Hello,
I’m looking for a way to replace different cell content using Rule engine or other solutions if possible ?
Thank you
Hello,
I’m looking for a way to replace different cell content using Rule engine or other solutions if possible ?
Thank you
Hi,
You can use Rule Engine node to do that using this structure:
Condition 1 => Result 1
Condition 2 => Result 2
…
Any other condition => Result n
E.g.:
$Column1$ = “Some Value” => “New Value”
$Column1$ = “Some Other Value” => “Another New Value”
…
TRUE => “Any Other Value”
Using Rule Engine node you can have only one output column but you can use “Column Expressions” node to have several output columns by defining several expressions (in a bit different syntax from the Rule Engine node) separately.
If you have further questions it would be nice of you to provide a sample dataset and an explanation of what you want to apply, then I can help you more in detail.
Best,
Armin
Thank you for the feedback, It’s more complex.
Here’s an example of my table
Marg
01-AV
09-MR
07-VG
the goal is to look for each two letter and replace them with a predefined value when used String Manipulation it was like this : replace($Marg$,“Mai”,“05”)
I hope it clear
How many key-value set do you have? I mean how many different sets of those words with two letters and the corresponding number do you have?
If there are many of them then you may want to create a dictionary in which you have two columns. The first column containing the letters and the other one for the numbers. Then you can use Rule Engine (Dictionary) to replace them.
P.S. Do you want to replace the whole string with the new value or just the letters?
Which one is your desired output here (assume that AV is 05):
If contains AV => 01-05
If contains AV => 05
I have 12.
I only need to replace the letters.
01-AV will become 01-11 for example
Here is an example workflow for you:
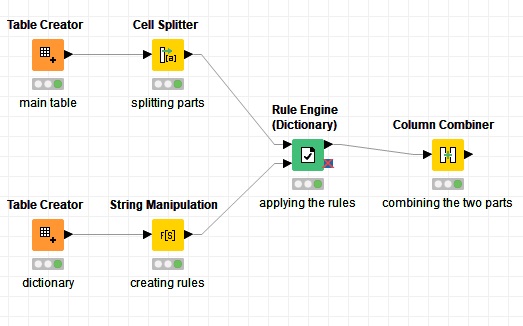
12 is not that high, however I think it’s more convenient to use a dictionary instead of creating all the rules one by one.
Here in this workflow I have a sample dataset as the main table and a dictionary as I mentioned before. The String Manipulation node creates the rules using this expression:
join("$column1_Arr[1]$ = \"", $column1$,"\"")
Where $column1_Arr[1]$ is the column corresponding to the letter part of the string in the main table after splitting (using the Cell Splitter node) and the $column1$ is the column in the dictionary containing the keys (the letters). Then the Rule Engine (Dictionary) applies the rules and the Column Combiner node join the parts together again (using “-” as the delimiter).
Take a look at the workflow and let me know if this what you want:
rule-dictionayr.knwf (28.0 KB)
Best,
Armin
Can I send you an email please ?
Actually I prefer to help here in forum. Is there any particular reason for that?
I wanted to send you what I did, it’s quite not efficient, I’m sure it can be done easily …
To let the community be able to use the discussion here, I think it’s much better that you use a sample data and share your workflow here in forum.
It’s not that I don’t want to help further or share my email, I just want our discussion to be more useful to the community.
But if you still insist to contact privately, you can find me with the same name and username in LinkedIn.
Armin
I understand, thank you for your help.
I have one last question do you know how to delete common value in two colmuns leave only the ones are not common ?
here’s an example : both are sperate tables
C1 V2
X 4
A 2
C 0
C2 V2
X 4
B 9
N 1
Results :
NW-CO V2
B 9
N 1
So you want to have the second table and exclude the rows which are also in the first table, right?
For that you can use the “Reference Row Filter” node.
Best,
Armin
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.