Hi everyone I am trying to scrap a text from a URL but after several Xpath queries I am still unable to extract a specific text.
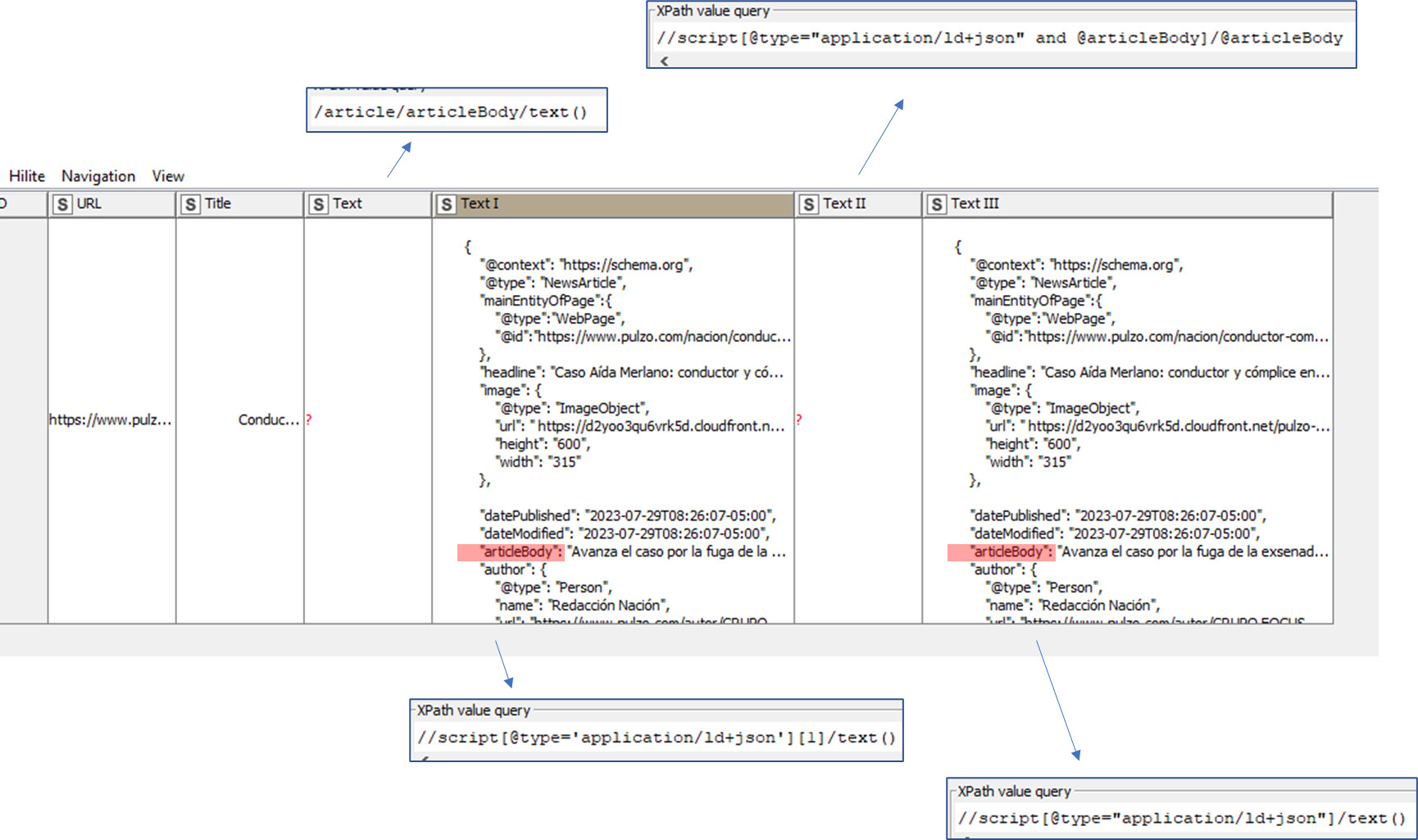
The following image show the queries applied
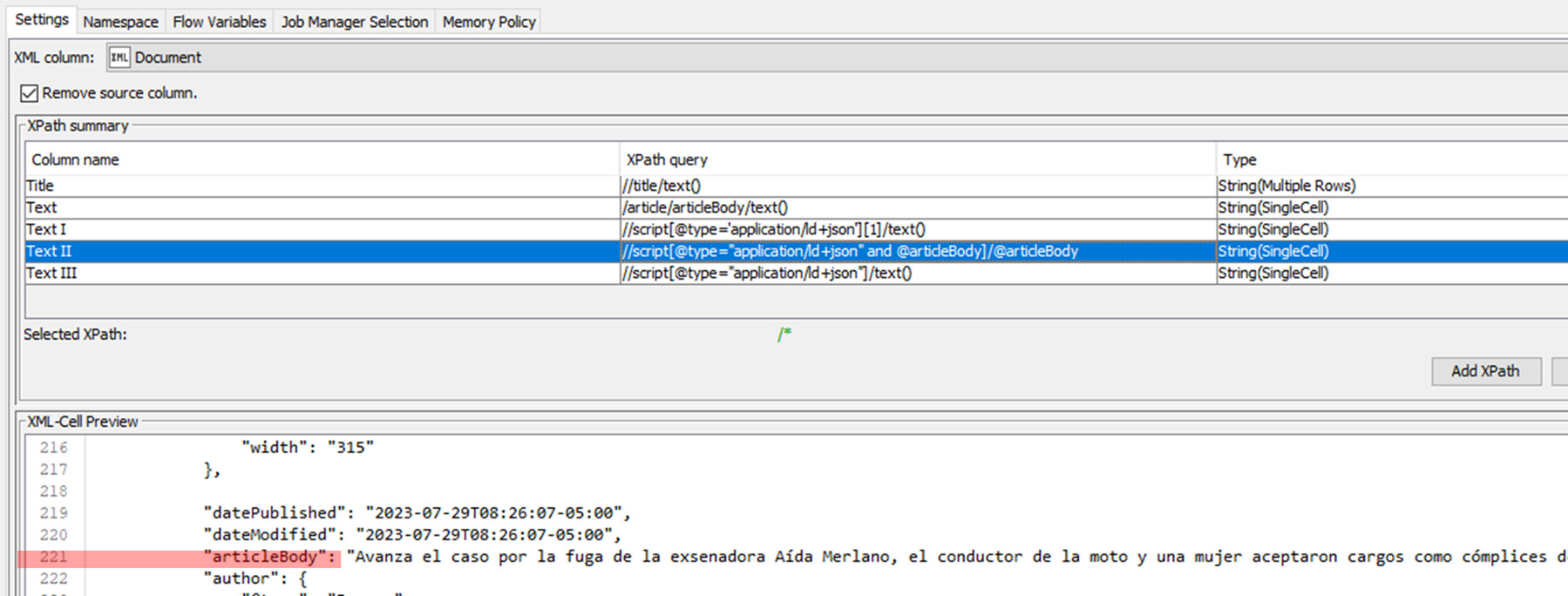
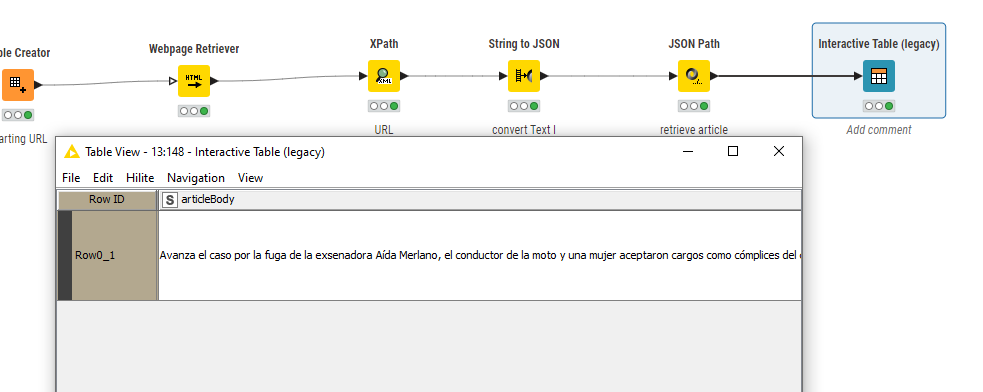
I want to extract the text after “articleBody” : "“Avanza el caso por la fuga…” which is in line 221
I am attaching the workflow
Extract News Text.knwf (119.8 KB)
Regards
takbb
July 29, 2023, 4:14pm
2
Hi @mauuuuu5 ,
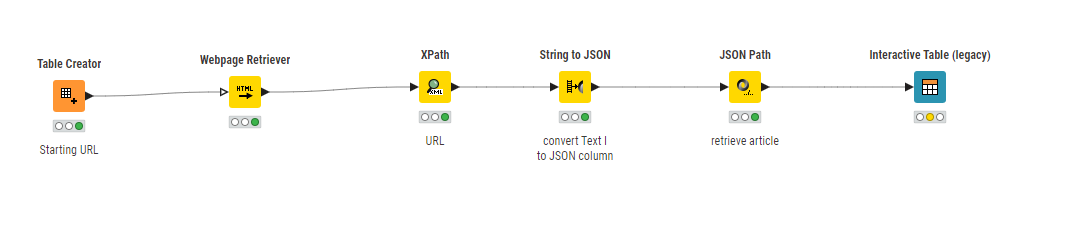
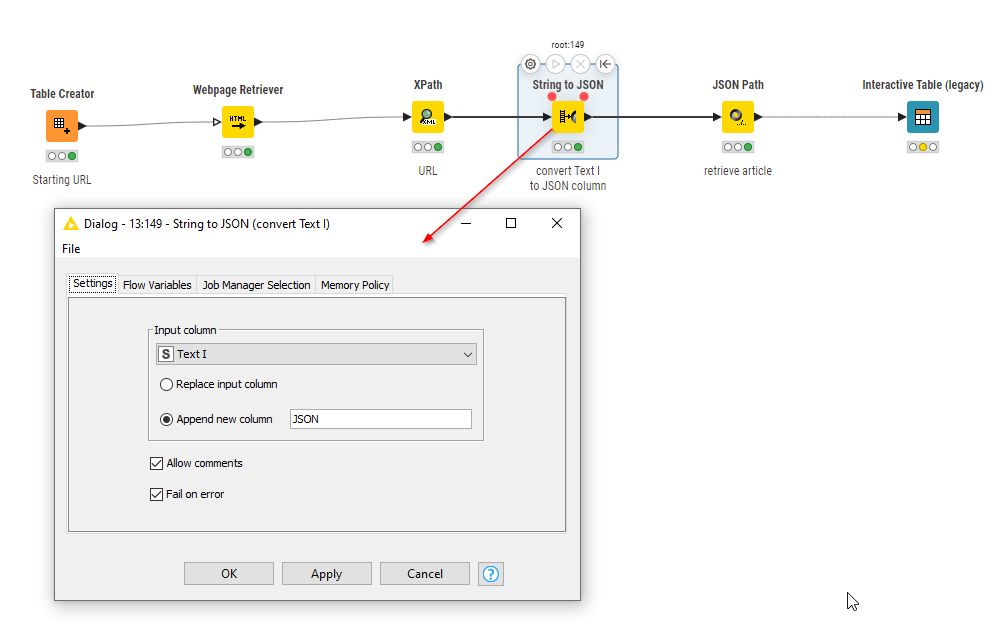
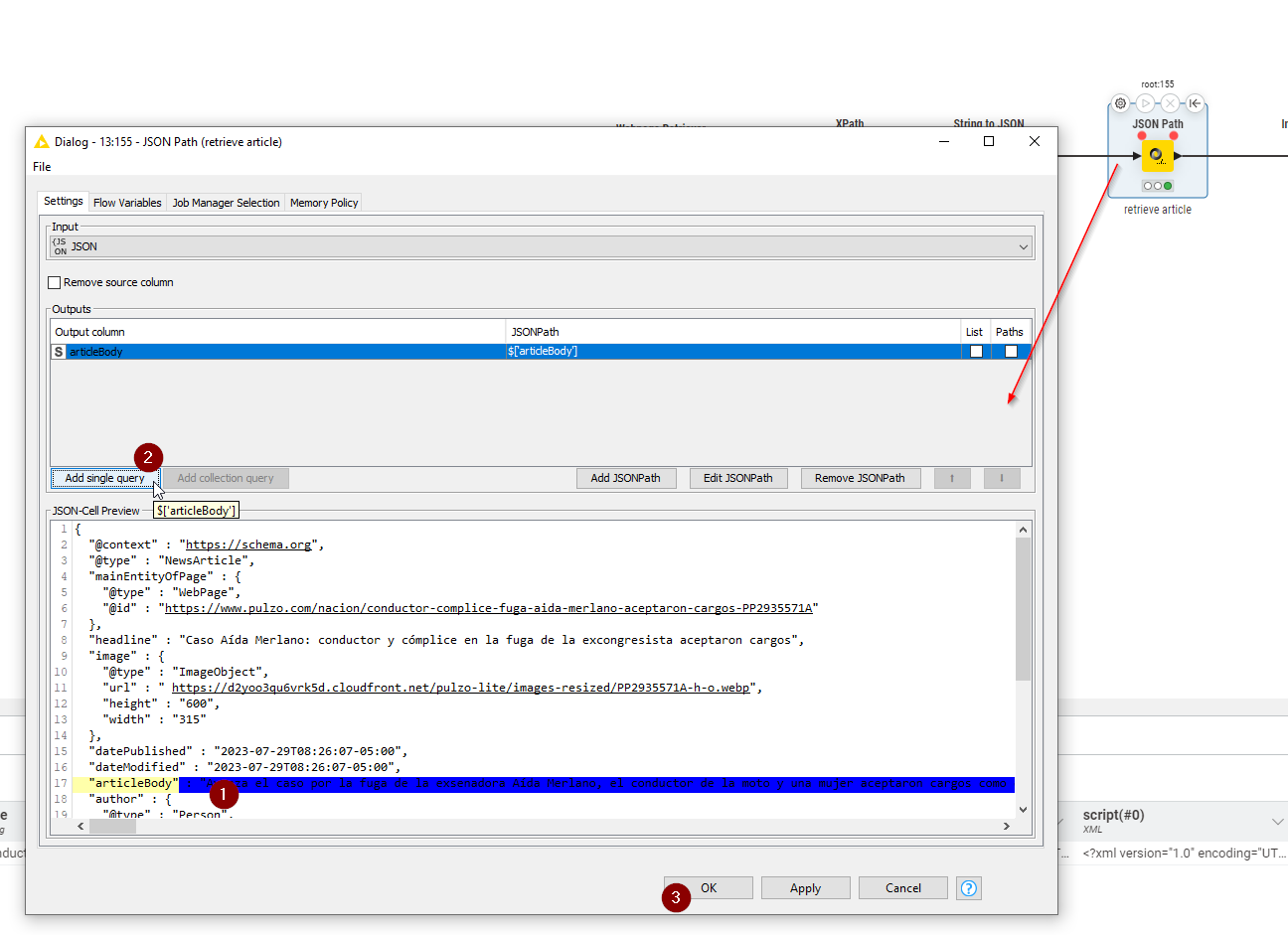
You are nearly there I think, but the script that you have successfully collected into the “Text I” column using the XPath node is embedded JSON, so following this collection, I think you will need to then interpret the JSON.
So, follow your XPath node with String to JSON
and then follow that with JSON Path
Clicking each item in succession as shown in the above screenshot should place
$['articleBody']
in the JSONPath
This should then retrieve your article.
3 Likes
system
August 5, 2023, 4:15pm
3
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.