What would the workflow look like if a needed to filter based on an “if” function? Let me explain…
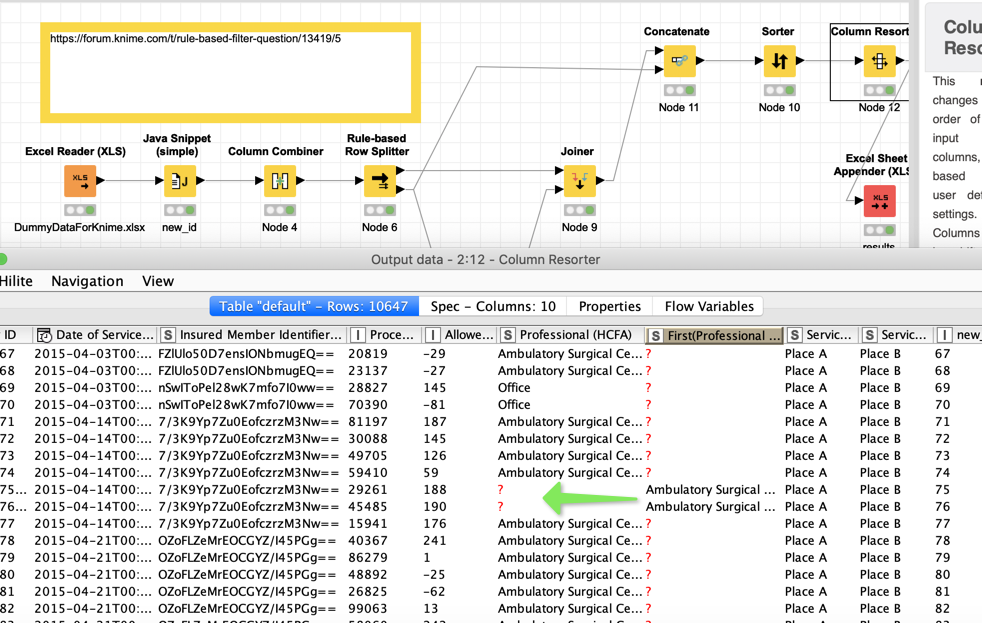
My data file has many columns, one of the columns is professional, it indicates the place of service (i.e., where a person had there procedure performed). The issue is, however, this column is not always populated when it should be - meaning it is blank sometimes. What I need to do is create a workflow that says if this patient had any work done at an ambulatory surgical center, pull all the data associated with it - even if the professional column is not populated.
I can’t do a simple row filter for just ASCs as this would emit data that pertains to a patient if the professional column is blank. Likewise, can’t do a row filter for blanks as often the blanks are associated with other facilities, like hospitals. I have attached some dummy data - any help would be greatly appreciated. Rows 73-78 give a perfect example of the issue I face, same patient ID - professional column not populated for all rows.
Do it in to steps. First filter records with Professional column populated then join thous records with the one without data in Professional column on date and patient ID fields.
In general for this task you have to use the encounter number. Could you get one?
I have a “claim number” which is similar to an encounter number, but I am not sure that would work based on how that data reads as there are several levels of claims data.
I think I would need to do a loop to do what you are suggesting. If willing, could you mock one up for me with the data i supplied - loops are very new to me still.
not 100% sure if I caught your problem accurately but how about creating an artificial ID from date, procedure ID and the Place Informations and use that to fill in the gaps, assuming the missing lines would have been done at the same combination of places (or whatever ID combination would be there) at that date.
Of course this only works if there is at least one entry per procedure with the correct information. Another possibility would be to see if one could ‘fingerprint’ the procedure place so that even without the correct name being there the combination of characteristics would still identify the professional column.
I want to look closely at the solution you have proposed, at first glance, it looks like it should work.
You have me very intrigued with the idea of fingerprinting. How would this work for my dataset? I could see this idea being very practical considering how messy the actual data set is. If your willing, can you explain more about this and how one would do it?
The idea of fingerprinting in data is that if you do not have a unique ID you create your own from various features of your data.
Classic example would be you have customers but no customer ID. You would take
name, surname
adress
area code
phone number
…
and combine them. You could do several variations like only using the first 5 characters of a name and ‘clean’ it by removing special characters or even using a phonetic extraction to counter various styles of writing. Or from an address you extract the numbers and remove special extensions. For example you have (a german address)
since this would be the ‘major’ component of the entry distinguishing it from everything else. Next component the area code
50331
50330
5033
=> just use 503 since you would expect most people to get the first part right. The same with dates of birth
1990-11-07
1990-11-01
Nov 1990 7th
=> maybe just use 1990-11 without the date or just the month if this would be bring enough distinction
haupt 11-503-1990-11
might be pretty unique (depending on your data) and you have a good chance of capturing typos and various spellings. If your data is relatively clean you could just throw several items together like in the example and use them. You have to do a few tests und decide which approach you like.
Actually there are several blog entries in KNIME about this and I also created a small workflow to compare strings. KNIME provides you with several nodes to help you with this task.
(the title is misleading since the question about addresses was added to another topic but the links there should work)
In this particular case I’d recommend to stick with medical practice logic based on CPT codes and claim numbers/encounters. The solution will be the same as with artificial key but based on natural one.