Dealing with duplicates is a constant theme with data scientist. And a lot of things can go wrong. The easiest ways to deal with them is SQL’s GROUP BY or DISTINCT. Just get rid of them and be done. But as this examples might demonstrate this might not always be the best option. Even if your data provider swears your combined IDs are unique especially in Big Data scenarios there might still be lurking some muddy duplicates and you should still be able to deal with them.
And you should be able to bring a messy dataset into a meaningful table with a nice unique ID without loosing too much information. And this workflow would like to encourage you to think about what to do with your duplicates and not to get caught off guard but to take control 
For a start we have to deal with this dataset
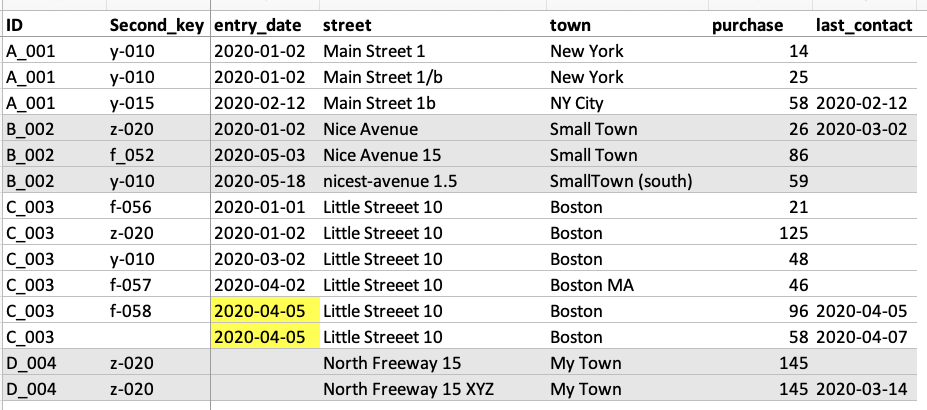
We have an ID and a Second_key, some dates and an address (they do differ over time) and a purchase date. So there are a lot of duplicates - they all might carry some meaning and we would like to get everything into one line without loosing too much information.
First we select the highest purchase ever and keep the date of this event per ID.

This demonstrates KNIME’s extended duplicate row filter that acts like the following method using SQL.
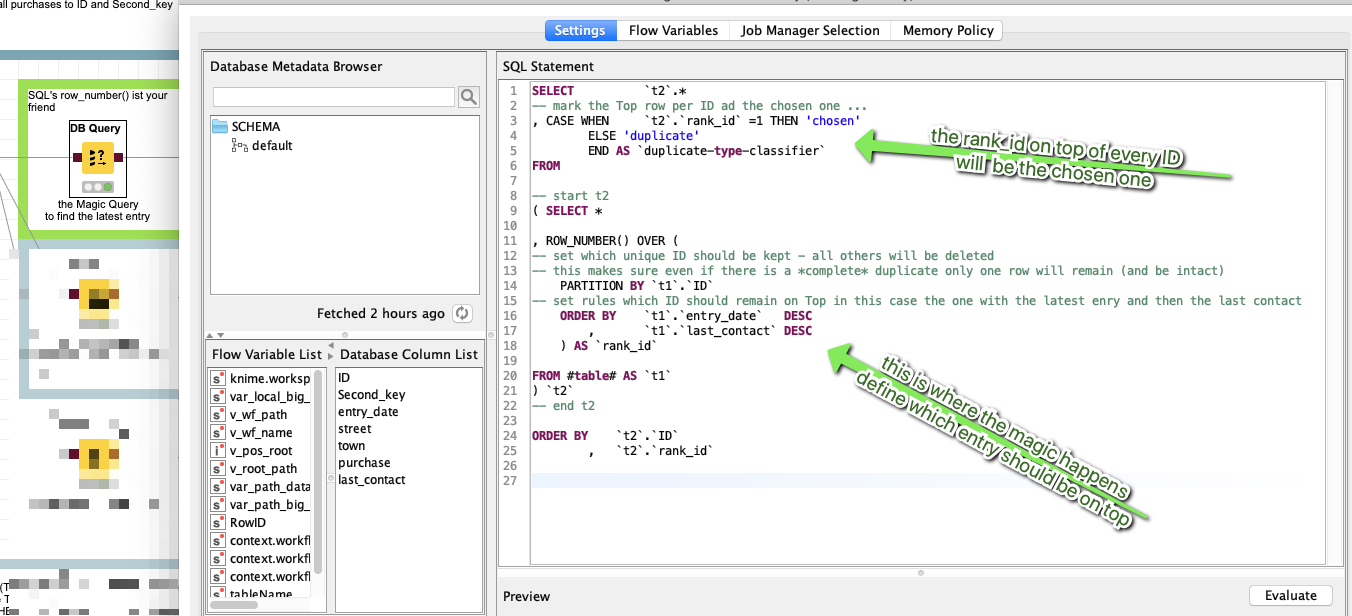
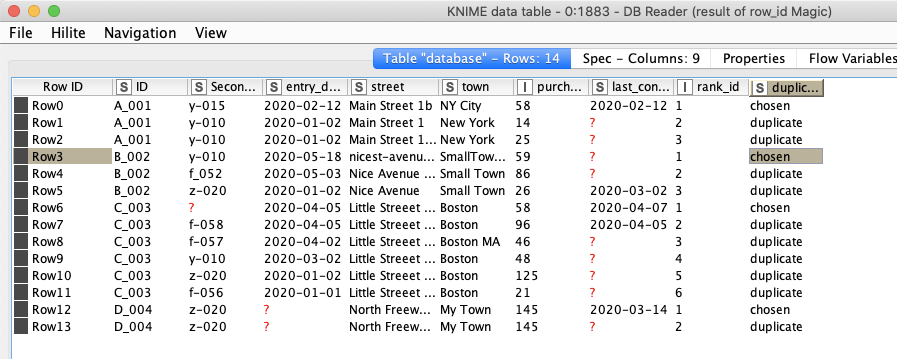
Now there is one ID per group marked ‘chosen’ and you can see what would cause an entry to be ranked higher. The row_number makes sure there can only be one entry be chosen even if we would have two lines that are completely identical (peace of mind assured).
OK. What to do with the Second_key? The one where there could be several entries and one would not know how many. The group by node offers a solution by having various methods to bring them into a list or collection. So you could keep the information but in one line.
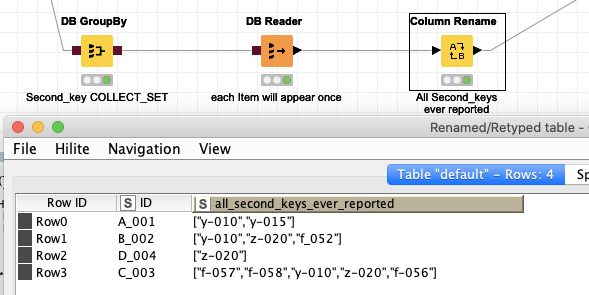
We can take it up a notch and add information to such a list:
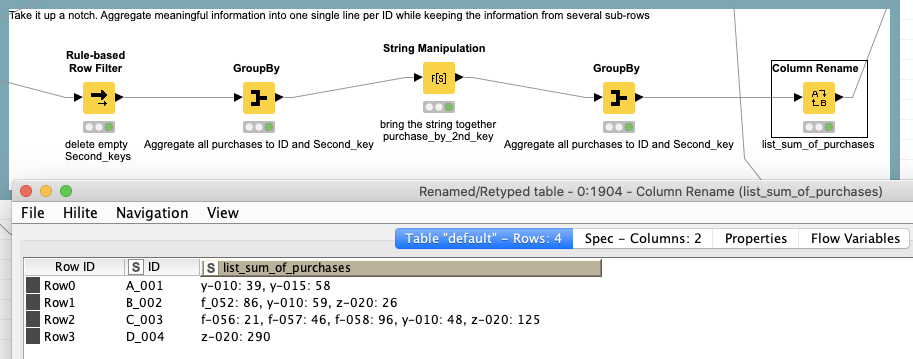
We aggregate the sum of purchases by every Second_key and make a list we then could have aggregated to each unique ID. That might not always be the best solution but it would enable you to store the information in one line.
Then to demonstrate another use of the row_number() function. We choose the latest entry as our ‘leading’ line per ID. Now we want to see about these strange addresses. We combine street and town and see which string is the longest one and provide it to the system.
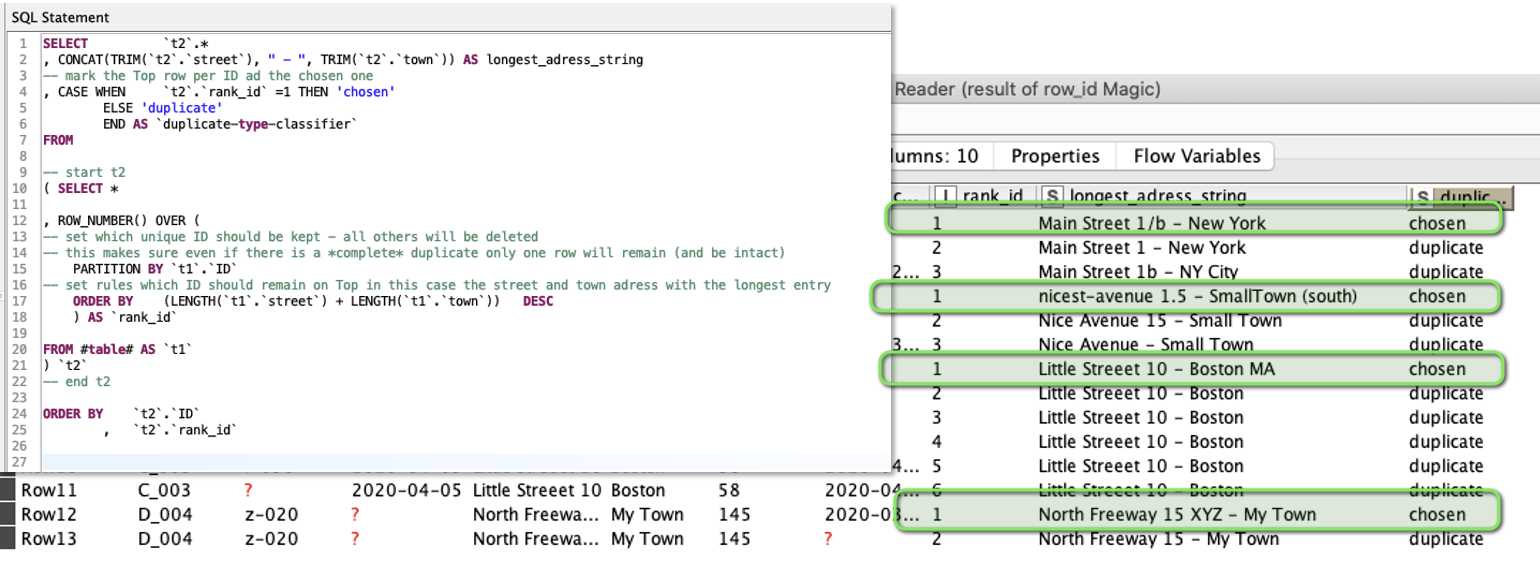
So in the end our ‘messy’ dataset with lots of duplicates turned into a nice (report) table where the information is mostly kept and the duplicates have been removed: