I have a problem when using the dictionary tagger node and I hope that you could help me.
I will explain my approach: In a first worklflow I searched for the most mentioned terms in some pdf-documents. I sorted them according to theit term frequency. After that I chose these terms which are relevant for my project. Then I created an excel list that contains all these terms (terms to string). In a second workflow I started with the exact same data basis (pdf files like before). I implemented my terms out of the excel sheet with the dictionary tagger node. After running the analysis and pivoting the data, some terms show no frequencies anymore (? in the pivot table), although I extracted them from the same data basis as in my first workflow.
And in my pivoting table not all extracted terms out of the excel table are shown. Some terms are left out by no reason.
Long story Does anyone has a hint why some often mentioned terms are “vanished” after using the same data basis and why some terms out of the dictionary tagger are not shown in the frequencies.
can you provide some information on your analysis after using the Dictionary Tagger or provide the workflow, if possible? I’m not quite sure, what you are trying to do and what the outcome of your pivoting table should look like.
I will try to split up my problem: I am searching documents for their most mentioned terms over a time period of 5 years (e.g term1 in year 1 mentioned 12 times, term1 in year 2,…). Therefore I built up my workflow like this:
PDF-Parser (for each year) - concatenate - Stanford Tagger - several filter nodes (N chars, Stop word,…) - Snowball Stemmer - BoW Creator - Term to String - TF - Excel Writer.
With this workflow, I got a list in excel with all terms and their frequencies. After that I selected around 100 terms which I want to have.
My underlying problem now is that I do not know where in my workflow I have to position the dictionary tagger. I tried it after the Snowball Stemmer but at the end there are still all words. But I only want to have the terms from the dictionary tagger as an output.
I hope it is understandable so far
yes, I think I know what you mean. It depends on the terms in your Excel file. Since you’ve got a list of stemmed words (due to the Snowball Stemmer), it definetely makes sense to place the Dictionary Tagger behind the Snowball Stemmer. Another node that might come in handy for you is the Modifiable Term Filter. It removes all terms from your document that are modifiable. Tagger nodes have an option to make terms unmodifiable, so I’d recommend to turn the option off for the Stanford Tagger (because this node is tagging everything and making everything unmodifiable) and turn it on for the Dictionary Tagger. So after using the Modifiable Term Filter, there should only be the words left in your documents that you have tagged with the Dictionary Tagger.
Another issue that often comes up: Go into the node dialogs of your preprocessing/enrichment nodes (Tagger, Filter etc.) and check the Replace/Append column option. Sometimes the append option is checked and the user still uses the original column in the succeeding nodes instead of the preprocessed/enriched document column.
Hello @julian.bunzel!
Thank you for your support. Now it works. Only my terms out of the dictionarry tagger are shown in my pivot table. Thank you once again!
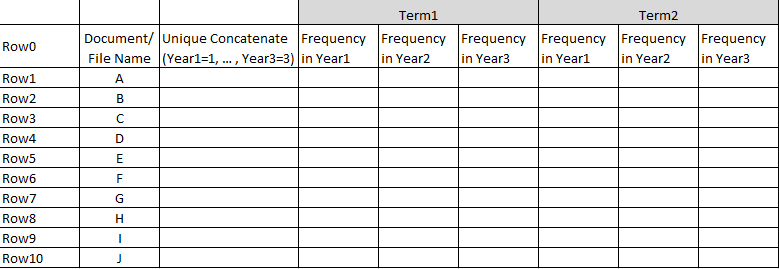
Another question: Could you help me to create a pivot table that looks like this?
I posted this some days ago but got no answer. In my pivoting node settings I chose file name as groups, term as string as pivots and as aggregation method the sum of TF. But how do I get for each term the frequency in year 1, year 2,…?
your approach seems to be good so far. How do you know the year of the document/file? Do you have a dedicated year column? If this is the case, you can use the Year column and the Term as Strings column as pivots.
Set the column name on the bottom of the configuration of the Pivoting node to Pivot+Aggregation column and check the Sort lexicographically box. The columns will then probably be sorted by year, so you might resort them afterwards, if you want to have them sorted by term (like you have it in the example table).
after some playing around, it finally works. Thank you very much for your support!!
I have a last small question: The first step in text processing is “IO”. What does IO stand for if it is written out?