I know there’s a solution here, that it is probably a simple solution, but my brain is old and inflexible and apparently not able to come up with one. My apologies in advance.
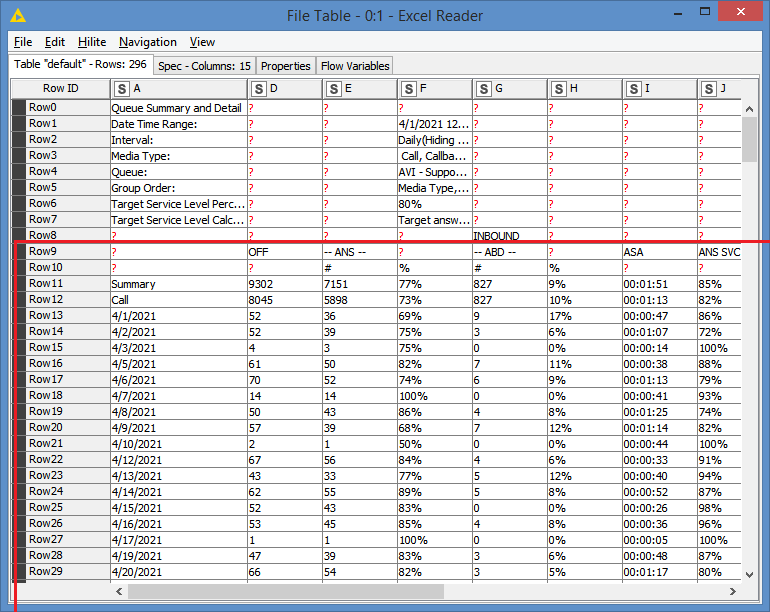
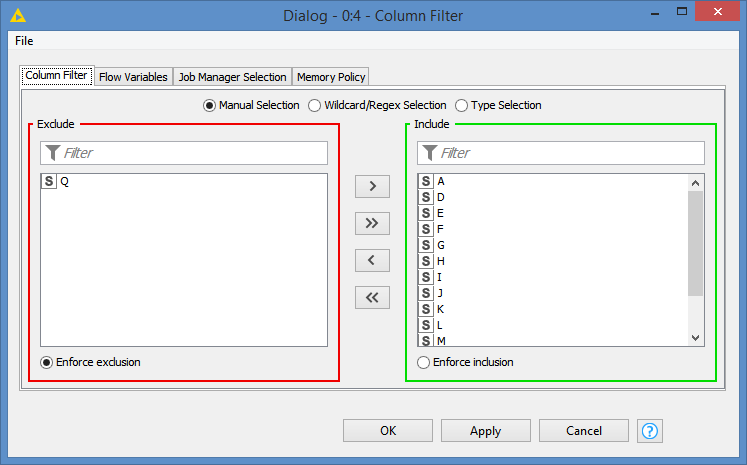
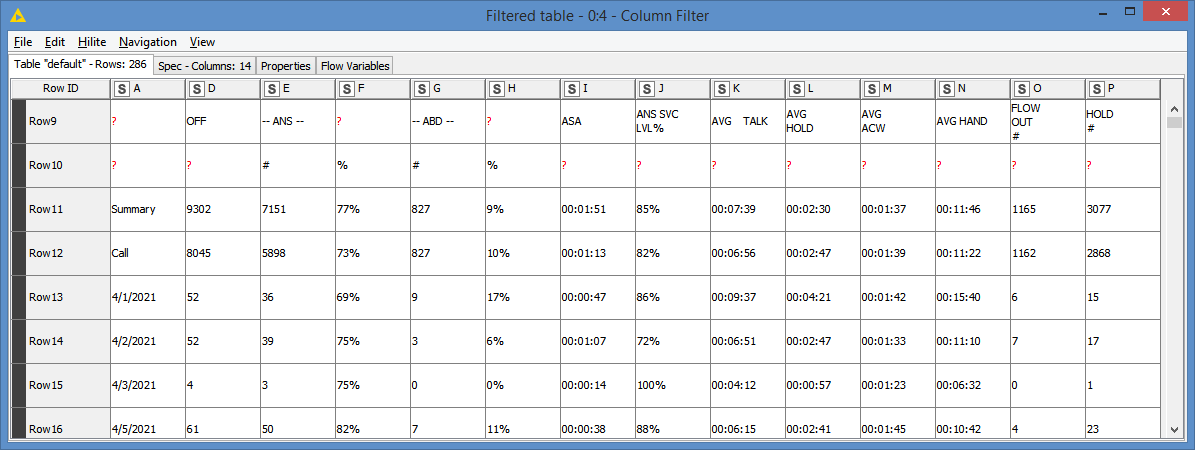
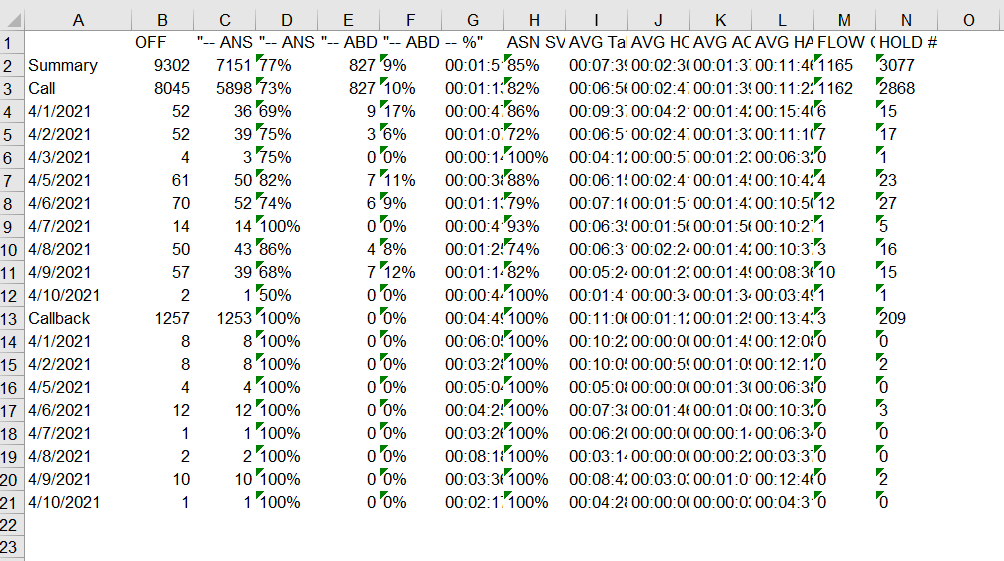
I’m working with phone metrics data using end of day intervals. The data itself comes in ugly formatted spreadsheets, and I figured out how to clean that up to a point. Once the bulk of the cleaning is done and extraneous rows and columns jettisoned, I’m left with a split table that effectively consists of “column headers” and “the data.”
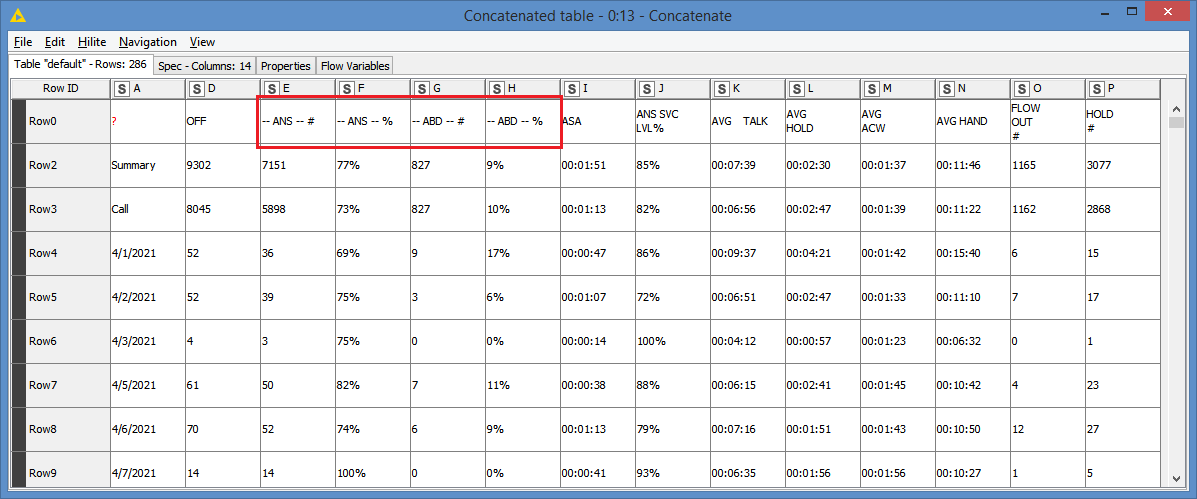
The “column headers” bit consists of two rows with some strings and some empty cells. I’d like to merge the rows and combine/concatenate the strings where there are strings. So if A1 is “ANS” and A2 is “%” I’d like the new A1 to be “ANS %”. The Concatenate node seems to just re-combine split rows, and my old inelastic brain hasn’t been able to properly google a solution.
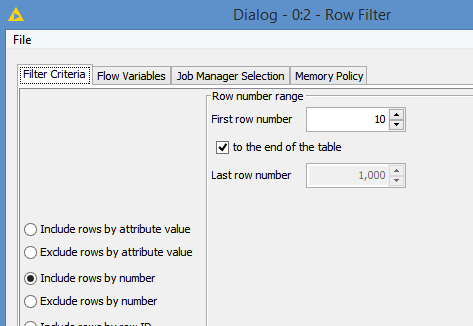
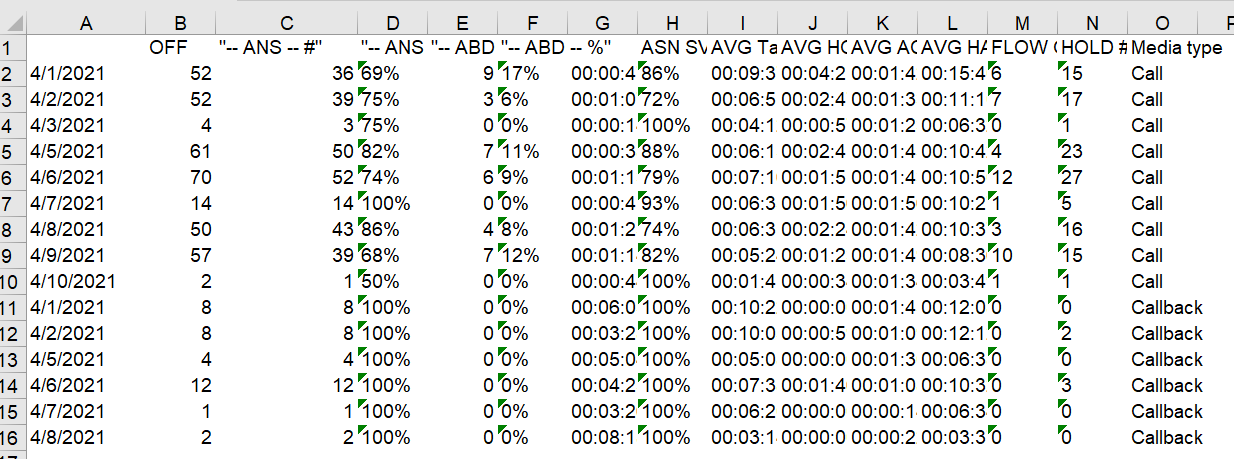
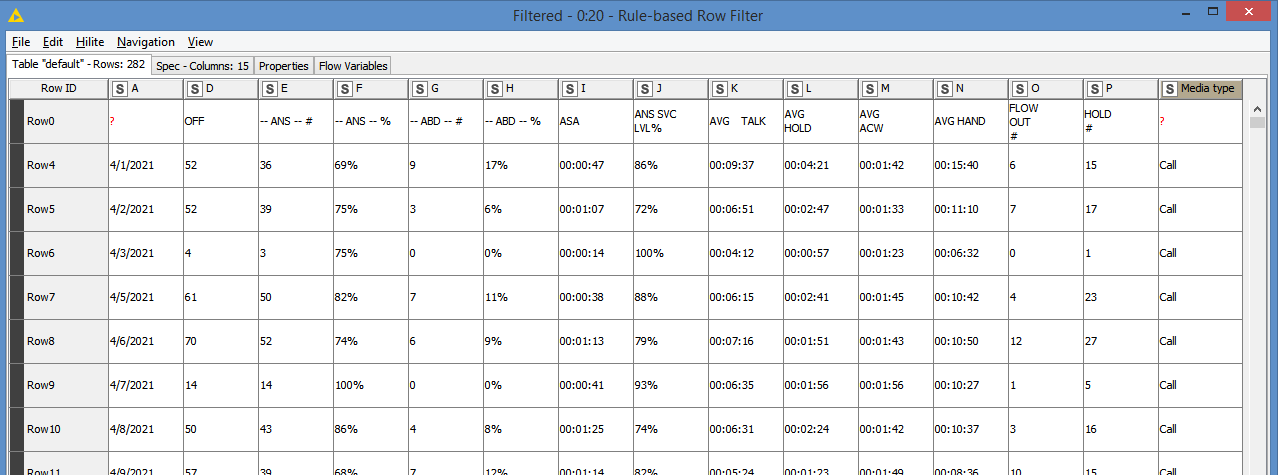
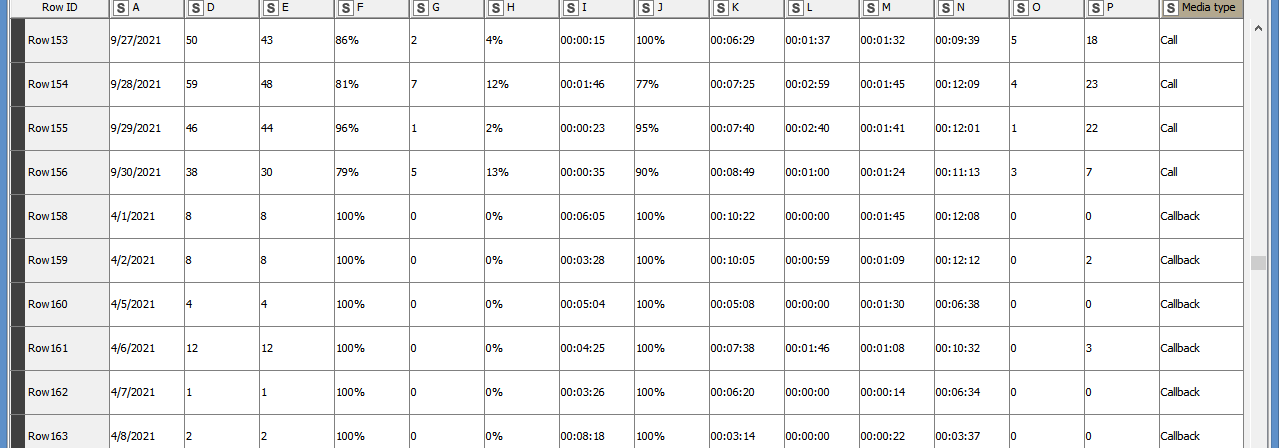
“The data” potion of the of the tables also has me stumped. This table has a summary row, followed by a sub-summary row for a media type, followed by dates with call data. I’d like to remove the summary and sub-summary rows (I could probably do that with a row-splitter node), but add the media type as a new column for each date to each row it applies to (since it’ll only reply to rows that follow the sub-summary row in sequence). That last bit is where I’m stuck.
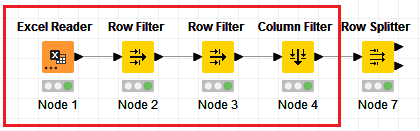
I’ve copied my a workflow here with some data if people want to poke around. But even more than a solution (which I’ll need eventually), I’ve been poking around resources for data cleaning and transformation and maybe I just haven’t happened on the right example or tutorial yet.
Again, apologies, this should be something I can figure out and maybe after typing it all out my brain will decide to start working.
ICBM-Queue-Data-Clean.knwf (83.2 KB)