Hi,
I try to scrape this html file that now I attach like a txt for limit of forum CSA Football Players Exchange.txt (889.4 KB)
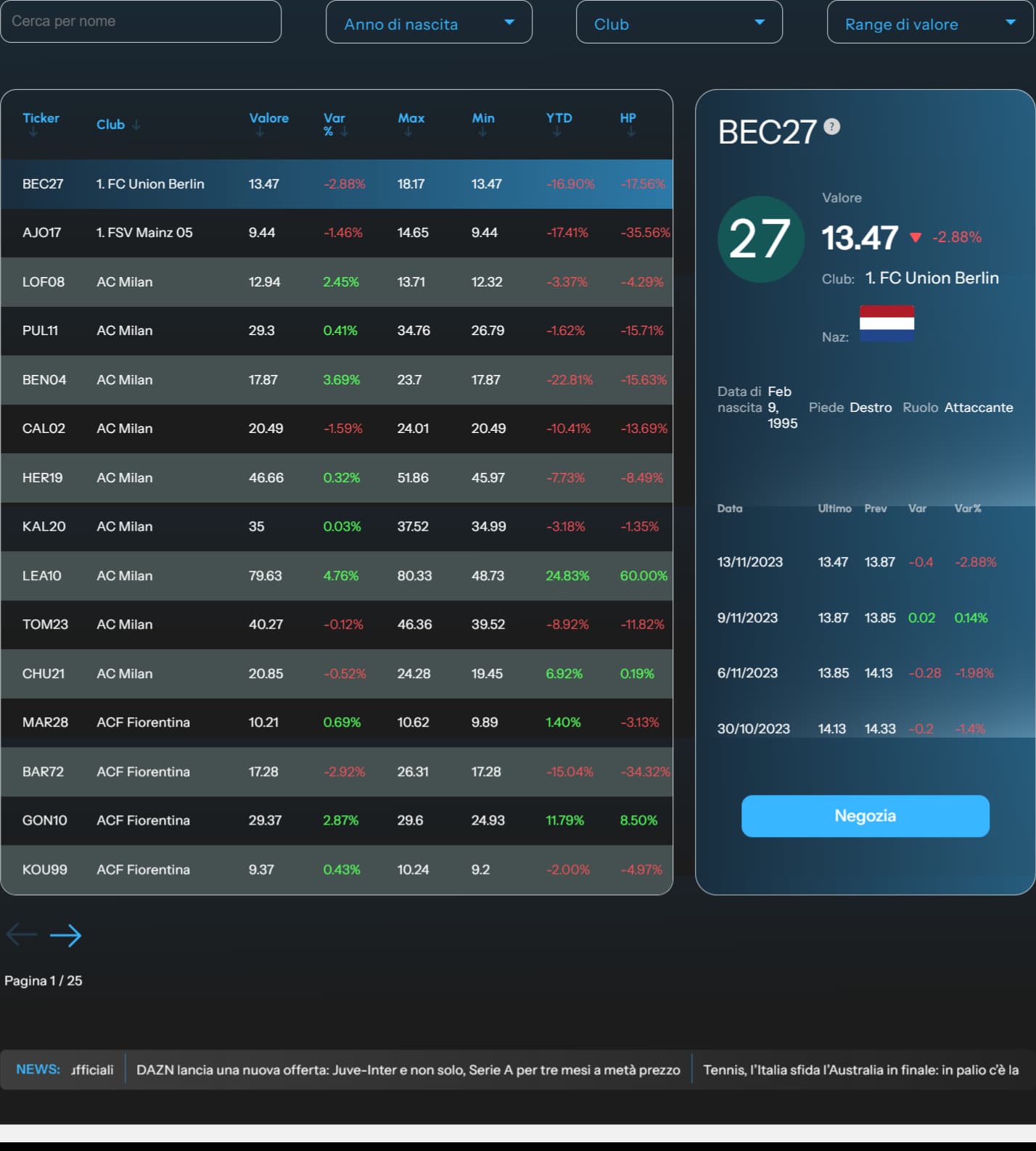
I wanna scrape this page for analyze the table inside (I think row nr. 1228), this is a screenshot of the table on webpage.
API is always preferred. If the page is structured easily a small script could be an option. You could also give Webpage Retriever Node a try
good luck an br