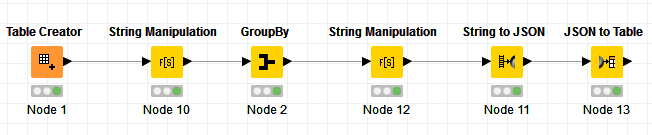
I am going to transfer some biological data from rows to columns. So, as you can see what I’m going to do is to transfer the contents in “interaction-type” column to independent columns and then create columns for the interacting residues like:
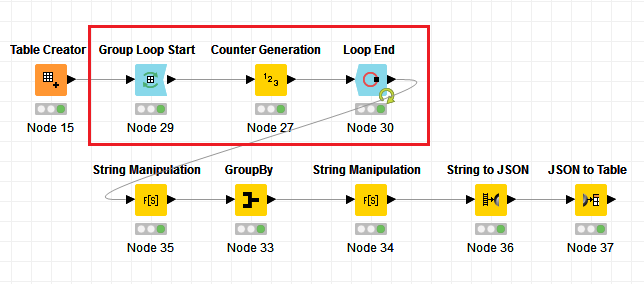
you need separate branches as you are performing two different operations which need to be brought together eventually. One branch needs One to Many node and another simple pivoting. Finally you have to use some table manipulator nodes to get column names/order as desired… 2021_03_18_OnetoManyPlusPivoting_ipazin.knwf (57.4 KB)
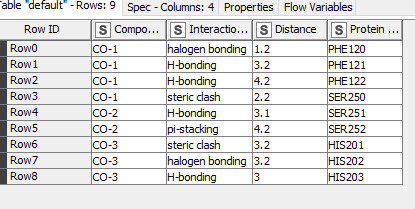
Hi @naraj , since we can’t know how many interaction-type a Compound ID might have, I use JSON to process/manipulate the data, and then convert back to columns. I also built the workflow so that it’s dynamic and not hardcoded with the interaction-type, as I do not know if you may have other interaction-types, so it will automatically adapt to any interaction-type you have (or if you add more in the future).
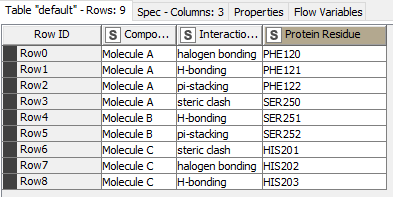
In my data sets, some of molecules have more than one H-bonding interaction (or pi-stacking and etc., see attached). I want to add all the similar interactions of a molecule in one row (so one molecule can for example have three H-bonding interactions in one row). Is there any node to do this job? Currently, the “group by” node consider only one Molecule and eliminates the other similar interactions.
Note: If you want the columns order to be different, you can do the sorting on the data somewhere between Node 30 and Node 33 (so before or after Node 35)