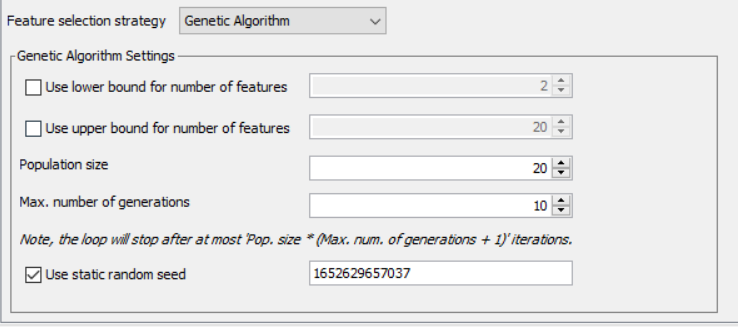
I have a data frame with 50000 rows (each a unique observation) and 2500 columns. I have tried to run a genetic algorithm to perform feature selection with the following settings (please see the image below),
with a SVR using SMOreg. Whenever I ran the nodes, the SMOreg predictor node would always hang around 50%. To try to overcome this problem, I have attempted to create a local big data environment using apache spark. I am not sure I have set up the big data environment properly, and run into a similar issue when running linear regression.
Using Big Data nodes will not help you in this case. The Big Data nodes are not really connected to anything in your example and the local big data environment ist there to test and develop algorithms for (well) big data environments that would provide you with their power. Without such a setting you will just have your local machine.
Then: from my recollection SMOReg is quite a costly algorithm and your data seems to be quite large. Wahr you could try is reduce the size of the data and see if it would work at all in the first place. Also you could check out if you have given your KNIME all the power it might need.
Then you could try and read and test other methods of dimension reduction that are there with KNIME (like removing highly correlated variables).
Then also check this collection under the [preparation] category. I had some good results with R vtreat.