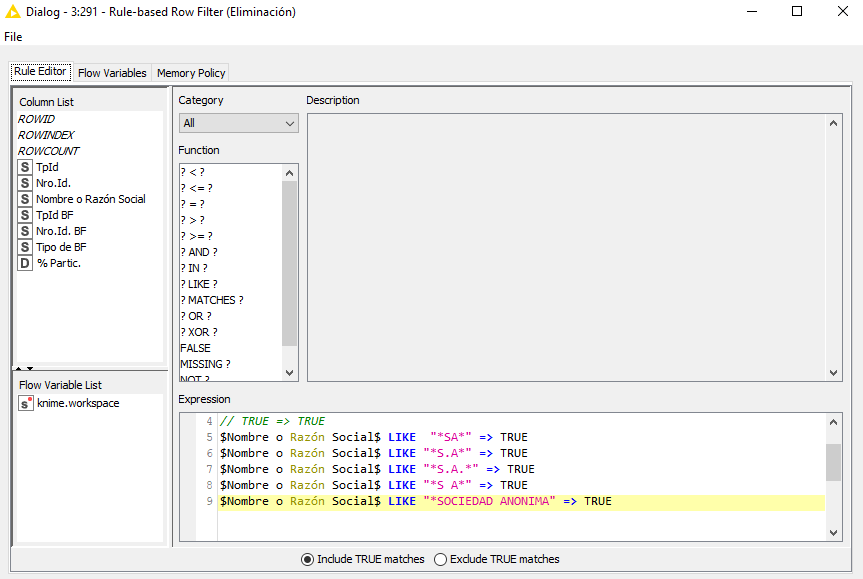
I have a column in a table with customers names which I need to filter based in words contained in part of their names (for example “S.A.”, “SA”, “S A”). I have tried with the Rule Based Row Filter node like this:
Unfortunately, it doesn’t work because I need only the specific word as I wrote it in the node, an exactly coincidence. The result shows me names that contain partial coincidence like S.A.S. or SAS which are other kind of custumers, even any name that contain SA inside (for example “SALES”).
In fact SALES is part of true as it is presented.
Apologies if it will sound a little simplistic, why do not include a Blank space in the position you want.
FOR ex : “* SA *”
As you are preseting the problem i think will do the job
Actually, just after open the forum, I tried another option putting only one “*” at the beginnig of the word and it works. However, I would like to find and easy way to do it, because at the end what I need It’s to clasified the costumers by the abbreviations at the end of their names, for example if the name contains de abbreviation “SA” “S A” “S.A.” or “S.A” assing the kind of enterpraise “ANONIMUS SOCIETY”, I mean that based in a determined group of abbreviations create a new column with the meaning.
Thanks a lot, but I just realized that the abbreviations can be not only at the end of the customers names, but they could be after one or two words (for example GOOGLE SA ANALYTICS), so if I put " *SA" in the rule based row filter node, the result give me this kind of rows (GOOGLE ANALYTICS SA) with the abbreviation only at the end of the name.
Where can I find an explanation about the position of the * or even thing like the one that you suggest me (?i).? Is there any forum or link where I can understand the logic of this characters at the momento of make a text filter? I have seen many similars