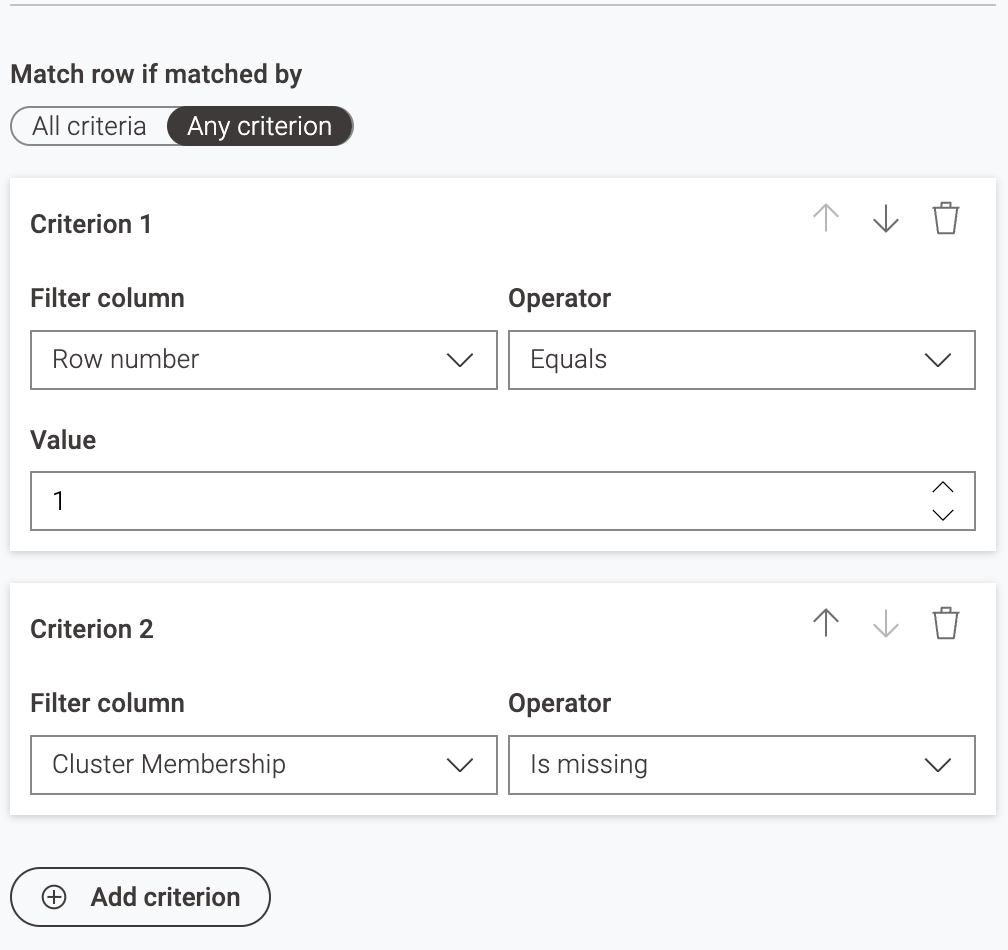
Your Row Filter connects both criteria via “any criterion” → logical OR and your Expression Row Filter does so via logical AND, which would correspond to “all criteria” in the Row Filter.
You are right, I got confused on the any-option Though, the initial example still might be unclear to the user because, after the first filter got applied, the first row should be the former row no. 2 but no result is returned as the row number, for the interim result, is not regenerated.
The point I want to make is that the logic applied in my head, implied by the new Row filter UI, results in a disconnect between thoughts and results. Can you follow me?
I understand what you mean. The Row Filter as it is acts as one expression that operates only on the input data and not on any intermediate results. With this semantic, you can easily create your scenario by chaining two nodes, making the evaluation explicit and visual. With your proposal, you have to know that this is the case – it’s more implicit and less visual.
I now better understand what you meant @mwiegand , but I don’t think the idea of the filters acting sequentially in the way you describe would ever have occurred to me. It’s odd isn’t it how easy it is to have a completely different take on something.
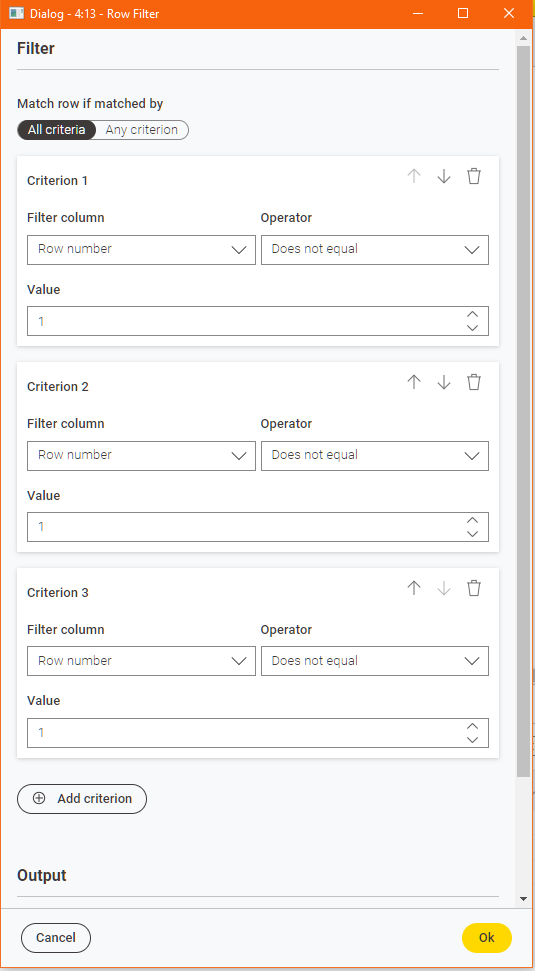
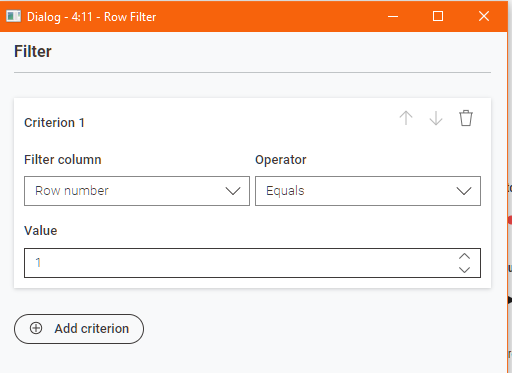
In your suggested scenario, the following would result in the removal of the first three rows:
whereas in reality, conditions 2 and 3 are merely repeats of the first and are redundant.
It would get “interesting” if you wanted to retain rows within boundaries, which is what you mentioned earlier. Say you wish to retain only rows between row number 10 and 30, you’d either have to do the mathematics in your head and configure it as:
Yepp. Maybe my “simple minded” approach was to, instead of chaining like I’d have done using the deprecated Row Filter, replicate it using the new Row Filter. At least that was what I thought the “UI promise” of the new Row Filter is/was.
I really tried to approach it from the most simplistic angle based on the existing and learned experience. I wonder if that point of view, trying to replicate / consolidate an existing approach by combining multiple row filter into one is simply wrong.
well, I’d say that whilst I didn’t think of it the same way you did, I would doubt that you are alone in your reasoning. So if a visual metaphor in, say Expressions node (where actions are sequential) leads you to think that a similar layout in the Row Filter is therefore also sequential, then I can understand how that could happen.
I’m not sure what the solution to that is though.
Maybe it doesn’t help (and I only just noticed this!) that the panel that says “Match row if matched by All Criteria/Any criterion” only appears when you create a second condition:
I think the UI could be understood in two ways when “All criteria” is chosen:
Criteria 1 AND Criteria 2
Criteria 1 AND THEN Criteria 2
The “Then” is based on the assumption that, like when chaining the now deprecated row filter, after one rule got applied an interim result is generated. But that doesn’t seem to be the case and makes me wonder why not.
As an effect you’d be required to chain the new row filter but that would, kind of, invalidate the purpose of the new row filter node, wouldn’t it?
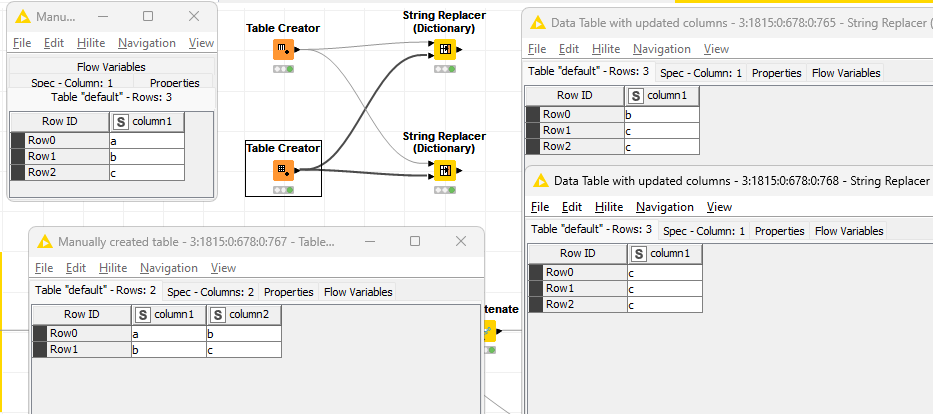
That’s why I suggest to consider this scenario. Eventually the word “sequentially” is appropriate or even misleading. I had the String Replace (Dictionary) in mind that offers to continue replacing considering the interims results.
Like here where in the second example sequential processing is enabled and a becomes b and then c.
Though, with the login from the new Row Filter, that would not work. Hence, my suggestion of “sequential” fully utilize the new Row Filter to it’s full potential.
I can see that in a String Replacer, the order of replacements would have an effect, because it isn’t commutative, but I don’t view the Row Filter in the same way. The Row Filters are based on “set intersection” and this is commutative so it doesn’t matter how a series of intersections are applied, nor in what order; the resultant set should be the same.
I’m assuming here that filters don’t include Row Numbers. Row Numbers are not an attribute of the set, and would get “reset” if dealing with intermediate results, which would make them unpredictable if we could not assume they applied to the original data set, but instead varied with every condition applied.
I cannot think of an example (other than the aforementioned Row Numbers) where the result of “All Criteria” would be different if you had 4 conditions in a single Row Filter or each of those same conditions being chained sequentially (with “interim results”) in 4 individual Row Filter nodes?
Each filter gives the result of a condition applied to a dataset, which in set terms is the intersection of the dataset with a set that matches the stated condition.
It shouldn’t matter whether we chain the intersections sequentially or whether we find the intersection of all the intersections; the result will be the same.
i.e. the intersection of all conditions applied to the input dataset X:
It seems to me that that @mwiegand is looking to be able to apply filters in a series as well as writing multi-criteria expressions. I expected to see series filter support in the Expressions Row Filter as well since it is now in the Expressions node. Perhaps they will incorporate it in the row filter once they dial in the Expressions node?
Hopefully the filter function will be added to the Expressions node itself with bypass switches which would give us step by step filter / review along with a ton of other benefits.
Ah yes, I can envisage filtering being more overtly "in series’ when/if it is possible to preview the intermediate set, as a means of finding all the required conditions. So as a usability feature
But my point is that the final result is unaffected.
The three conditions
occupation=“actor” and firstname=“Tom” and age>55
Yields the same resultset regardless of the order of the conditions and regardless of whether the conditions are
(1)all applied to the input data set and then the intersection of their respective results is returned, or
(2) if each condition acts only on the output of the previous condition.
(Assuming “all criteria” is selected… For “any criterion” there would be a difference in outcome)
I agree. I don’t really see series / step filtering making a difference either in isolation of just filtering rows. However, when it comes to inclusion of filtering steps between data manipulation equations in the Expression node (with the ability to bypass) I think it becomes extremely powerful. Focusing the output review on target rows, simple reordering of filters within a series of data prep equations, trouble shooting by using bypass, reduced number of nodes to perform complex data manipulation steps.
@iCFO and @mwiegand, I do like the idea of being able to preview the resultset between conditions. I can see that having some real benefits when it comes to trying to sift through the weeds, so if that’s the direction of travel for this topic, I am in agreement that it would be very useful.
In the meantime, I thought I’d make a diagram of my understanding of ALL criteria versus ANY criterion in the new Row Filter and how it would compare with using individual Row Filters. Who knows, it may be useful to others