Continuing the discussion from Save XGBOOST Model as PMML:
@knimebine007 I don’t think there is any option of exporting an XGBoost model to PMML although there is the “Gradient Boosted Trees to PMML” for the “Gradient Boosted Trees Learner”.
https://xgboost.readthedocs.io/en/stable/tutorials/saving_model.html
You can use the generic KNIME model exports for the XGBoost integration of KNIME. Could you tell us what it is you want to do?
Hi,
yes I noticed the “Gradient Boosted Trees to PMML”-node and hoped there will be also one for XGBoost models.
I want to transfer the learned model in KNIME to python for predictions in this python environment. Any idea how to transfer?
best regards
Sabine
@knimebine007 I tried a few things but it seems not to be possible to transfer models of xgboost between knime and python. You could set up xgboost in python nodes. I will habe to see if I can make an example.
Best way to transfer more complex models between knime, Python and R is the H2O.ai MOJO format
Depending on you data. From my experience when a robust tree model is of any use often H2O.ai GBM does come close (To XGBoost). You could let that train with automl an benefit from the grid search within or set up you own hyper parameter search.
@knimebine007 I toyed around with KNIME and Python and you could configure KNIME nodes that would use the XGBoost Python package and store the model in a local JSON file and reuse it with new data. The work will be done in Python but KNIME can create the workflow around.
From what I see is XGBoost still under development and some settings in the cooperation between KNIME and Python and XGB are maybe a bit strange but they will work and the jobs can be repeated.
The label is the column “Target” (0/1) and there is a “row_id” present to stand for a possible customer number or ID to later bring the scores to another system. Some XGBoost parameters might have to be adapted.
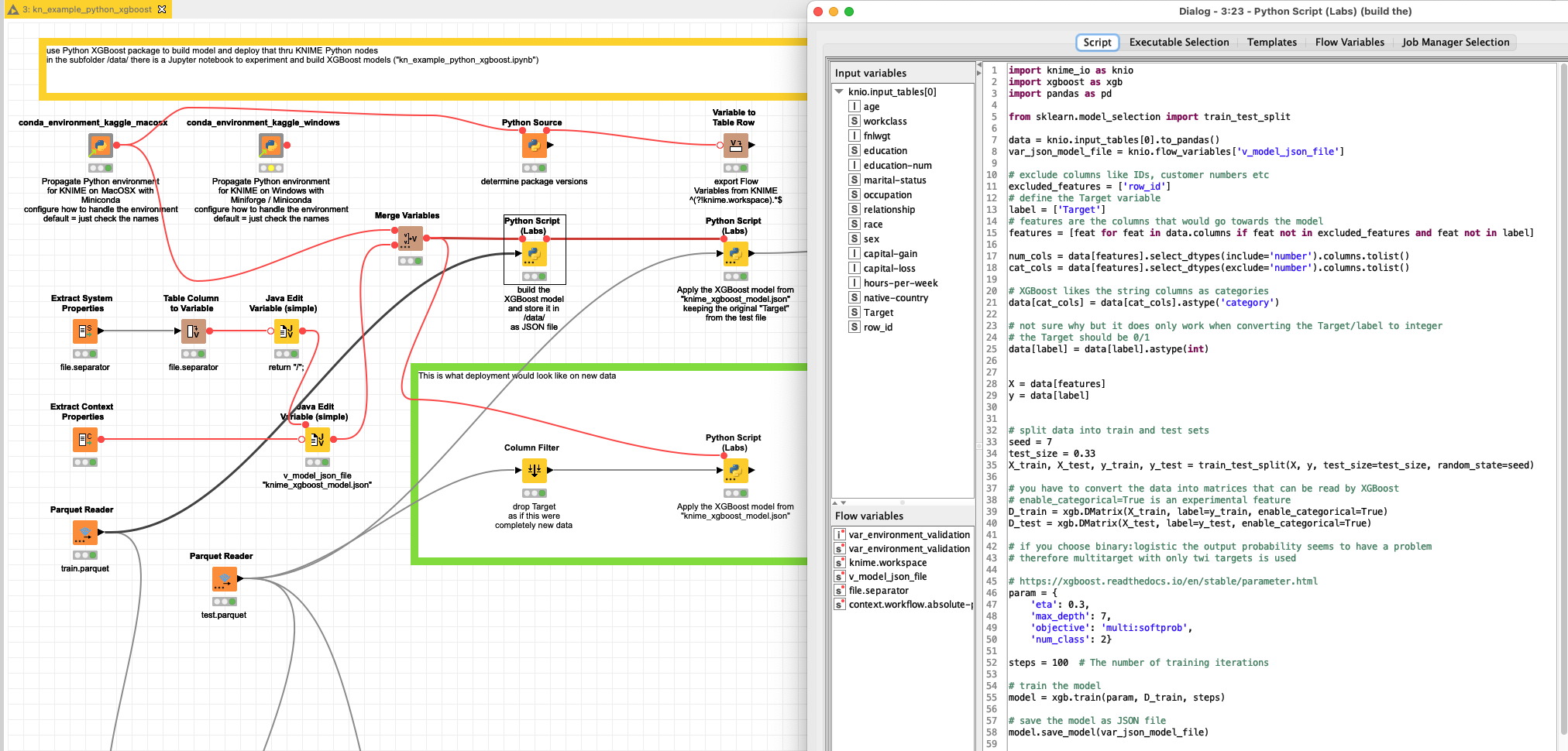
In the subfolder /data/ there is a Jupyter notebook “kn_example_python_xgboost.ipynb” where I tried to set up a running workflow. Data can be interchanged between Jupyter and KNIME. And notebooks might also be run from within KNIME.

Yes indeed the whole thing might be somewhat over-engineered but I always wanted to set up such a workflow - in general you will be best served with just using the great KNIME XGBoost integration ![]()
3 Likes
@knimebine007 OK while I am fuzzing around @LukasS has already built such a workflow ![]() including an option with R.
including an option with R.
2 Likes
Big thanks for all the hints and the workflow, I hope I can test it to the end of next week. First I have to update to 4.6…
1 Like
Meanwhile I updated to KNIME 4.6 and could look&run the workflows.
I used the storing of the model as JSON file and I compared the XGBoost-node-version and the Python-version with my own dataset.
The confusion matrices values are the same and I could reuse the model for new data via JSON file too now, that’s great!
Thank you again,
Sabine
2 Likes
hello again,
I’ve a question to @LukasS:
In the XGBOOST KNIME/python comparison a parameter table of 400 combinations is used.
How are the values determined?
Perhaps by a DOE tool? Or based on experience?
Nice day,
Sabine
Hi Sabine,
unfortunately I don’t know how those 400 parameters where generated as I got them as they are from a customer.
May I ask why you ask? In case you want to optimize your model for some metric, I would suggest the parameter optimization loop pair - it will then sweep though how many different parameter you ask for and spit out the result of the best set.
Best regards,
Lukas
Okay, thank you for the suggestion! I will learn and try more about the Bayesian Optimization (TPE) method, very interesting!
Best reards
Sabine
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.