Hi
I have a task to take a sample from datebase.
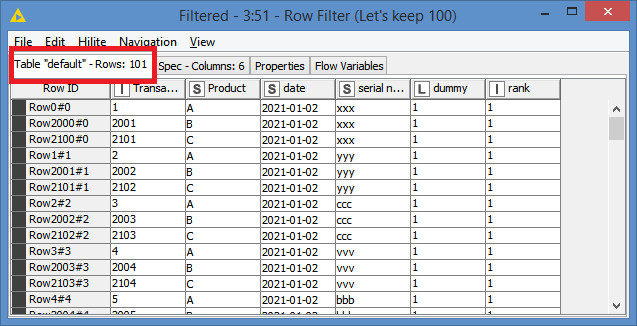
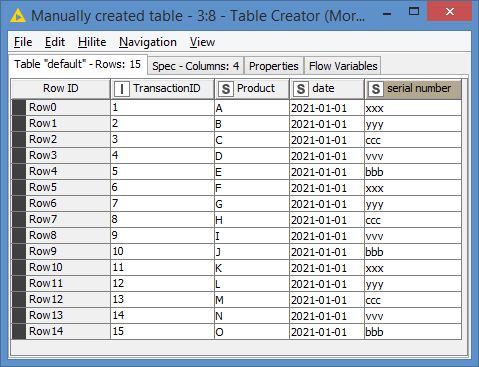
How the datebase look:
Product, date, serial number
A, 2021-01-01,xxx
A, 2021-01-01,yyy
B, 2021-01-01,ccc
C, 2021-01-01,vvv
D, 2021-01-01,bbb
But of course there are more products and diffrent dates.
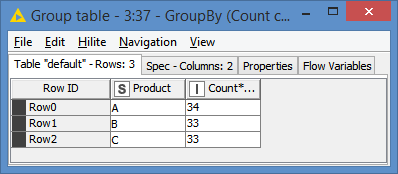
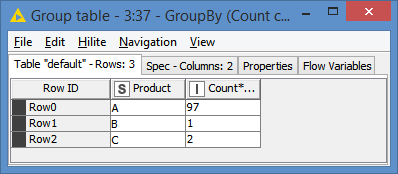
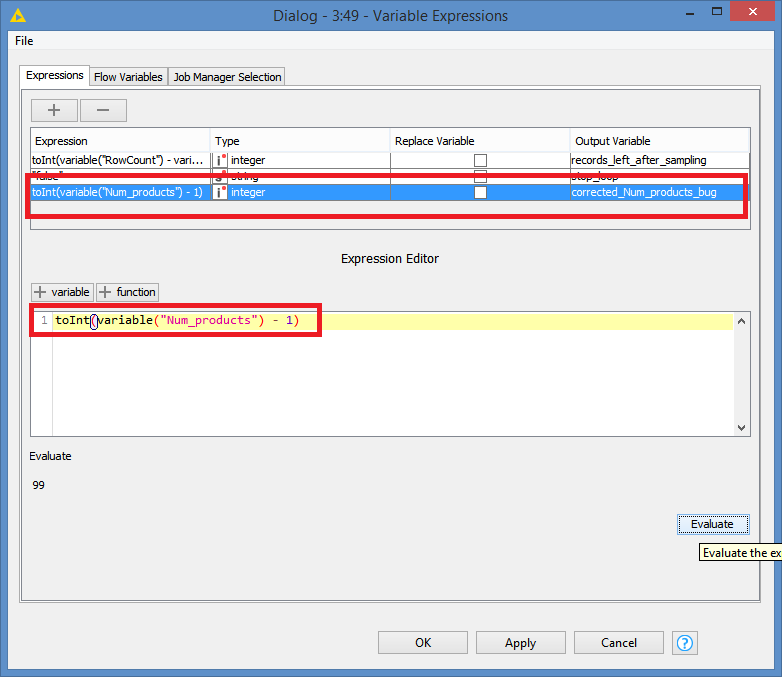
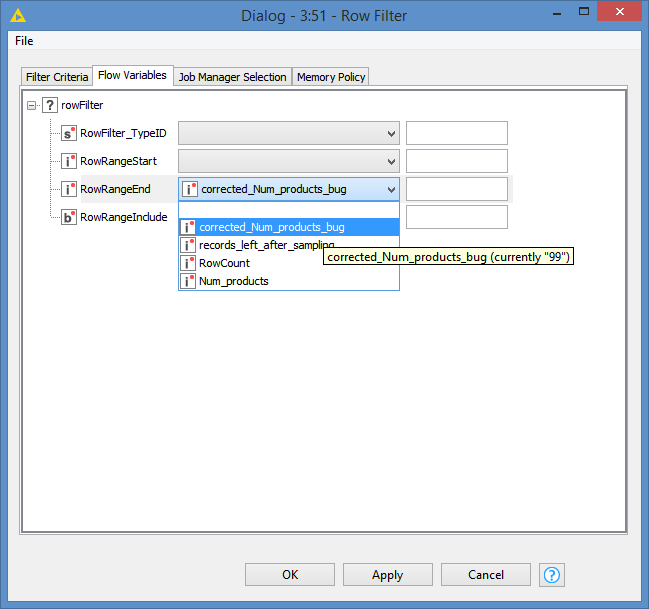
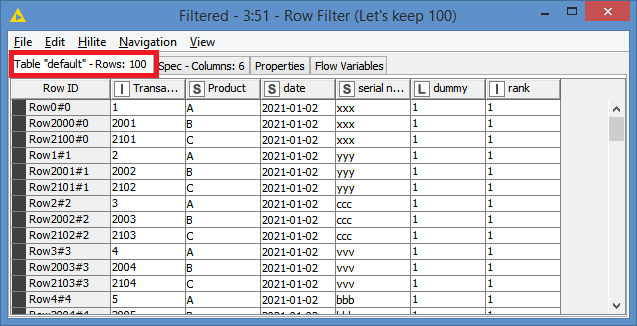
I have to take random sample of 100 records from each day but the condition is that there must be only so many occurences of Products that the sum give me 100. So when in one date there is 100 products (A, B, C…) but 150 records only one of them will be chossen and there wont be duplicates. On The other hand if there are 80 products and 150 records I want to have at least one of each product and the gap (20) should be filled by 20 another random records - without too many duplicates.
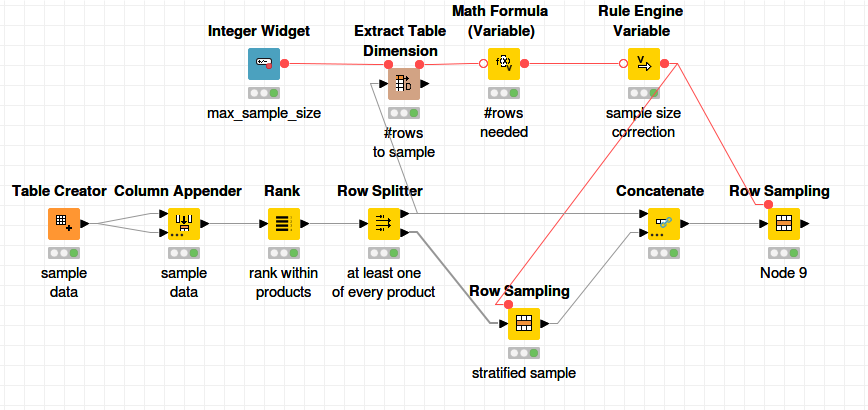
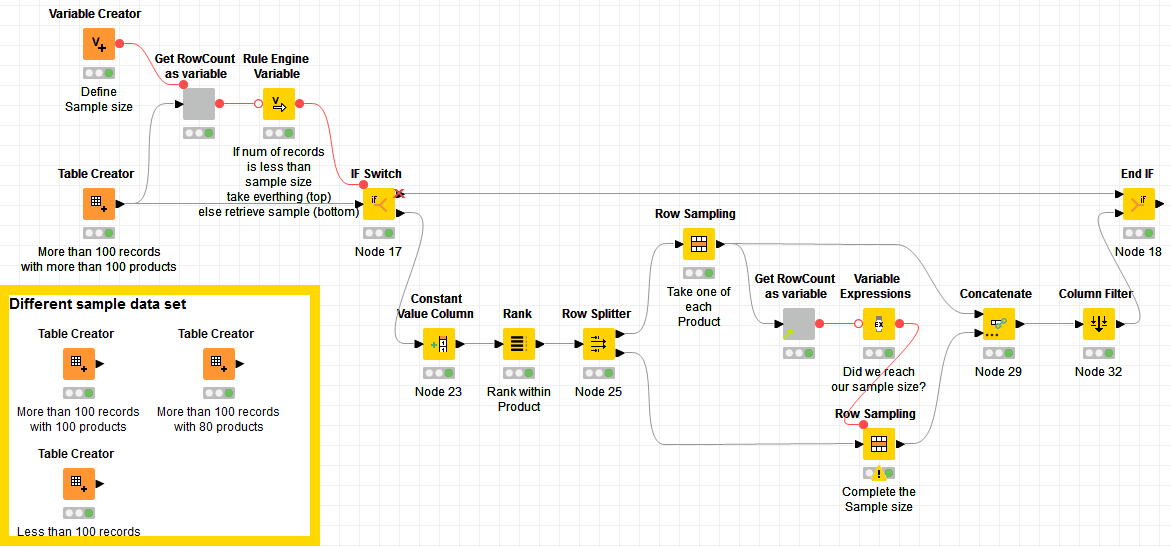
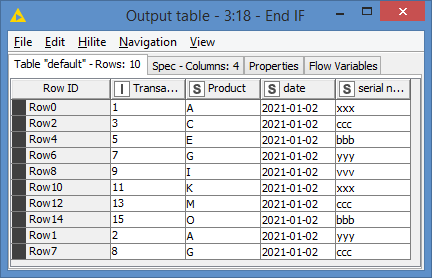
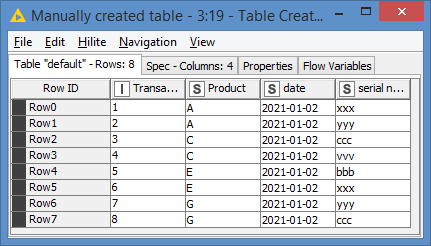
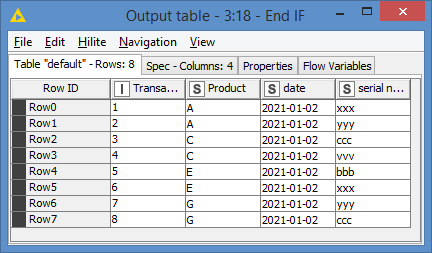
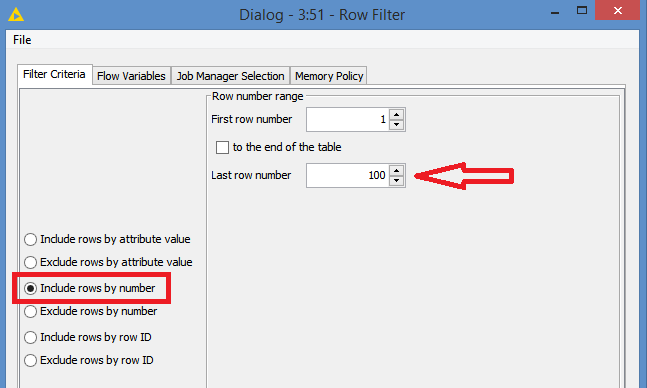
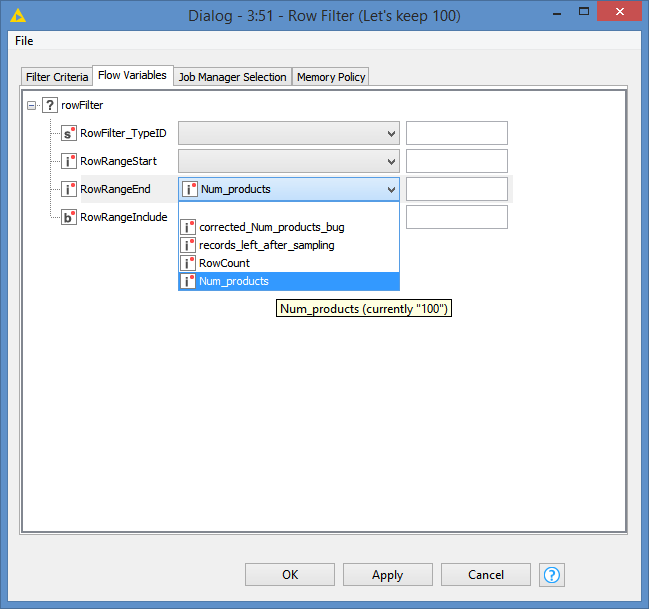
 both ideas doing what they should so Thank You both for your time and help.
both ideas doing what they should so Thank You both for your time and help.