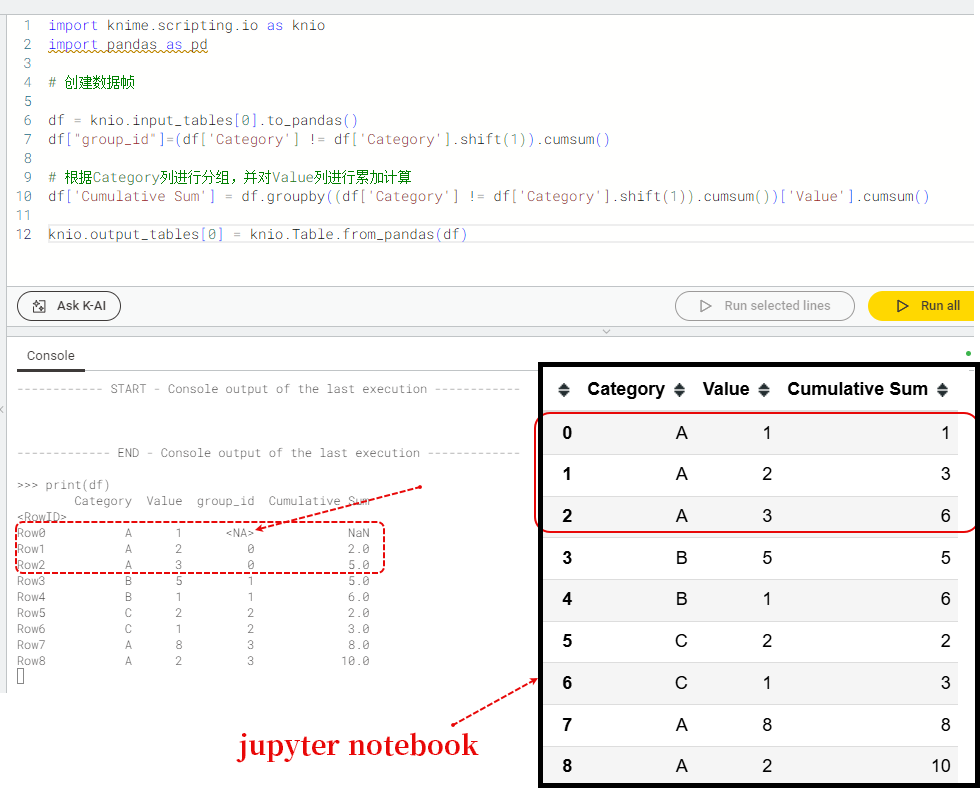
The same Python code produces different output results. I want to implement a cumulative calculation for continuous grouping.
The calculation result in Jupyter notebook is normal, but it is incorrect in the Python Script node. It seems to be caused by missing values when shifting down by one row. Is there any reason for this? Any tips are greatly appreciated.
(python 3.11, KNIME 5.2 )
Could it be that the Python version used in KNIME is inconsistent with the Python version used in Jupyter, resulting in a different default behavior for Pandas.
in the Python Scirpt ,the version is 3.11.6(Python Intergraton Envoriment). it seems something wrong.
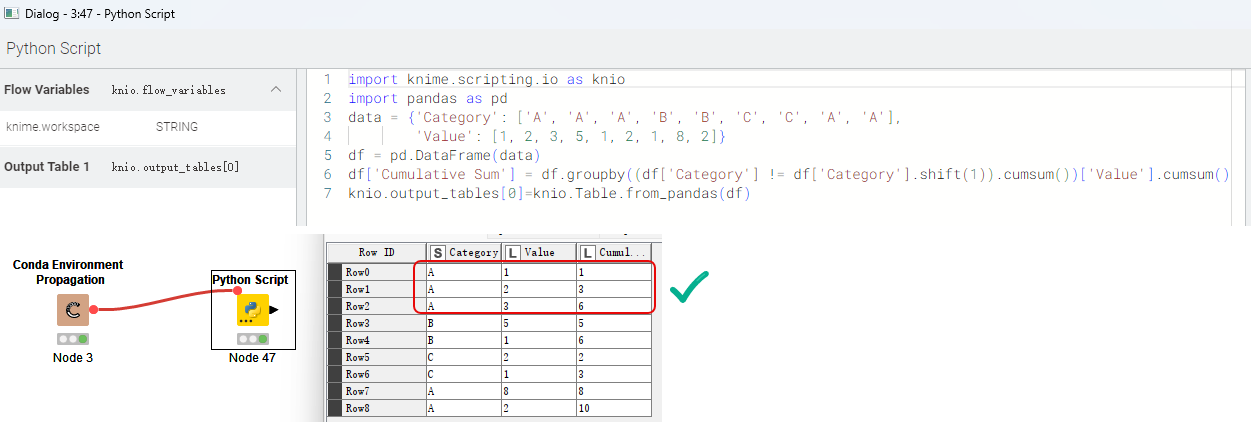
When I use Anaconda to create the a virtual Envoriment that use the same version, then use the virtual Envoriment by Conda Environment Propagation node,re-excute the same code, it’s ok.
it is strange. use same version (python 3.11.6, pandas 2.0.3) except the envoriment, get different result.
I will rephrase the question, as it might not have been clear before.
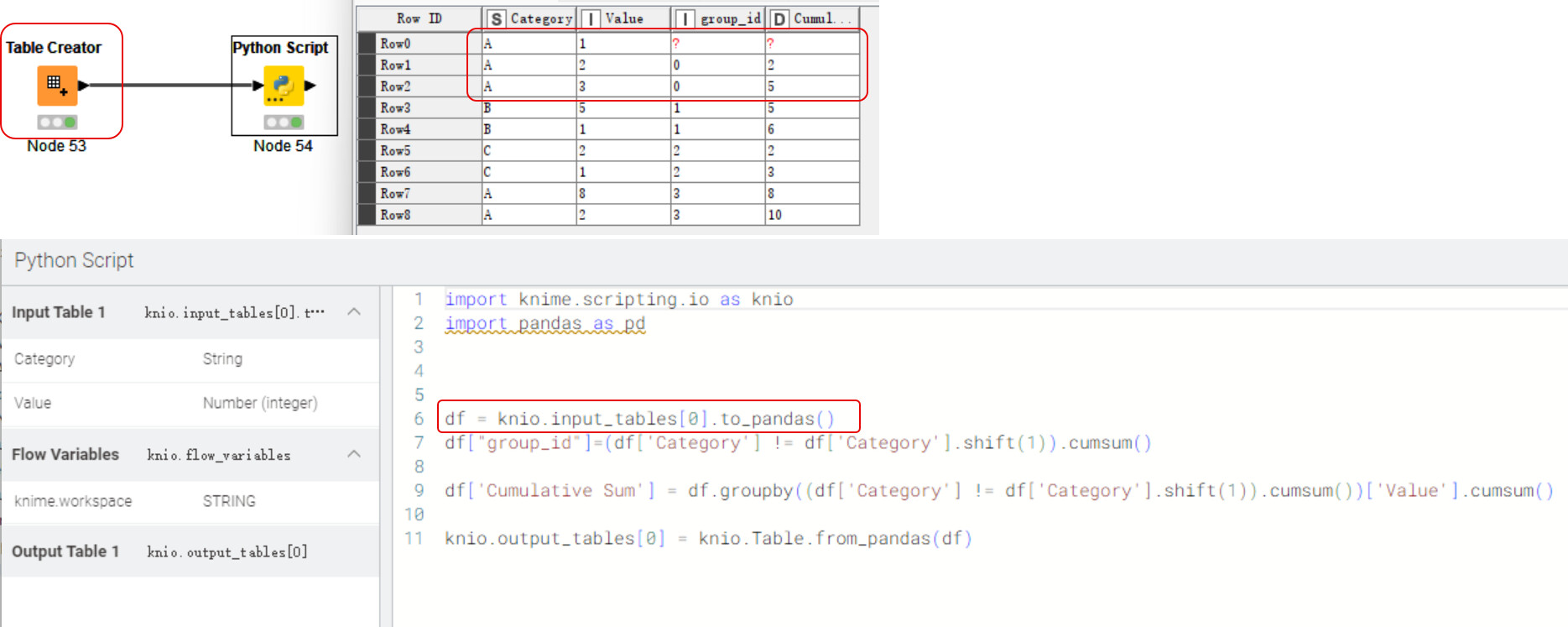
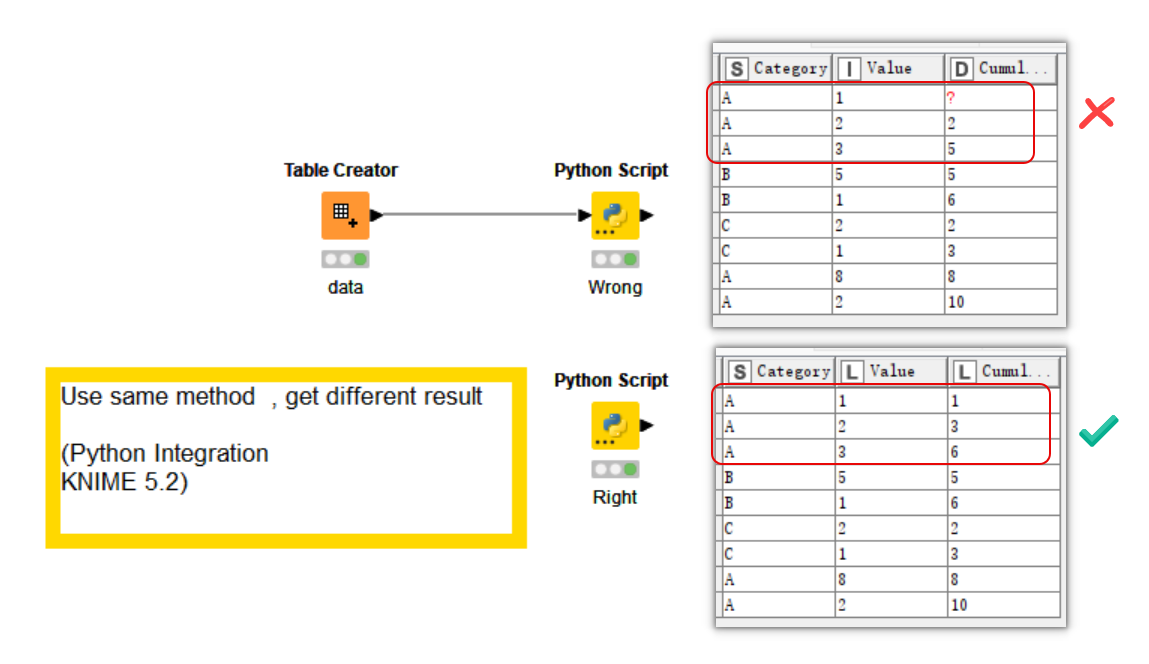
it seems all right when use dictionary to create DataFrame in Python Script. But when you create table by Table Creator,then transfer the data to Python Script, wrong result happends. Maybe Python Script do something to missing value.
So I have to change my code as below,then it works:
import knime.scripting.io as knio
import pandas as pd
df = knio.input_tables[0].to_pandas()
# fill missing value with True
df["group_id"]=(df['Category'] != df['Category'].shift(1)).fillna(True).cumsum()
df['Cumulative Sum'] = df.groupby("group_id")['Value'].cumsum()
knio.output_tables[0] = knio.Table.from_pandas(df)
@kevin_zhao the whole thing is sort of a mystery. Only difference I can find is that initially the column type when coming in from KNIME is int32 while inside the Python node when created via Pandas it is int64. Later changing the type does not change the outcome. So this seems to be some python / pandas problem.