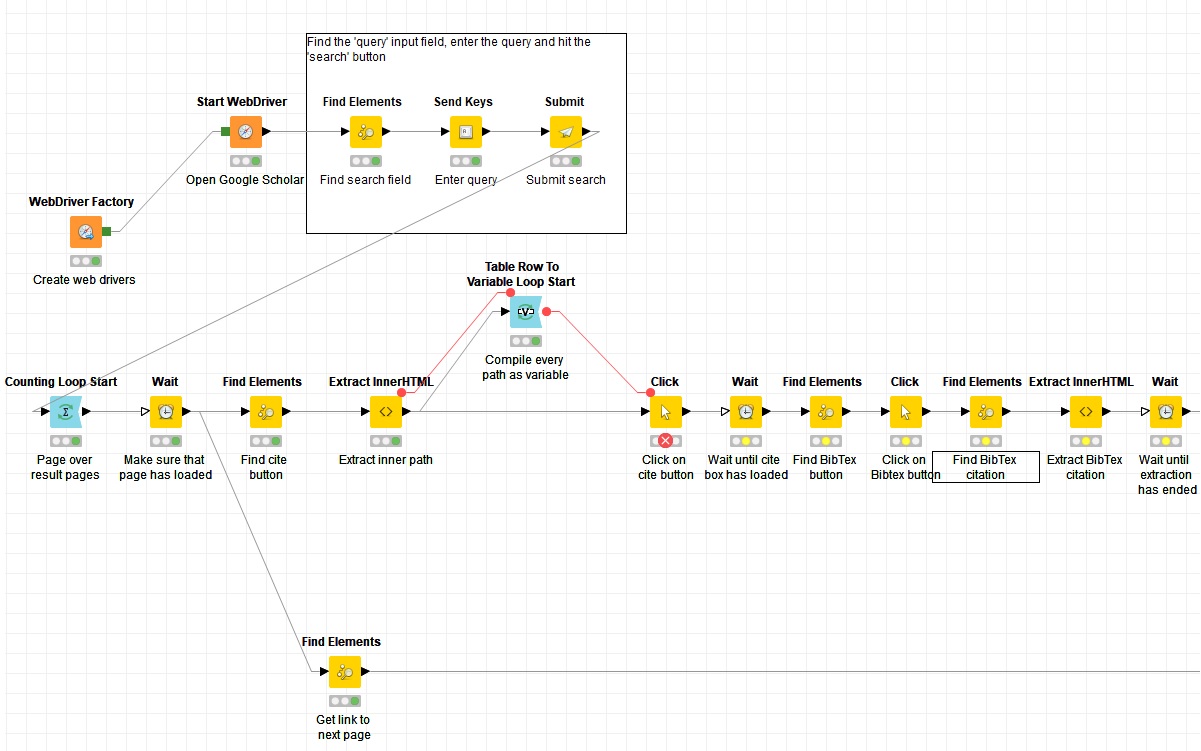
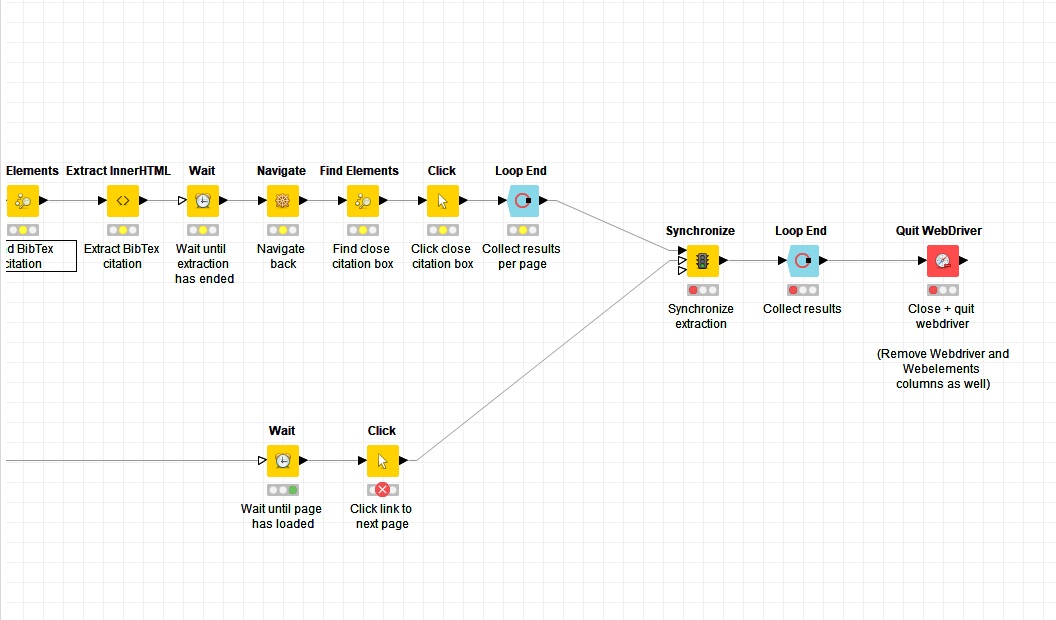
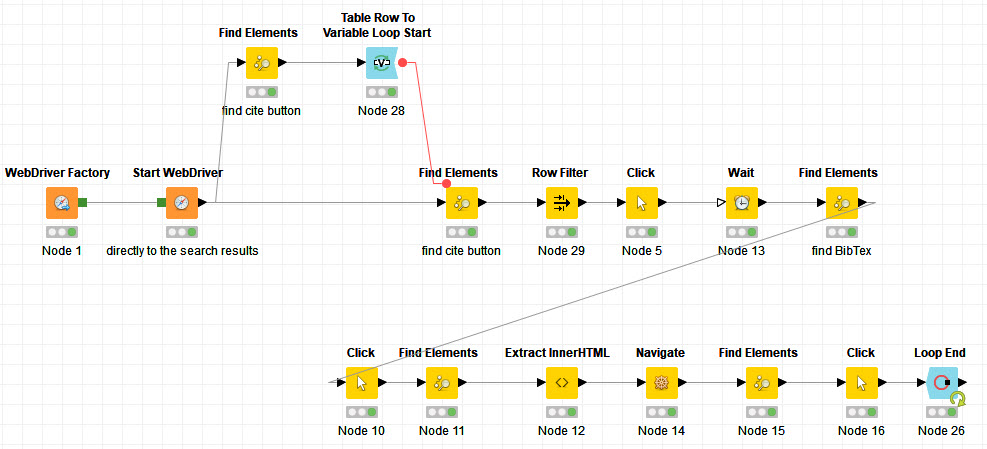
I’m trying to scrape reference cites from google scholar using selenium. I tried to make a loop to click multiple popup boxes on the same page which the cites are. I’ve also tried to look for the direct links of the pop up elements to make the loop. But I couldn’t make it with these two approaches. If you know about a different one or maybe in some way make these approaches works I would really appreciate it.
Look at the workflow pictures I attached here.
Thanks in advance.
You cannot pass several elements to click (webdriver tries to click them all). I used a Row Filter to keep one row regarding the current iteration number.
The Find Elements node which feeds the click must exist in each loop iteration (so put it after the loop start node)
Thank you very much!! It works perfectly. I started to use Knime two months ago and I was stuck with this problem for two weeks. I also had a problem with the loop for pagination but I just changed some nodes to other places and It worked also.
Hi @armingrudd, hope you are good. This modeled helps a lot with what I am doing. However, I tried to add a new find element and a click node to extract the abstract of the papers, it is giving me a warning of an empty data table and only shows one result. Not sure if you can assist with solving such. I would like to extract at least 5 abstracts per each topic. See attached model and thanks in advance.
@Papoitema Each of the iterations seem to return a different kind of articles. Thus the extraction which worked in iteration #1, will not work with the next result.
Generally, you’ll need to make this more generic. Note for example, that sometimes PDF are returned, sometimes HTML pages. I’d probably first collect all the result URLs from the search results in a first workflow step and then think of an approach to properly extract the content in a second step.
For PDFs, there are dedicated nodes:
For HTML pages, I’d probably extract the entire DOM source and then try this one from the Palladian plugin:
If you’re just starting, have a look at this thread for an entertaining introduction into web scraping with the Selenium and Palladian nodes: