Hi there,
I can no longer extract some information from book reviews of an online bookstore (name, comment, rating) with the XPATH node. I don’t know what has changed on the site. What should I change in the query? Is there an easy way to get the correct query of the fields of interest?
Thank you very much!
Alfredo
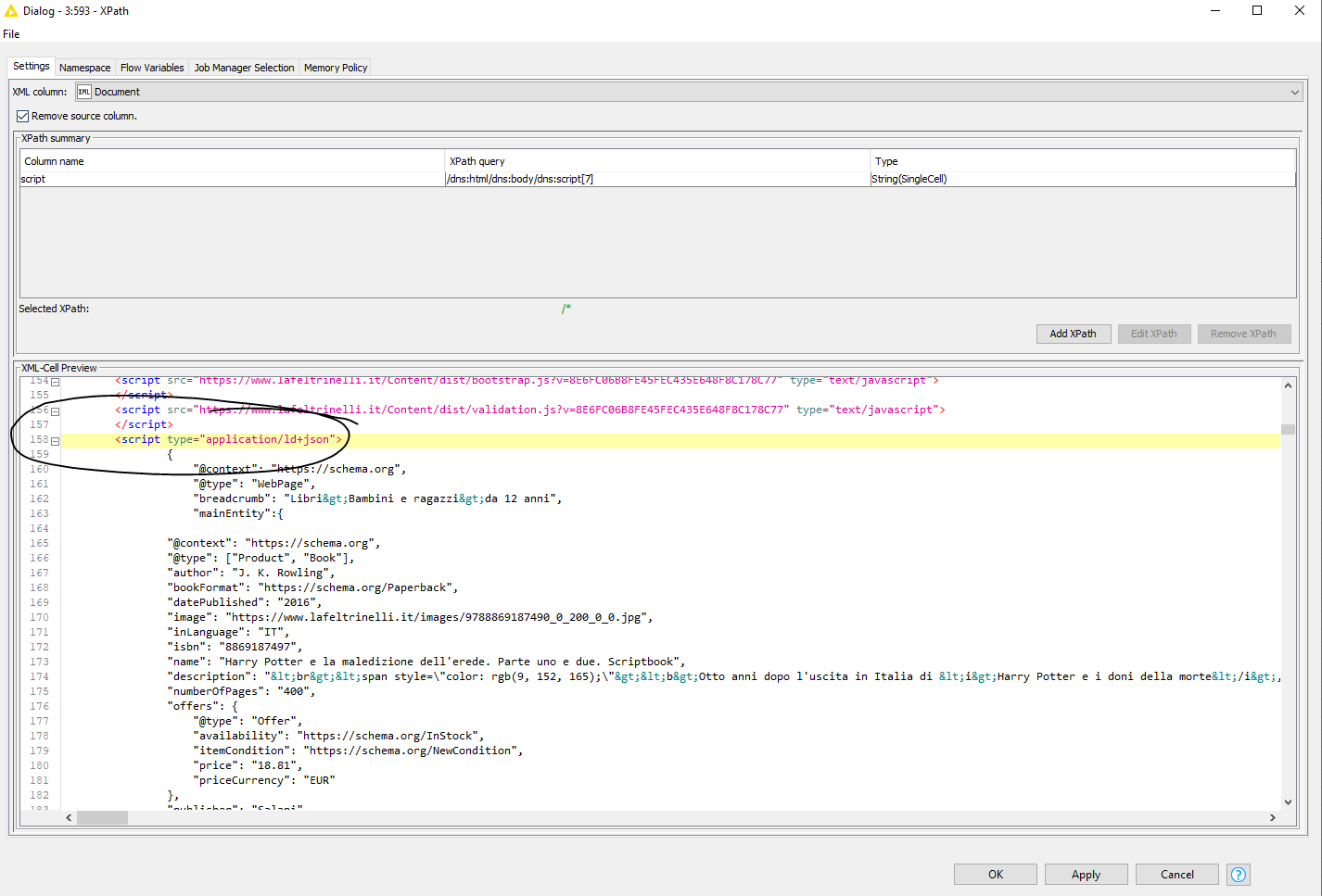
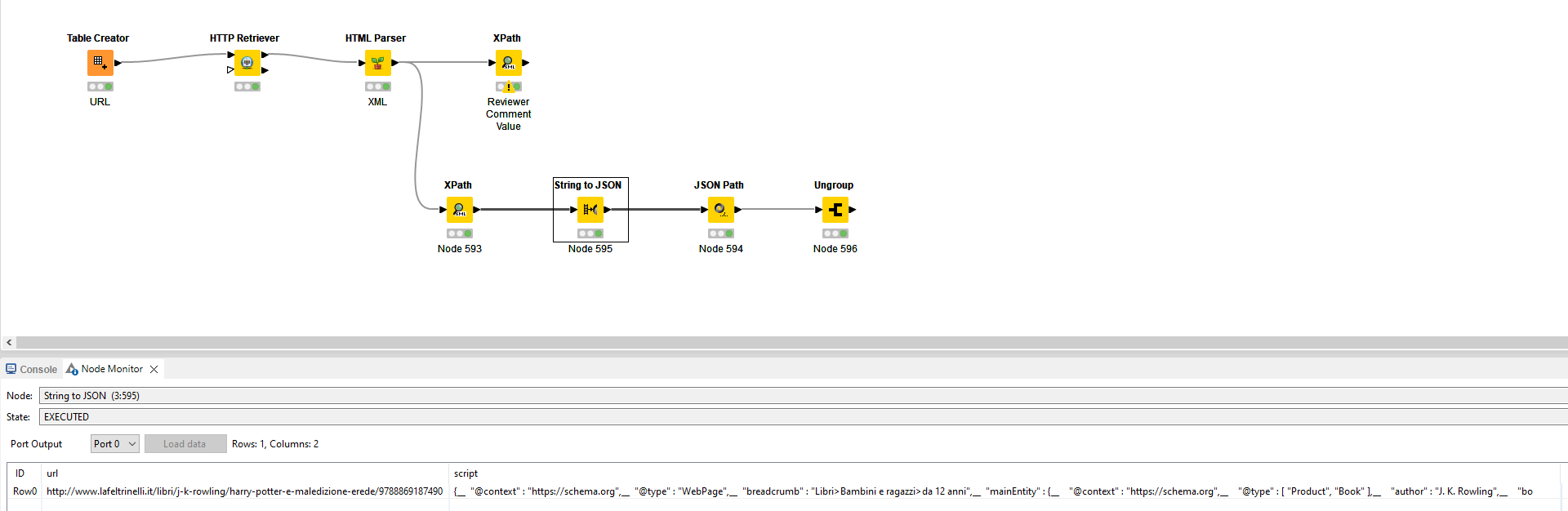
What you still can do is extract that whole section based on /dns:html/dns:body/dns:script[7]
Once extracted, you can convert this string to an actual JSON format to run queries against with the corresponding node.
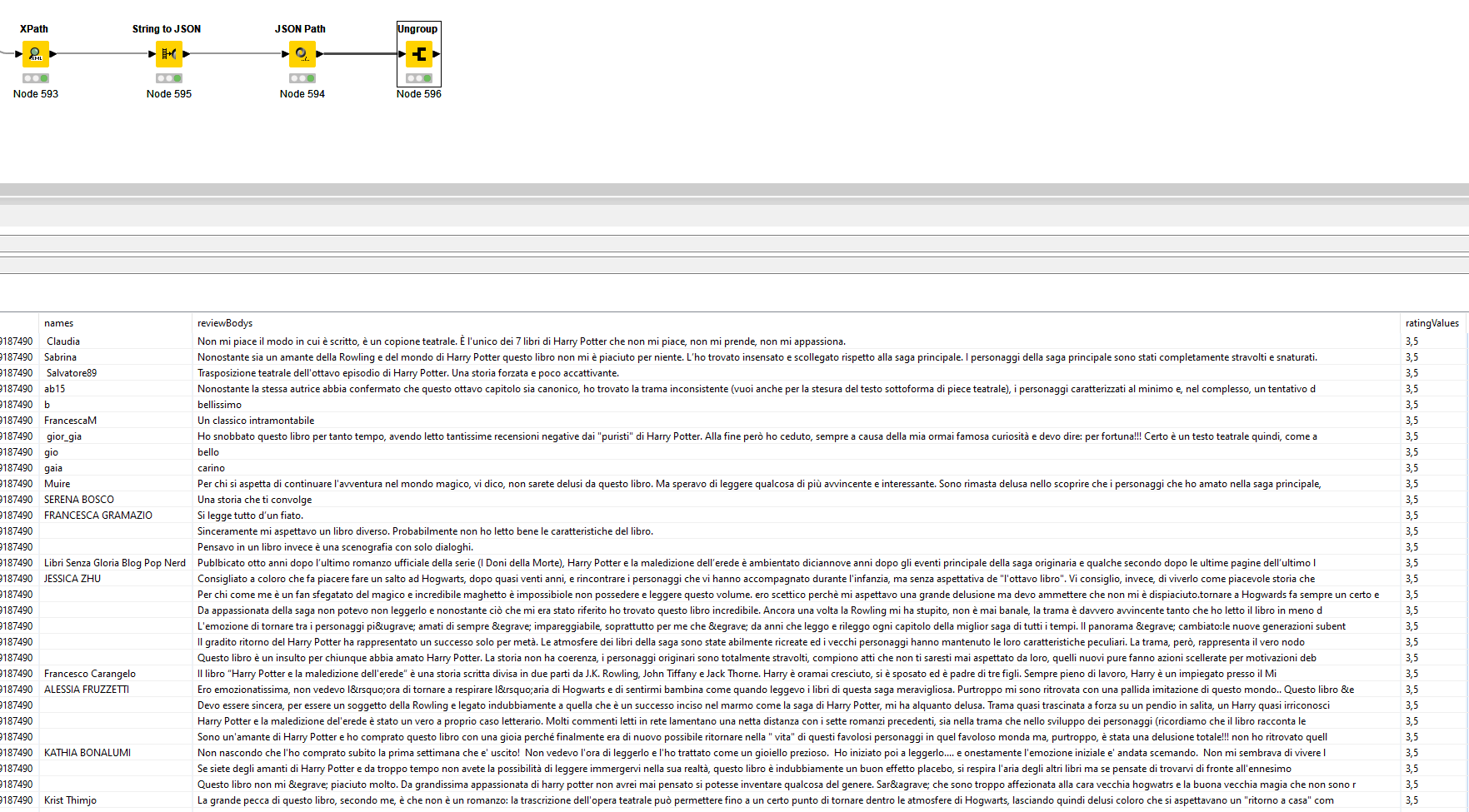
The strange thing here is that according to the data, the rating is always 3,5 while the actual page shows something different. Not sure what’s going on there.
Hi @ArjenEX ,
excellent solution, compliments! Too bad that the ratingValue column only represents the average value and therefore unusable for my purposes…
Thanks anyway!
Alfredo