Hi @Knimer17
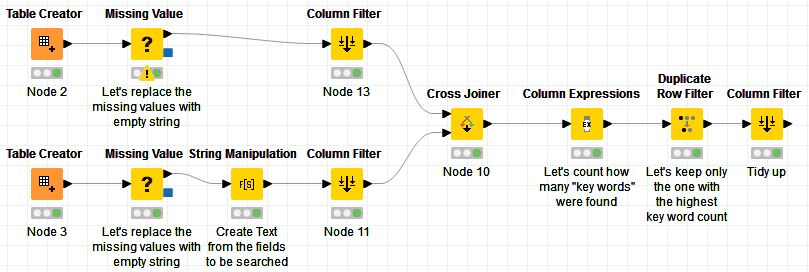
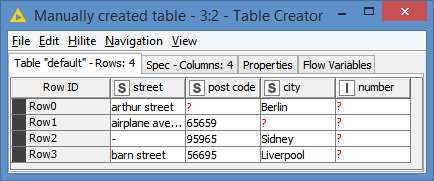
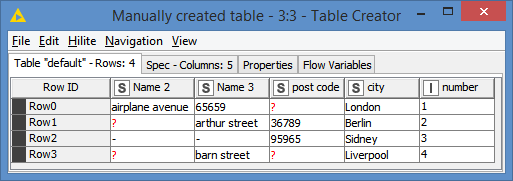
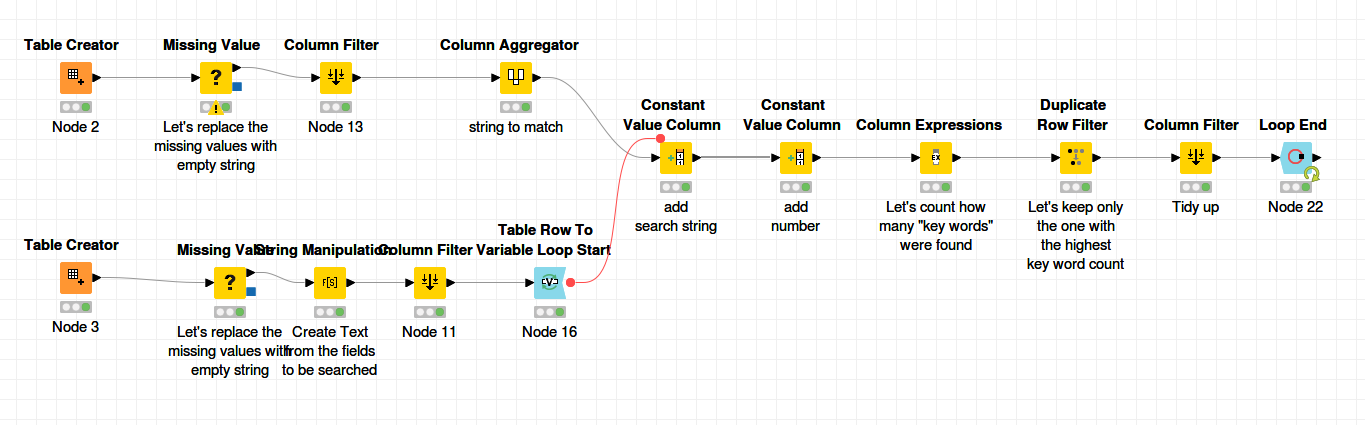
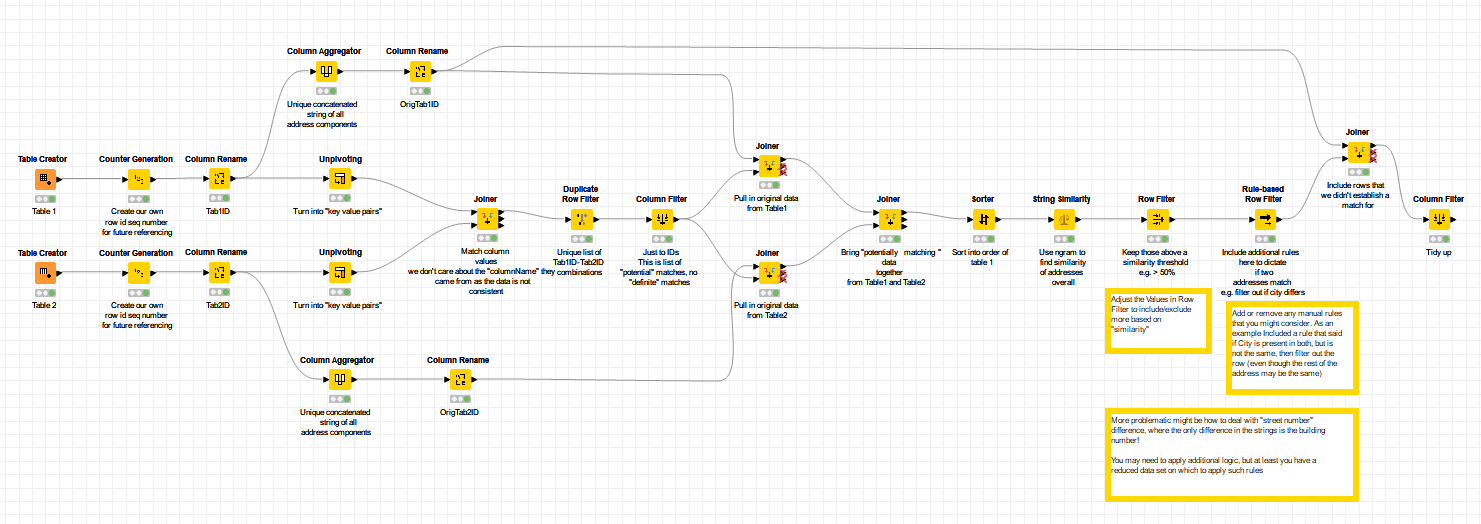
I made some assumptions that we couldn’t easily tell which data columns would be matched, and so effectively decided to find all matches between all columns and all rows. However this shouldn’t be quite as painful as it sounds, as it first of all unpivots your data into one long table of “address component” values for each table, and then finds the potential matches.
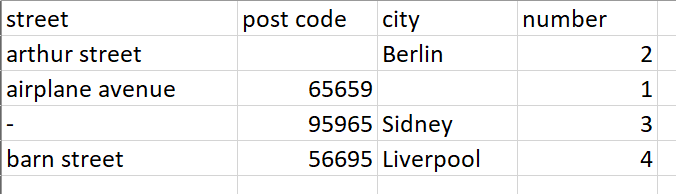
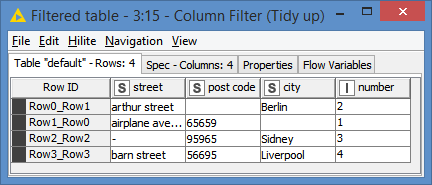
After this, it reassembles the tables based on the possible matches between columns, and performs a “String similarity” on the address as a whole for each “matched” address. It then filters out to give only those addresses which match above a certain threshold.
This won’t necessarily give you exact answers, but at the far end you should have a dataset containing a set of possible matches which you could apply further rules to should you wish to improve the accuracy. You can also adjust the threshold level for a match to be considered (I just arbitrarily chose 50%) .
What comes out at the far end is a “best guess” and it could be that it matches an address in Table 1 to more than one “similar” address in Table 2
I would not expect this to take an exceptionally long time to process 400k records, but it partly depends on how many pieces of address it matches as to whether this fully workable. There are potentially some additional tweaks/refinements that could be added if it doesn’t quite work for your full data set.
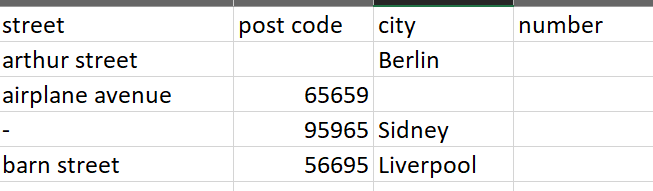
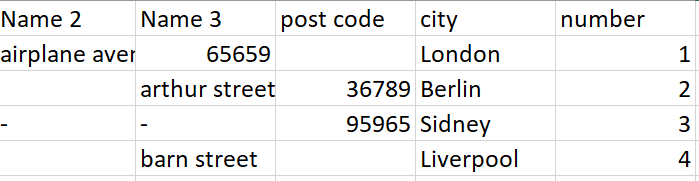
I took @bruno29a 's supplied sample data and added an additional row to check that it didn’t match anything. An area of concern that I noted in the annotation is what happens if an address differs just by building number, or something like that. You’d need to introduce other rules to handle this, but at least the data set at the point where you’d introduce those rules would be more manageable, and you’d just be applying the rules on already partially-matched data. You’d put such rules in where the nodes are above the annotations to the far right of the flow). This could either be by adding to the “Rule-based Row Filter” are adding in further nodes of your own.
Search reference in different columns-takbb 1.knwf (63.1 KB)
At the end, it includes the “String similarity” value (from the String Similarity mentioned earlier by @Daniel_Weikert ) which can be taken as a kind of “confidence level” (1 being a full match) that the addresses are the same:

Edit:
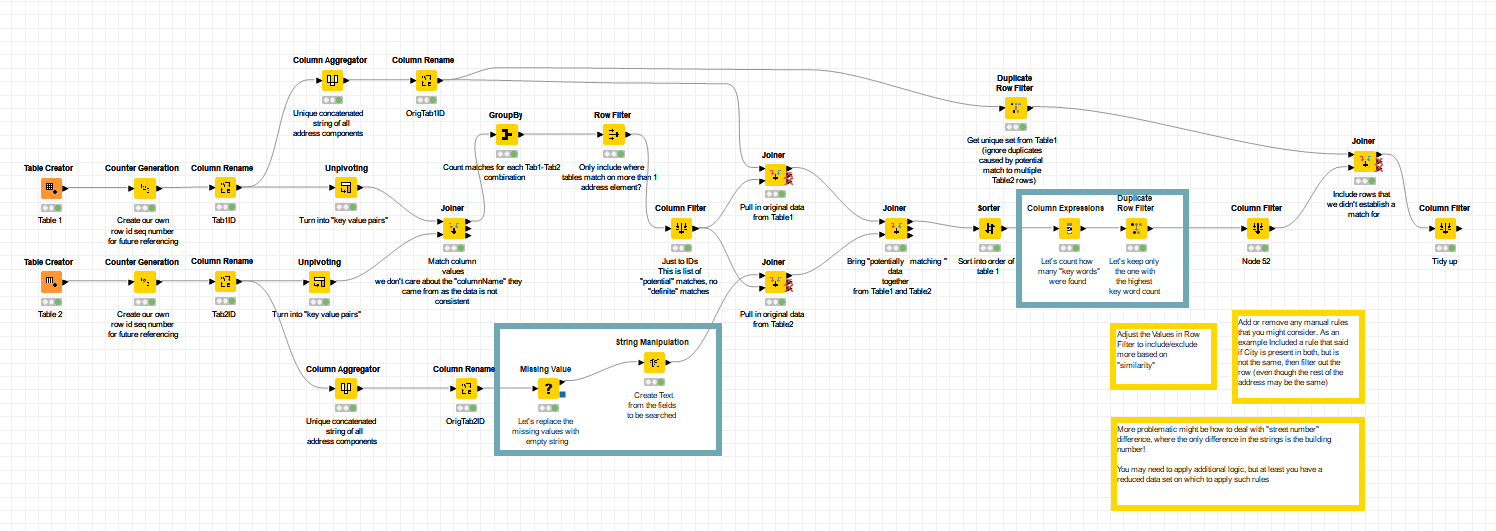
As I posted this, I thought of a small potential improvement:
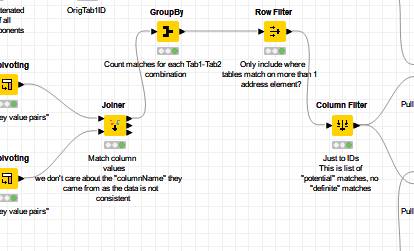
Having found all of the data elements on which the two tables match, maybe we should filter out “potential” matches, where they only had one data value in common? This “threshold” could of course be manually adjusted to suit your needs, but fewer “potential” matches would improve the throughput of the subsequent joins, as you have filtered out some of the “noise”…
Search reference in different columns-takbb 2.knwf (64.3 KB)
[Further edit: fixed small bug in both uploaded flows]