I noticed that chaining Python or R scripts is rather slow. Even when passing a tiny one-cell table, a series of 5 Python scripts takes 10 seconds to complete. R is not much better. I guess launching the Python/R environment and converting a Knime table to and from a pandas/R dataframe takes a really long time. Is there any way to speeds this up? The ancient Python Snippet node is much faster, but it converts the table into a OrderedDict instead of a pandas dataframe, and I have a suspicion that it is not entirely thread-safe. I am using Knime 3.7.0 on Xubuntu 18.04 64-bit.
Thanks for doing the benchmarking and reporting this! We’ll further investigate the performance issues and see if we can improve things.
On a side note: As for Python, you could at least try to tune the data transfer by using a different serialization library via File > Preferences > KNIME > Python > Serialization Library. I’d recommend giving Apache Arrow a try. It requires pyarrow to be installed in your Python environment.
This won’t help to reduce the time required to launch Python, however, which seems to be the primary issue here. I’m afraid there’s currently no other way to reduce the run time except for combining the nodes into a single one.
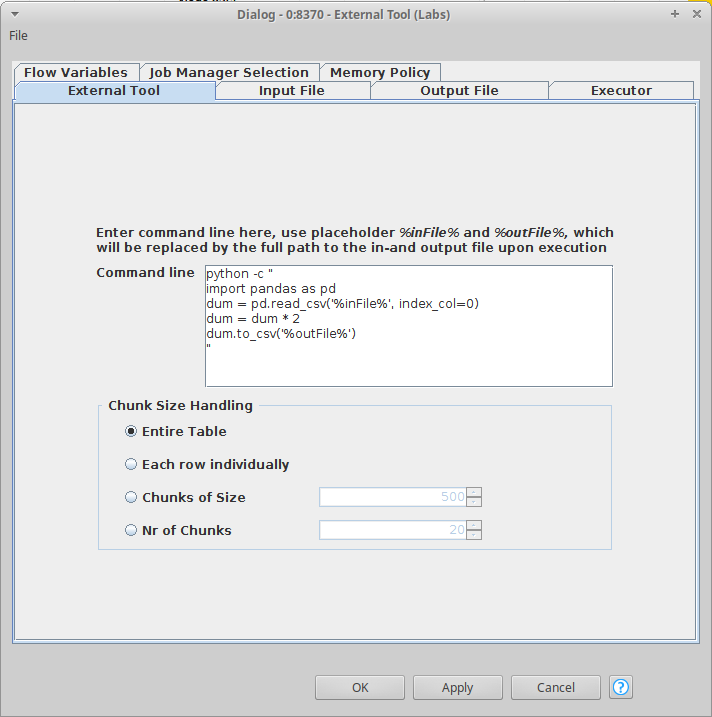
My solution above is fast but also not ideal because the “External Tools (Labs)” node forces a join with the input data, which is often not desirable. I really hope that the regular Python node can be made faster one day.
Just a brief heads-up: the upcoming release of KNIME Analytics Platform 4.2.0 will include some changes that should speed up the execution of chained or looped Python scripting nodes. These changes are already part of the nightly build.
And if you care about the technical details: this is achieved by pre-launching and maintaining a number of Python processes in the background. Upon execution, a Python node retrieves one of these processes instead of opening a new one, which reduces the node’s startup time (as long as there are still idling processes available; the maximum number of processes can be configured on the Python > Advanced preferences page) while keeping everything thread safe since every Python process is only ever used by a single Python node.
Pre-launching the processes is done the first time a Python node is being executed, so the first node in the chain will still experience some delay the first time.