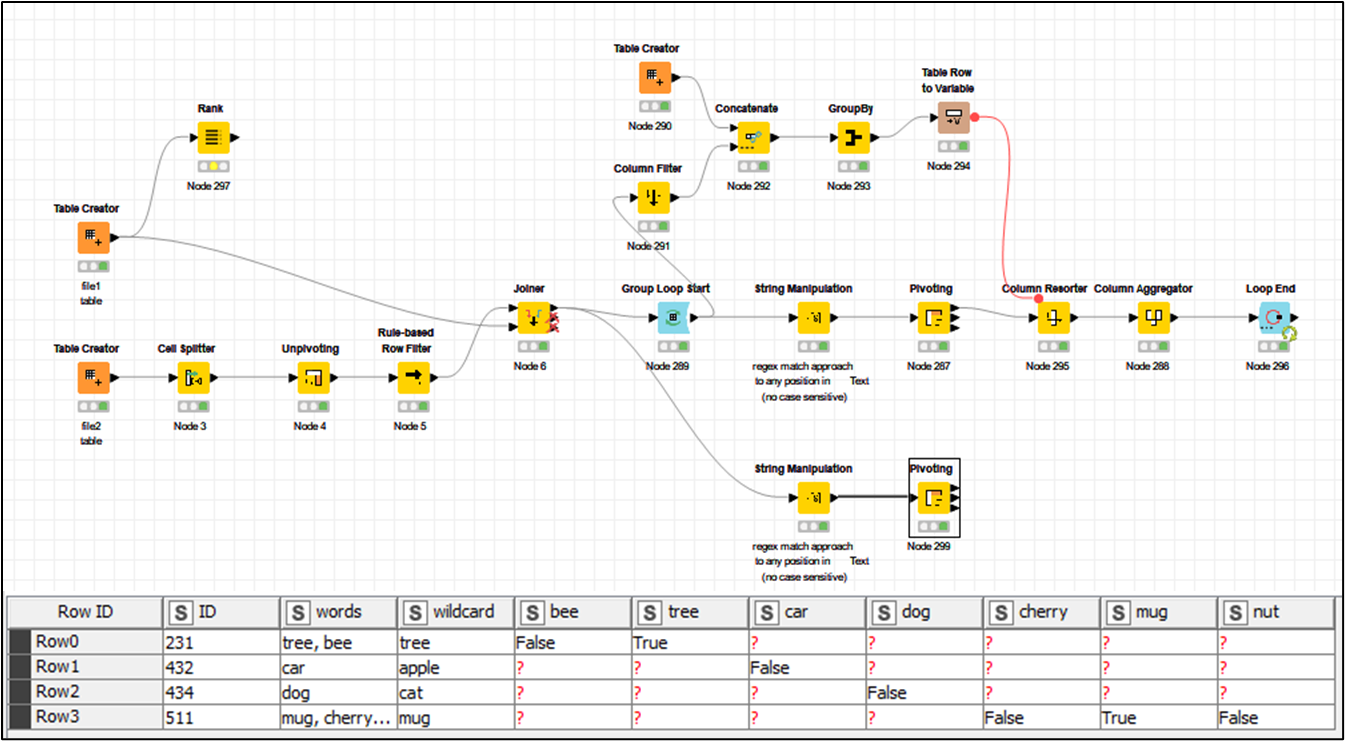
Hello Everyone, I have one excel file with a list of allowed words to be checked in the second. they both have an ID column to make the match. here an example:
file1:
ID Words1
231 tree
432 apple
511 mug
434 cat
File 2:
ID Words2
231 tree, bee
432 car
511 mug, cherry, nut
434 dog
I want to highlight for the same ID all cells of file2 where words2 are not contained in words1 in file1. In the case of multiple words in the same cell also I want to highlight the words that don’t belong to the same file, like for ID 511 mug is present but there are also cherry and nut not contained, this I want to highlight too.
I did a first try with rule based raw filter but filter just the exact word, so ID 511 is not considered.
thank you
thank you! I tried the pivoting like in your example, but something is still wrong… after the pivot not every cell get the TRUE/FALSE and I get some red question marks instead.
Hello @gonhaddock thank you for this workflow, I think it’s pretty suitable for my model. Just some points, I will have a big amount of data, the IDs are repeated many times on both data source so after the join I’ll have many repeated rows. Is there a way to avoid the join?
or Alternatively I could keep the table produced by the pivoting function and then filter by ID and words. How can I close the loop though if I want to stop it after the pivoting and don’t aggregate the data?
thank you
Hello @CYLE
I’ll try to answer theses in question order:
I don’t think that you can avoid the Joiner. But as an improvement focusing on performance, you can test to move the joiner inside the loop.
The repetition of the IDs is related to your pre-processing and I just can guess no robust solutions by scoping this mock data.
The main concern would be the repetition in the wildcard reference table (?) I cannot guess that your table relation is 1:1 as in the example, being the RowID your truly ID. As duplicated reference ID invalidates the UniqueID function. Relying on sorting you can play around with parallel rank (Dense) function in both tables, then use a double column for the Join columns() match .
Alternatively you can test to ‘Remove Duplicates’ after the join.
You can remove the loop and the worflow still works until pivoting node, but if your wildcard reference table is too large, you will end with a huge matrix mostly covered with nulls to be handle. Collecting the concatenate in the loop end was just a proposal of output. The shape you can display the data is more about your use case / functional requirement.
SUMMARIZING:
I pointed you to the mechanics of handling the data.
Aiming to help you about upgrading the workflow; you may want to extend the mock example trying to reproduce double ID issue.
Besides, if you could share an envision of your expected output would be great.
Hi @gonhaddock thanks for the hint. Starting from your workflow I added at the beginning an index column to get a unique identification of each rows, then I removed the loop and added a groupBy after the pivoting using the index as grouping and some concatenates in the manual aggregation. So I get as result a column with all the accepted words for each line. Would be great also to get another column with the not found words but I still have to figure out how.