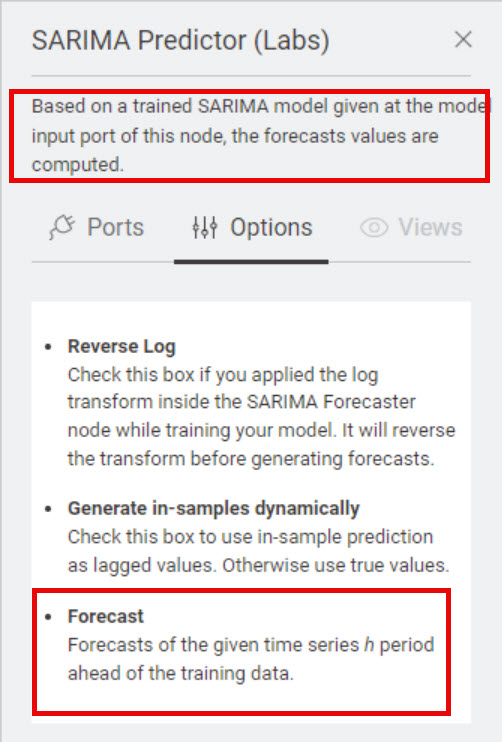
But I am wondering why there is no input-port for the new data? Did I get something wrong? Where can I bring in the new data on which I would like to apply the model on?
Similar Nodes like the “Random Forest Predictor” do have 2 Input-Ports, one for the model, one for the new data. So whys the difference here, how it is supposed to be applied?
Not my area of expertise, but the SARIMA Predictor uses the model created by the Learner and projects it forward the selected number of periods. This works differently than a numeric model.
thank you for your answers and your hints. Unfortunately I still have no clue how to solve this problem.
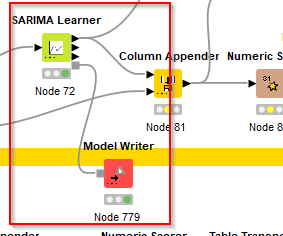
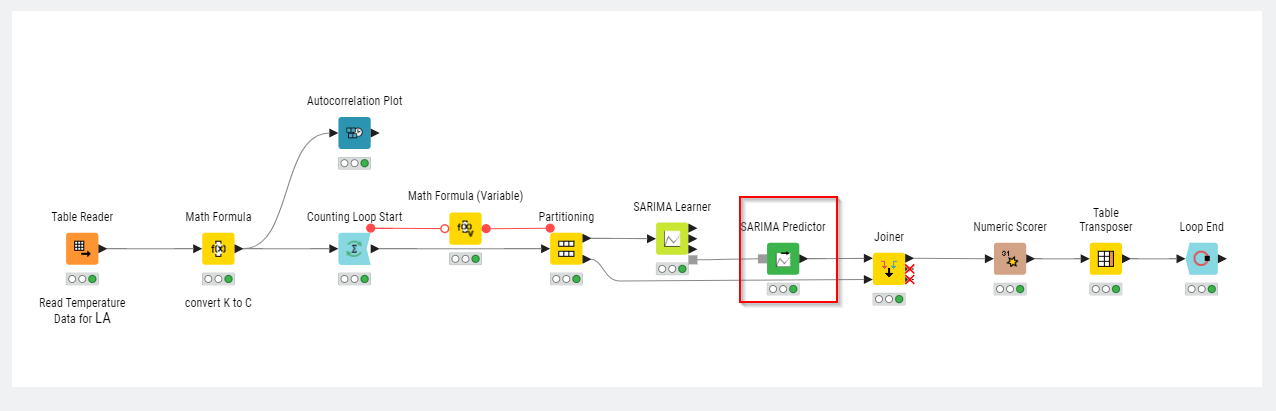
This is a screenshot of my created Workflow with the model which is working fine:
Since I want to apply it on new data, i stored/worte it into my personal folders with the Model writer.
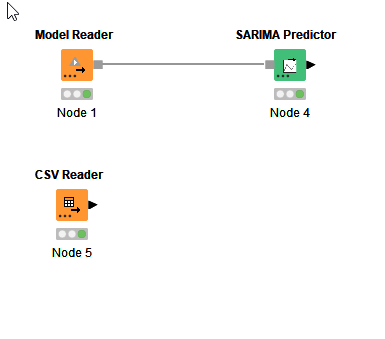
Then I created a new workflow and read the model into it:
As you can see, there is no possibility to apply new data to the created model.
There is something I’m getting wrong since there is no Input-Port for new data in the SARIMA-Predictor. Here s a screenshot of Corey Weisingers Workflow. As you can see, there is no input port for additional data, only for the model:
The way I understand time series and SARIMA is that it picks up on the patterns / seasonality of your training data and then allows you to forecast x periods into the future.
So in comparison to decision trees you are not really applying a model to unseen data…
If you wanted to test how well SARIMA works / want to optimize parameters you may go ahead and train a model only on a portion of your data, then forecast until the end of your available data to then compare. Once happy we with the outcome you then train on all data available and then forecast for the “unknown” future.
I already thought about creating a model with the new data as Plan B. I had the same idea, but just was curious about how it was supposed to be solved in an “professional” way.
Maybe this is already the way it is supposed to be, like you have written, “not applying a model to unseen data in SARIMA”.
And - crossvalidation is included in the model of course.
I wrote the script behind the SARIMA (Labs) nodes. SARIMA models are more of the type of Auto-regressive models. It learns from a regression data, computes the coefficients, and the final equation is use to create “Forecasts”.
As part of the feedback that we (Me & @Corey) got from some of the industry experts was to apply the coefficients on a new set of data, however, this method is least preferred, considering the fact that the dynamics of new data are highly likely to be not the same as of the data for which the coefficients were computed.
As it is mentioned above, the only workaround is to train a new model with the new data. Please feel free to provide your ideas on improving the nodes from the new time series extension, by posting on the forum and we will incorporate it in the future releases.
Hi @aliasghar_marvi,
wow I’m so excited and honored again to get feedback and help from the experts/architects of the knime-nodes.
Thank you very much for your explanation. I already went on with the “workaround” (which in fact isn’t one) and results are good (and way better than the solution/results we had before). I was just curious about how it is supposed to be solved but I’m happy now since I know that this “workaround” is the right way.
I’m really excited about KNIME and the support one can get in this forum, thank you very much <3.
Of course I’ll try the new time series extension nodes.