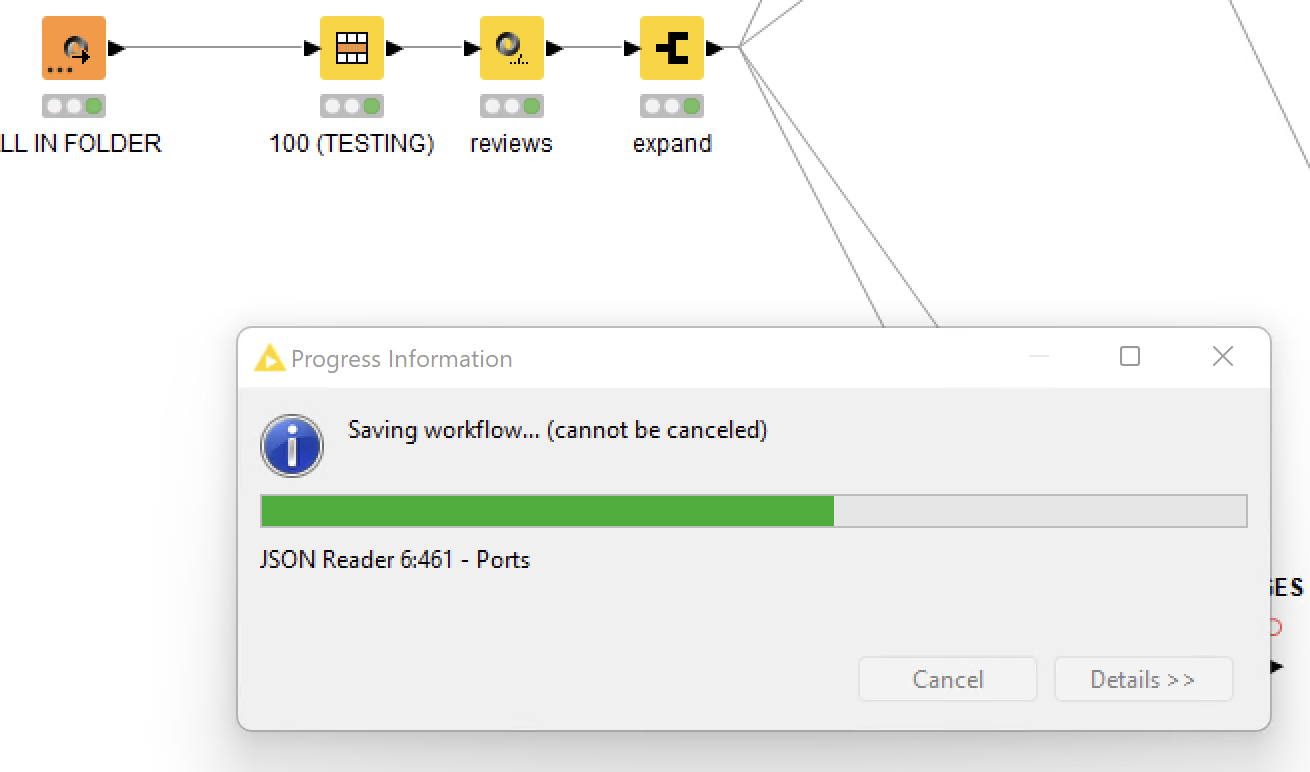
I have a workflow (a few) that reads a few million JSONs and then transforms them to save them into different DBs. When I try to save the workflows, it takes over an hour. I assume its due to the size of the data in it. However, there is 0 disk activity, and no computer limits are hit. The HDD is a raid with 7k read and write speed. How can I solve this?
@nxfxcom First question would be how large these files are. Every node will have to be saved together with the data unless you tell the workflow not to save certain parts:
Then the inaction on the side of the disk might be due to CPU operations handling the data. You also might want to check the RAM settings in the knime.ini if they would be sufficient for the size of your data.