I have following problem, I need to segment players based on specific KPIs on a percental split.
So I get buckets with low, medium, high, with the size of 60%,30%,10% of the sample depending on the KPI.
I’m not quite sure what would be the best approach here, I kind of found some workarounds with using an auto-binner and just creating 10bins, the first six, mid 3 and top 1 but as I have to do this for 20+ KPIs it will be pretty tedious.
Is there an easy way I didn’t think of yet?
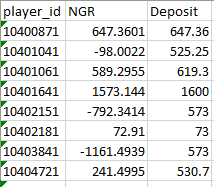
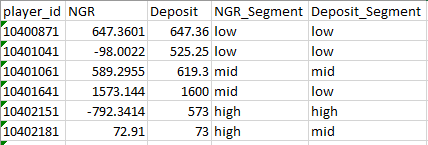
Goal at the end is to go from this:
to this:
(segment column is only filled exemplary of course)
I’ve attached a sample file in case it’s needed.
I would be very grateful for any help Thanks!
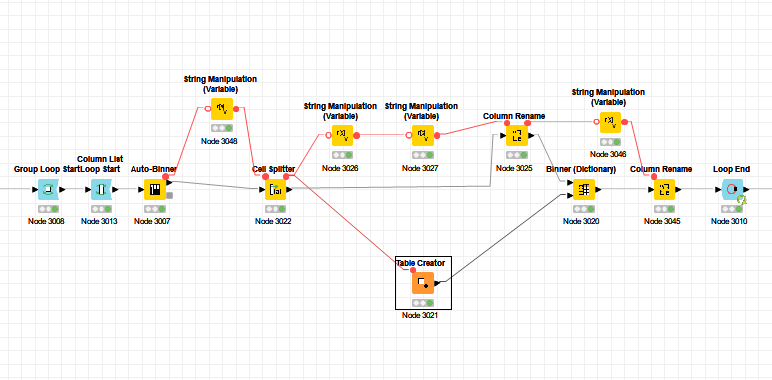
Could you attach your workflow and explain what part is tedious? I think if you have a set up with flow variables and/or loops, this can be automated. But I’m curious to see what you did in the workflow and with this sample data.
I’m running through each column that needs the binning (group loop is because the dataset needs to be segmented by country) I segment into 10 bins, then assign Bin 1-6 as Bin 1 , Bin 7-9 as Bin 7 and Bin 10 as Bin 10 with the second Binner. That’s how I get the uneven split.
It works so I am not too mad about it, but I also need to know the limits for the bins, is there a way to extract it? I see that there is a port for the PMML model fragment which should that information but it doesn’t seem like I can extract that data.
And additionally - How can I now segment the customers based on all the thresholds I assigned through the bins?
So let’s say I have 5 columns with doubles and one with a boolean and I want to define my bins by all 6 of these values. Again into 60%, 30% and 10% group based on their “performance” And then see what the limits for each KPI is
I couldn’t find a way to get the information about the bin borders from auto-binner, but since you’ve already segmented, couldn’t you get the min and the max for each bin you have (bin 1, bin 7 and bin 10) using groupby?
I’ve tried using the group by method but it doesn’t seem to work correctly as I get a different number of entries per criterial. And technically it should always have the same spread. That’s why I wanted to confirm what the limits were.
Perhaps the GroupBy node requires different configurations? I’ve not seen the groupby node not work before. Can you share a workflow with dummy data perhaps?
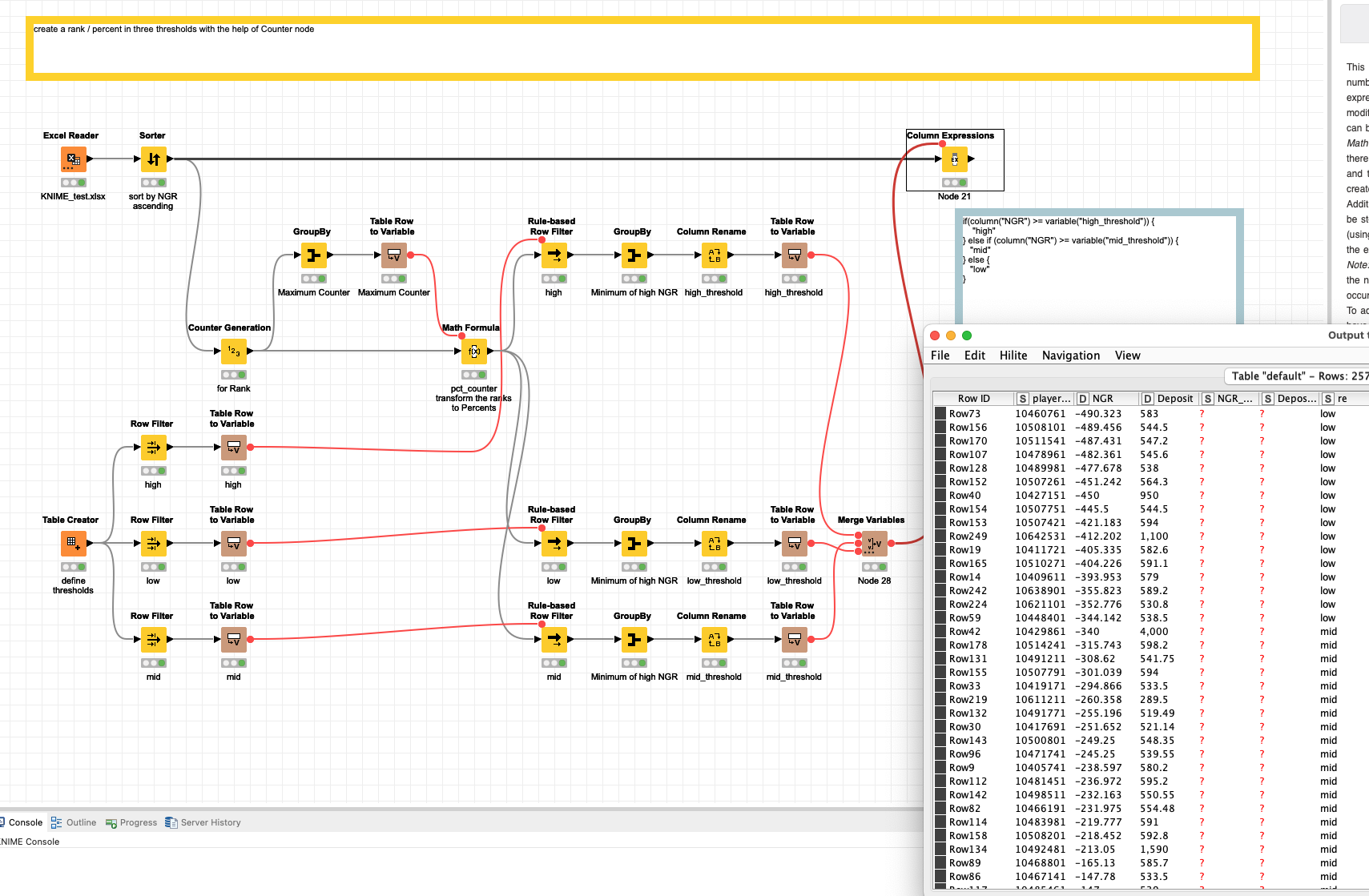
@Chaosprinzip I think you could employ a counter and produce a rank and then get the thresholds for high, mid and low.
My problem is that it seems the case is not well defined. Are we talking about a rank or would the 60% be from the total amount of the value column? Maybe you could explain that further.
Here is a quick and dirty approach to use a Counter to create a relative Rank and automatically determine the threshold of the NGR column. But I think it needs a more clear definition from your side: