Hi all, new to Knime and exited to dive deep into a project.
I’ve tried searching for this online but cannot find a solution to my particular question.
I’ve got a huge dataset that I want to show only rows with a specific keywords. Words like “pole” but with different variation of it like “pl”, “poles”, “pole”, “p”. And whatever the preceding number is following those key words. So for example “pl09” or “pole15” or “pole 19”. Also, It’s not case sensitive.
Thanks all
It would be helpful if you could upload some sample data for us to work with. In the meantime you might take a look at these example workflows involving string similarity:
My first instinct for problems like this is to use Regex.
I do have a question though:
Do you know ahead of time all the possible permutations of your target word? For instance, with pole do you know for certain that only “pl”, “poles”, “pole”, “p” represent pole? If you do, just replace all those instances and then find your numbers.
If you don’t know, then regex can help.
Regex (regular expressions) find patterns you specify using a mini language.
Here are various examples of regex in KNIME:
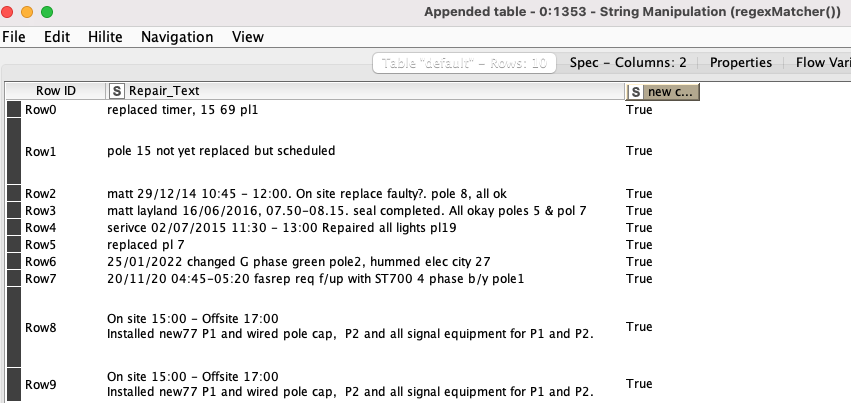
For your case, use the string manipulation node with the regexMatcher function like so:
In English:
(?i) - ignore the case
[\\s\\S]* - find anything (ignore line breaks)
(pol|pl)[\\s\\S]* - find pol followed by anything (like pol or pole) OR pl followed by anything (like pl9 or pl 9)
Notice this will also find things like “police man” for instance. You will need to write more refined regex if you encounter these false positives, but for the example you gave me, this works perfectly:
Hi Victor, I do not know what the input would be as it’s randomly written in by the user. Thank you for the answer!! It works well and is exactly what I was after!