Hi @MollyR , sorry for the delayed reply in between, a bit busy today.
Based on the format you gave, the dates and times are stored as string then. If your datasource have these columns as type date and type time, then I would suggest converting your data to date and time. However, I have a strong feeling that they are stored the same way in your datasource, so that’s the assumption I’m making for my solution.
A MAX() on string usually looks at how alphabetically the column is ordered, and based on the formats you provided, this is perfect.
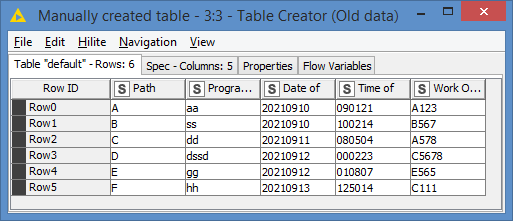
For the sake of my solution, this is what I have as “old data”:
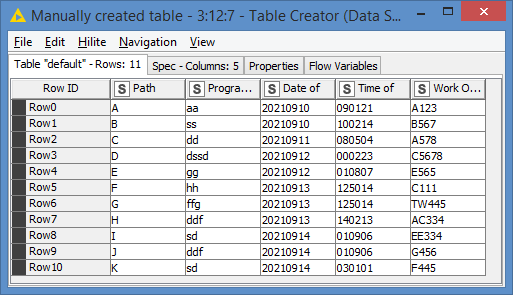
And my datasource is like this:
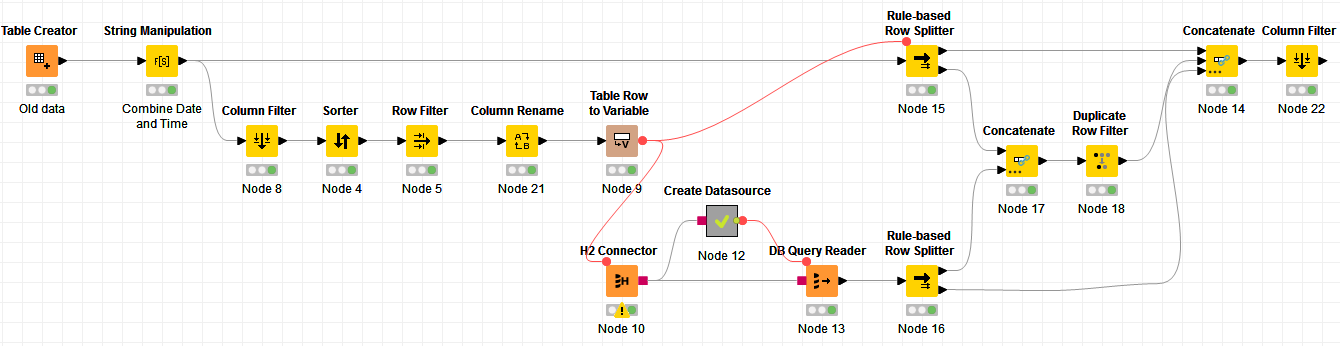
One way to get the MAX of your string date and string time column is to do a sort descending on these 2 columns, and then take the first column. To do this, I want to create a “key” column, which will be the concatenation of the Date and Time Column, called COMBINED_DATETIME. I then column filter only on this key column to save memory and for sorting to be faster. I sort descending and keep only the first row. I then rename the column to Max_DateTime before I convert it to a variable, that way it will create a variable with the name Max_DateTime:
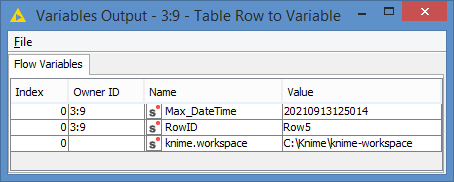
And here’s my variable:
Now, I can retrieve my data based on that variable:
SELECT "Path", "Program Name", "Date of", "Time of", "Work Order Number"
, CONCAT("Date of", "Time of") AS Combined_DateTime
FROM "PUBLIC"."datasource"
WHERE CONCAT("Date of", "Time of") >= $${SMax_DateTime}$$
And this will give me these records:
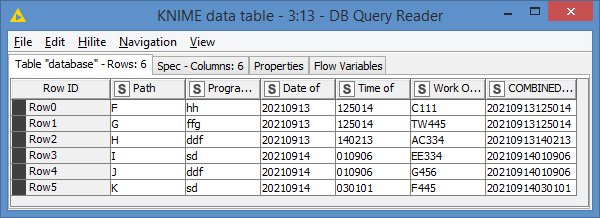
If you look at the first screenshot where we have the “old_data”, we currently have 6 records in the our “old data”, and we’re getting 6 new records from our query, which if we add these 2 sets together, will give us 12 records. However, the second screenshot where we have the datasource, there should be 11 records only. This is expected because we know, as I explained, that there can be duplicates for the exact timestamp that is our starting point of re-ingesting.
We just need to tackle that duplicates.
To do this, I separate the data into 3 parts:
- Data < timestamp of starting point
- Data = timestamp of starting point (where the duplicates will happen, if any)
- Data > timestamp of starting point
I just need to dedupe the dataset #2. Once it’s deduped, I just concatenate all 3 dataset.
We put all these together, and we get this:
Note: In my example, I’m creating a datasource into an H2 virtual (memory) instance. In your case, it can be a different datasource.
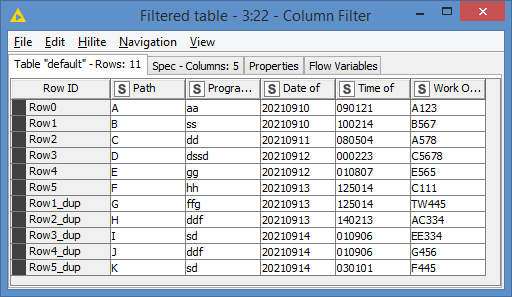
Final results:
Here’s the workflow: Get delta data based on date.knwf (42.4 KB)
EDIT: You can see in the results screenshot that, based on the Row ID column that the first 6 columns (Row0 to Row5) are from the original data, and the rest of the Row ID with *_dup are the additions, effectively added only the new records instead of reprocessing the whole table.