I have a workflow where I load a huge amount of data initially from an Oracle DB.
Additionally I want to set up a workflow where I do daily incremental loads of newly added rows.
I have a column called LASTMODIFIEDDATE.
So my idea was to get the max of this column and turn it into a flow variable. Then I use this very flow variable in the DB Row Filter to only send “new rows” to the DB Reader.
Yes, I know, I could basically load the whole DB initial load again and then do filtering in the KNIME table. But I don’t want to do this, because for me it does not make sense to load 100,000s rows of data just to throw 99% of away directly afterwards. I feel that one of the big advantages of KNIME DB nodes is that we can do the data manipulation on DB level (for faster speed and execution).
However, I really don’t know what to put where when it comes to the FlowVariable tab in the DB Row Filter Node.
I have a var called ‘Max(LASTMODIFIEDDATE)’ but where do I put it and where do I tell KNIME which column it should compare to and with which operator.
hm, still not sure, as I really don’t really understand what this WF does.
So I have a one row / one column table that holds the last modified date (let’s call this LastDateTable)
I have my DB connection.
Do I plug in the LastDateTable into the data table input port of the DB Update node? But how do I tell it, that it should only import DB line items that are newer than the date I have in LastDateTable??
Hello !
I think you have to select the rows from the table (with a row filter for example which can be set up with variable to select the values of LastDateTable or Date&Time-based Row filter if the data are in date and time format) then use the DB Merge node.
Do I understand it correctly, that this would happen locally in KNIME?
That’s something I definitely want to avoid. Because it means I always (like every day) have to delete 100s of millions of data points into KNIME (like a full load) and then throw nearly everything away to have the ‘incremental update rows’
My idea was to make this happen on the DB level before I even read the data into KNIME.
I must admit, I looked around an hour on the workflow you provided but I don’t get how it works. Sorry.
I also looked again into the DB Merge / DB Update Workflow but I still don’t get how to set the conditions there? I understand that I can ‘add’ additional rows, e. g. with the DB Merge node, but how do I delete rows that are older than the given date?
It uses very basic SQL commands (and a subquery) to do a selection within the database and not in knime. The green boxes are the actual operation the nodes before try to construct an example.
Maybe you want to create a database example yourself and describe (again) what should happen to the data and what the outcome is.
For me there is still confusion about what should happen and which data is where (KNIME or the database) and if you want to add or delete something.
Thanks a lot @mlauber71 - that was exactly what I was thinking (and should have done in the first place, sry!!! )
I have attached a workflow to this post (disregard the csv reader, it was just to bring my example data into KNIME originally):
So what I have is this:
A (SQLite) DB with 1,000 rows of transactional data and a date column
A table with the same structure than the table in the DB (I basically got this from looking at the workflow that @izaychik63 shared above). This only has one value (2023-05-31) in the date column
What I want to achieve is that I can filter the DB on the database (so BEFORE reading it into KNIME) to only keep rows that are of that date (May 31st, 2023) or newer → this is my condition I have referred to above.
My business case:
I have several workflows that import data from tables from a company database. these range from a few 100,000 datapoints (like 30,000 rows and 20 columns) up to several 100,000,000 datapoints (3 million rows, 150 columns etc).
I have now made an initial load and transformation for the past two years, resulting in csv files (don’t ask me why it has to be csv) up to 2GB big.
This data needs to be updated daily so I want to avoid to always have that full load (last 2 years) and then delete duplicate rows in KNIME. I thought it might make more sense to do this on the database itself (somehow, if possible) because I was assuming this will speed up the workflow. I then read into KNIME only the subset, so basically the rows that have been added since I last read from the database. This of course will be a different time stamp for every execution of the workflow (I planned to store this in a temp .table).
Once this is set up all of these workflows should be scheduled on the KNIME Business Hub (but I want to try it out locally first).
Maybe you take another look at that and try to understand since I think it provides the essential tools. I do not really get what you are doing with the update.
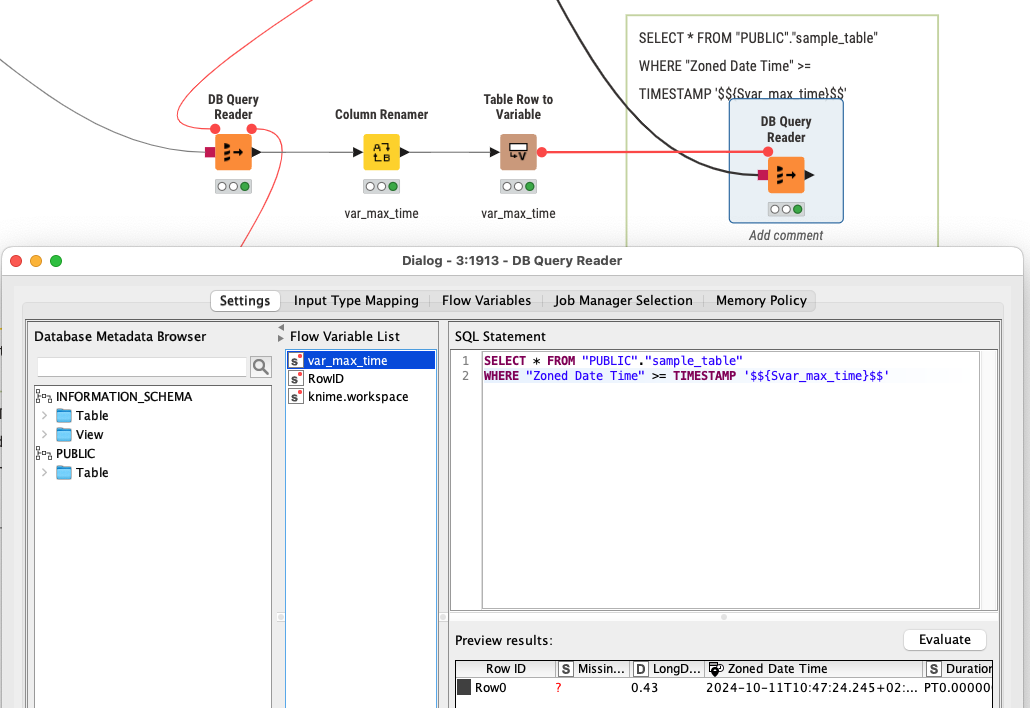
There is a Flow Variable as a date/time there derived from the database (could also be from local KNIME) and this Flow Variable gets used to filter the SQL Query. You will have to adapt the syntax to your specific database dialect.
Also you could try and just use a sub-query to get the latest date/time and then use that. If you want to process the data on your database, SQL might be the best way to go forward.
You can also use some insert functions. Question in a database will always be how to determine a unique key (if you have any) - of course you can base your insert solely on the date if you are sure about what you are doing. I have additional examples of update and insert procedures if that should be the case.
I finally managed to get this working, thanks to you consistency on saying ‘try it again’
So what I basically changed SQLite to H2 (as suggested by you), then I wrote my simple csv transaction table to that H2 DB.
I created an easy table with a column which I turned into a filter flow variable for the SQL code to use.
I also tried this on my real use case (and orignally was having a hard time translating this to the Oracle SQL dialect - but I have figured it out right now). And it works like a charm.
THANK YOU MARKUS ! Just another step in my data journey (and my colleagues will be amazed what I can do hahaha)
For anyone reading this in the future, you can find the (updated) WF here: