@aworker: Tanks - works as it should and this “extract column header” avoids the really slow execution of the transpose node (I always wonder why is this simple operation so slow on larger tables - it is only re-indexing?)
Thank you @pigreco. works fine, I wrote in another reply: Still wondering about the slowness of the second transpose (about 45 seconds on a 6 Kernel MacMini - with my data 10000x250 table). The first transpose is fast enough.
@armingrudd: this is quite cool, to build the regex automatically - good for implementing in a parametrized workflow.
@HansS Ha! You are so right - didn’t see this. It is hard for my Mathematica-brain to “program” such simple tasks as a column selection. 
1 Like
@andrejz: Thanks to you, too. Also a quite cool solution - I learned something
Hallo @mgamer
Vielen Dank für Ihre freundliche Antwort.
The internal data structure of tables in KNIME has been optimized to work fast on column operations where the number of rows per column can be very high. This is why most operations in KNIME are column based and for instance operations between cells across columns and rows are often complicated. The way cells are linked each other in KNIME has to be completely re-structured when transposing a table. This is why it is slow at this task, merely because there is a lot of data structure reorganisation. This is not the case in Mathematica or in Matlab where the structure of numeric matrices almost match the organisation of data in RAM memory making the cell access and transposition of matrices very close to a low level memory or CPU operation. There are though tricks or shortcuts that can be sometimes applied to make matrix operations in KNIME faster without having to go for instance through a KNIME loop or java/Python/R node solution.
If you want to know more in detail on how KNIME handles table cells, one possibility is to have a look at how to create new KNIME nodes in java. How tables are precisely organised in KNIME can be understood from the java code :
https://www.knime.com/developer-guide
Hope this sheds a bit of light. 
Viel Glück und Grüße aus Toulouse
Ael
2 Likes
Hi @aworker,
Vielen Dank - das ging ja schnell. 
Thanks for this insights, which makes things clearer to me. I’m having a look at the implementation - but this is not my main interest. I’m using KNIME to do Machine Learning with my students and use it for me just to verify results I got with Mathematica (always better to have two (or more) sources). But the more one uses KNIME and one gets more familiar with it, it shows that this is really a valuable and mighty tool. Besides this it is quite easy to use, too - if you know theses tricks like in the answers here.
Herzliche Grüße aus Hanau
Michael Gamer
2 Likes
Hallo Michael
Vielen Dank
Indeed as in any language, knowing the tricks helps a lot . I fully agree with your comment about KNIME (specially for teaching) and having two or more sources. The nice extra thing of KNIME is its great community - people like @armingrudd always willing to help with really amazing tricks and workflows, as you have experienced here. KNIME summits in Berlin are also great to meet all these people !
Herzliche Grüße
Ael
4 Likes
Hi @mgamer
I want to suggest another solution. With the Extract Table Spec node it is not necessary to do a Transpose first to select the column-names (saves a lot of time with a large dataset). You can directly make a selection of row (using Sample node or Rule Engine node or …).
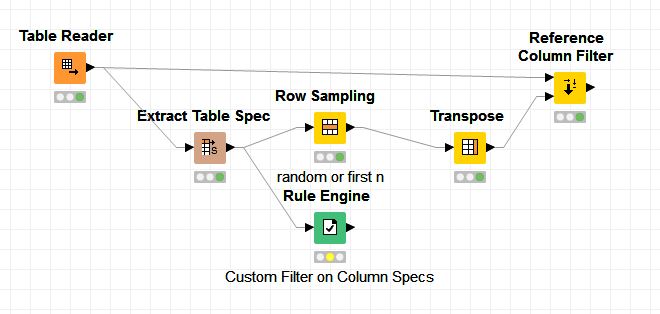
gr. Hans
4 Likes
Hi there everybody,
just to add info. Have added this functionality/request it into existing ticket (Internal reference: AP-14092) from this topic: Combined column cleaner/selecter tool [proposal]
@armingrudd this is what I had in mind
Br,
Ivan
2 Likes
@HansS Thank you for this hint - looks good and is easier than before
1 Like
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.