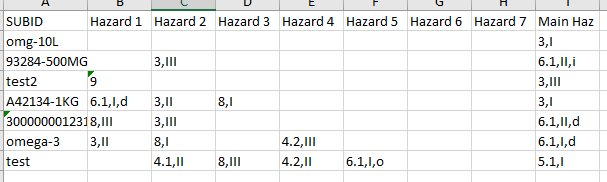
The yellow items in the Main Haz column are my input. value. All the strings with this value should be removed in the same row only.
How can I loop this or handle this?
Hey thx that worked out but I have a little problem I noticed. Is this also possible to do with wildcards? it would be better for me to remove everything from a column that begins with the matching number so my Main Haz column would be like
So the WF should delete every cell entry that matches the number in the Main has column. So how can I use wildcards here?
for instance: 3 should delete 3,III and 3,II and 3,I
you could use regex nodes for that (e.g in string manipulation node).
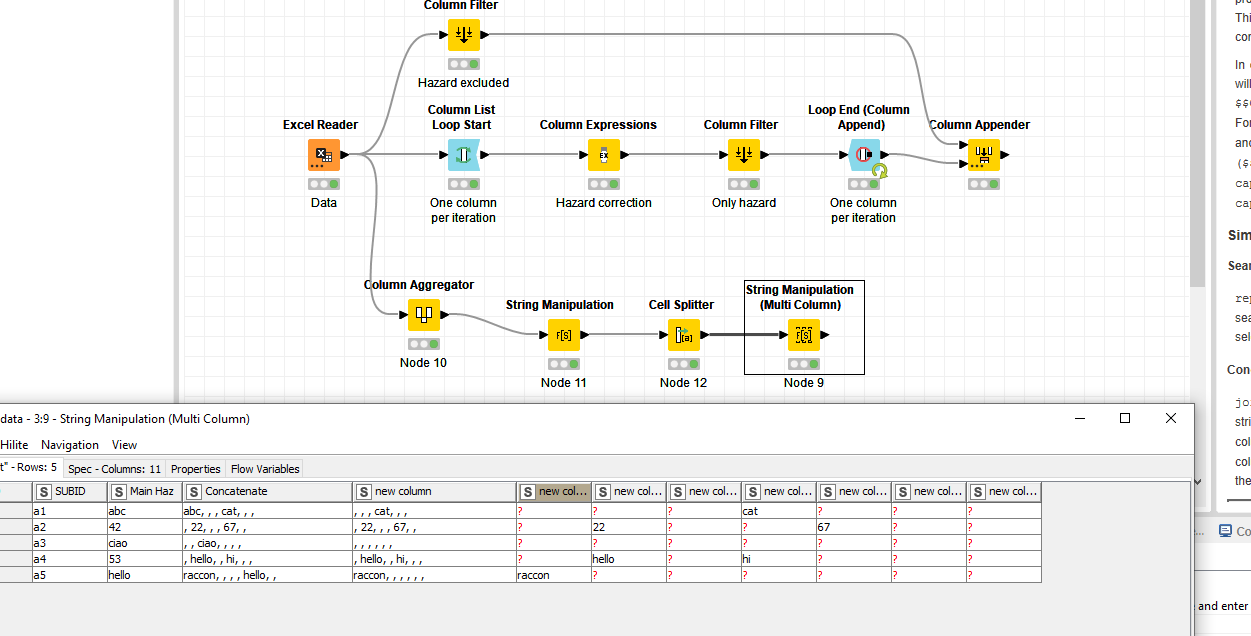
A way to try your work without a loop could be the column aggregator node. (I borrowed @lelloba great workflow for that) Here is an example even if it needs some additional “fine tuning” (e.g. insert column headers and column filtering)
br
Daniel’s suggestion to avoid loop is correct and would lead to an increase in efficiency. I don’t know how big your dataset is: if you think it could be useful to be more efficient, we can change strategy and help you recreate a new workflow. Thank you @Daniel_Weikert for the advice!
I have updated my previous workflow. The v2 works with regex and looks for the number before the comma (ex 6,I → 6).