I’m struggling with my data. Here’s an example of what I am trying to do:
col1 | col2 | col3
red | yellow | blue
red | blue |
blue | blue | yellow
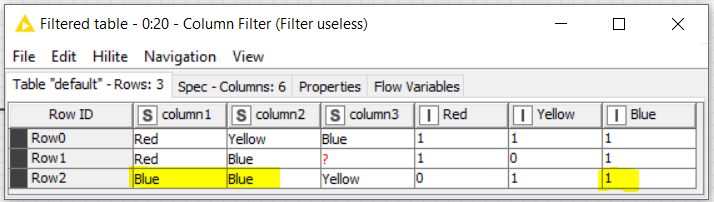
I’d like to have word counted:
col1 | col2 | col3 | red | yellow | blue
red | yellow | blue | 1 | 1 | 1
red | blue | | 1 | 0 | 1
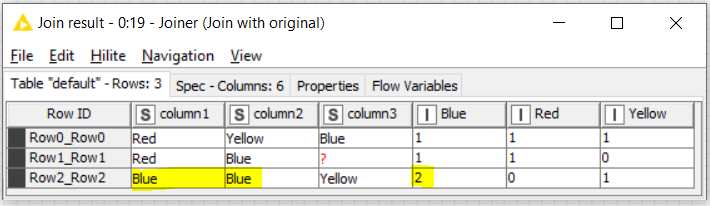
blue | blue | yellow | 0 | 1 | 2
I don’t know a priori the colours in the original table. So I need to search for the word, put it in a column, ccheck if it is in the row and once all rows are checked, I need to find the next word and so on…
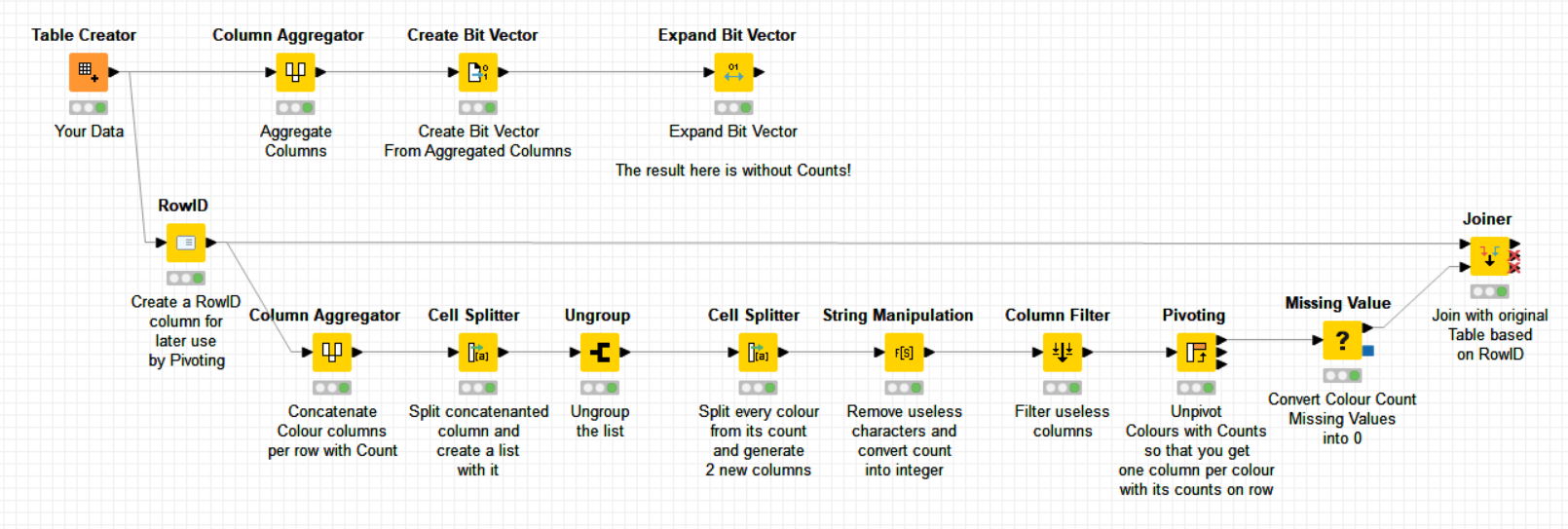
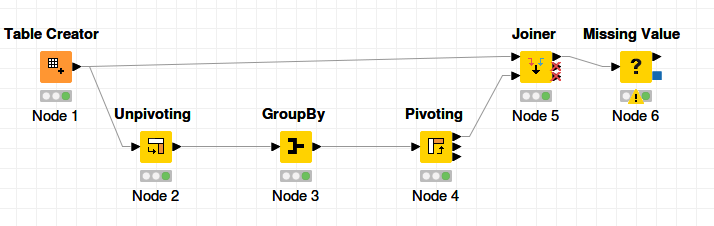
Interesting question. Below you will find a possible solution. The first branch provides a simpler solution but without counting the occurrences of colors per row:
The solution I have uploaded is generic and it does not care of the different number of colors or the number of columns to take into account. It should hence be generic.
The solution is involved although it does the job. I would be curious about a simpler solution for this interesting problem.
@HansS is shorter and simpler so the best solution. I should have thought of it !
Just a possible improvement to @HansS’s solution. If you want to make it generic, you will need to add to it the regular expressions I’m using in my workflow for column selection in the node configurations. Otherwise, it will only work for the given number of columns.
 !
!