I face following challenge that I wonder how it can best be solved:
Case
1.) Data is imported via Excel Reader followed by some tweaking.
2.) User can mark certain rows in “Table View” to be excluded from following calculations.
3.) Based on True/False column created in step 2, certain rows are excluded from calculation.
Problem
Every time the Excel Reader from step 1 are executed, Table View under step 2 loses True/False marking. User has to mark rows to be excluded again.
Question
How to ensure marked rows are filtered out after a refresh in elegant way?
[Optional]: How to show previously marked rows as marked in Table View after Excel Node refresh.
Failed/non-elegant solutions:
Something with calculating a hash over a row - but I did not find a note to calculate one.
Dump sorted out rows in an excel file that I import later. Tried with Joiner linked to many columns to find sorted out rows in the original data set and then with very complex rule editor to overwrite True/False generated by Table View in original dataset. My code did not work under all circumstances.
I basically need some kind of node that sorts out (or marks) rows in dataset provided the same row shows up in certain excel table.
If I understood correctly, you would need to “uniquely” identify each row in a table with a “unique identifier” which you keep in a table to later keep track of what you need to filter IN and OUT. There could be many different solutions to this problem as you suggested. I propose below an implementation for your first suggestion which I found judicious:
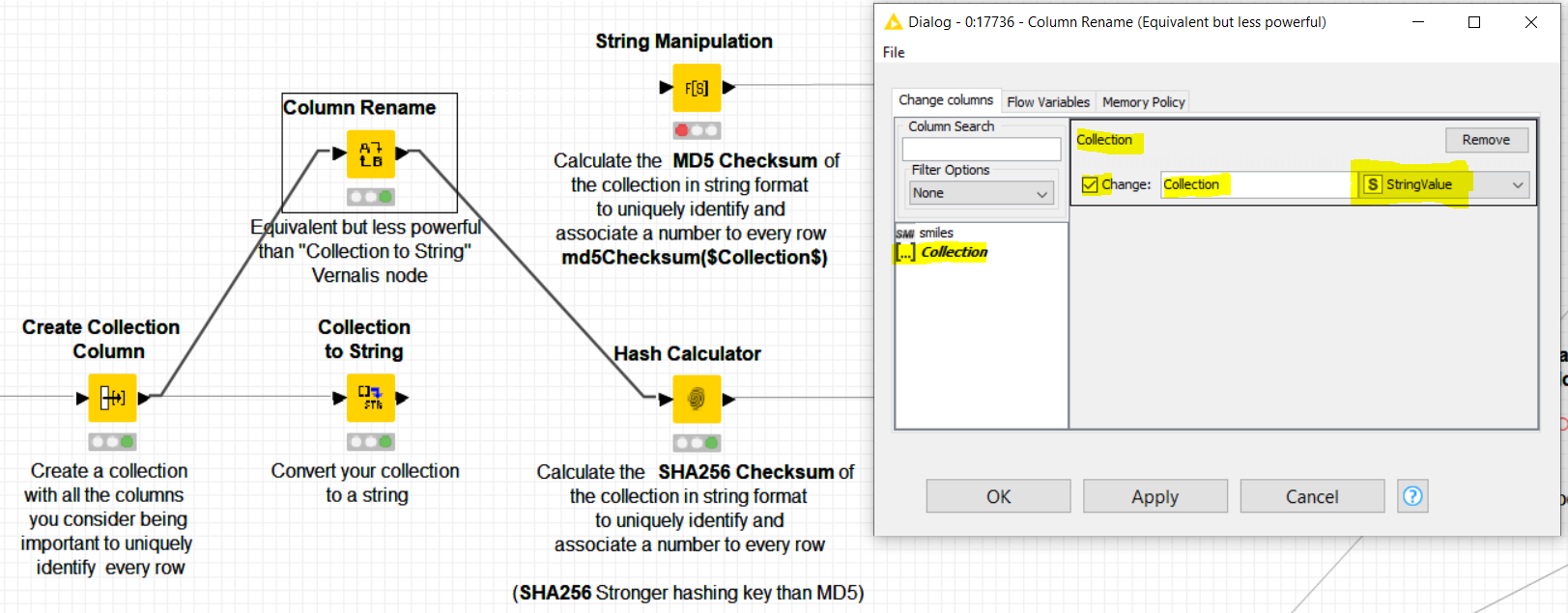
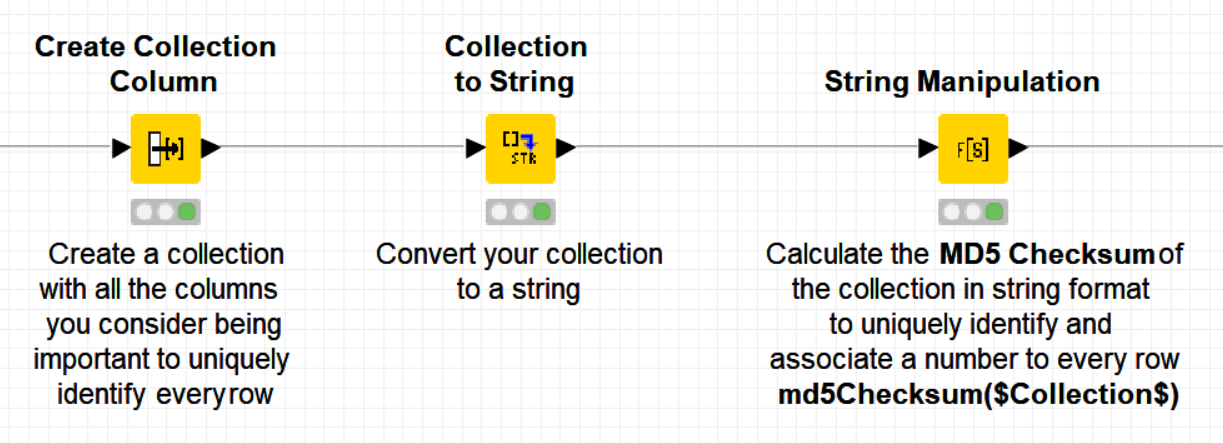
The trick here is to create a unique “very long” identifier made of the concatenation of your most important columns that uniquely identify your rows and then transform it into a “very short” unique identifier based on the MD5 checksum (MD5 - Wikipedia).
Most probably other suggestions will follow from other people. Hope you like this one and helps.
@MathiasBenedict : A complementary information to my previous post. If you prefer to use other more strong hashing keys than MD5, such as SHA256, then you can use the “Hash Calculator” Palladian node:
A comparison of hashing keys is given here with explanations :
Finally, to achieve your filtering, you would not need to use a joiner but just a “reference row splitter” based on the generated hashing keys, should be good enough:
It looks great ! Thanks for validating the solution, sharing the snapshot of your final implementation with explanations and for the feedback. Very useful for the community. I love it !
All the best,
Ael
PS: The KNIME “Rename Column” node could do the job too instead of the Vernalis “Collection to String” node, but the latter is more flexible and powerful
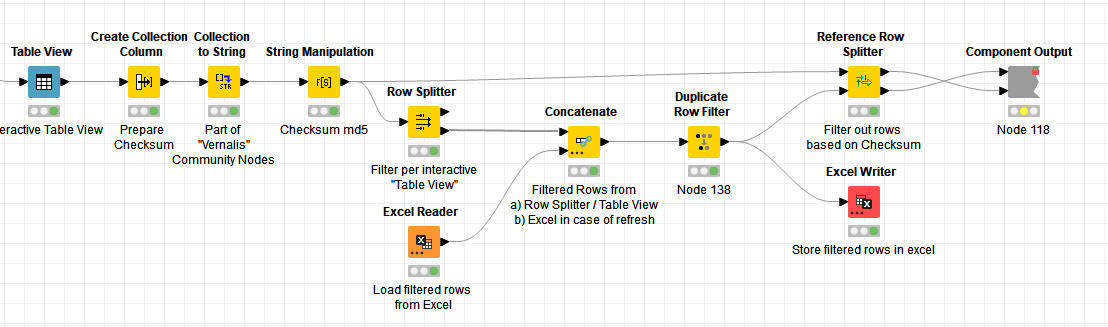
I was having a play with the interactive user selection and storing away previous selections. The logic that you mentioned in your original post seemed reasonable in terms of how you might go about trying to solve this problem. I thought I would put together a workflow for the following use case and maybe it would give some ideas .
In my scenario, we have an Excel spreadsheet consisting of Name, Date of Birth, Wage and a column for Wage Increase. The idea is that on each run of the workflow, a user could select one or more rows from the Table View and when selected, a 10% wage would be applied to the selected rows.
We want to present to the user the entire file of wages each time, but only allow them to process somebody if they haven’t been processed before. Clearly we could just not allow processing if the “increase” column showed non-zero but let’s ignore that minor detail and work on the idea that we only process a row if the “previously selected” flag that we’ve stored away on a csv file is not set to “Y”.
On the Table View, the user can select any row they like (I couldn’t see how to prevent that ) so after returning from the Table View, a Rule Engine ‘de-selects’ any row that was previous selected.
The Wage Increase action takes place on the required rows, and the “previously selected” flags are stored away in a CSV file for processing again on a future run of the workflow.
In the attached workflow, to I have used a couple of “home grown” components. These have blue-box annotations near them. They are here because it is easier for me to produce the working demo with these to simplify a few things, but they aren’t really related to the mechanics of the demonstration. You are free to make use of them or replace with your own nodes and processes as you see fit.
The boxes in red indicate the nodes that are just used to “reset” the workflow to an initialised state. You can activate those nodes by configuring the CASE switch to use port 0. Set it back to 1 again to run (and re-run) the main branch of the workflow .
I hope that the annotations provide sufficient guidance about what the workflow is doing. I hope it gives some useful pointers.

 !
!