Since I want to have ALL results from the Job portal I just need to click on the "Search" Button.
I tought I just need to use the "Click" Node, but then the error "No suitable column for ws.palladian.nodes.selenium.tyes.webElementValue found" appears.
you'll need to connect a "Find Elements" node first, where you get the "Find" button on which you want to click. After the "Find Elements" node you can select the "Click" node.
Now I want to collect all links to the singular jobs. But to have all items I need to go to the next pages by clicking the ">" to show the next page of results.
How can I realize this?
I triedthe "extract attribute" Node with the attribute //a to select all links but then the error "Element not found in the cache - perhaps the page has changed since it was looked up" occurs.
for collecting results from paged lists, you can use a loop using loop start and end notes and then iterate through the single pages and collect your results, then click on the "Next" link. The end node will then output all collected results. For an example about the general idea, have a look at the Facebook workflow on the examples page.
Important is, not to click on any elements which are not present on the page anly longer (i.e. after a page reload). So perform the "Find elements" in each loop iteration and not outside of the loop.
Hi, I've checked the Facebook Workflow. It definitely helped me for unerstanding the general idea.
I'm still a little bit in trouble with selecting the right query.
So before I'm starting with the Loop I want to select all job links on the first page. I thought it is something with "contentunder" but it is not working.
ok, with "contenunder" it works, but there are always 2 links for one job item (the ID and the Name are links to th job site). How can I choose one of these links?
And how can I extract the singluar jobtitle to the links.
in case you cannot drill down using the element itself, because the query would be too generic (in that case the a.contentunder), try to expand your query to take the parent elements into account. In your specific case something like this (CSS selector) will do the trick:
table.gitter tr[valign="top"] td:nth-child(2) a
Explanation: Selects links (a) which are contained in a td element which is the second child (i.e. second column) of a table row (tr) within a table with the class "gitter".
In general, the same can be achieved with an XPath expression using a different syntax, depending on your personal taste :)
Thanks for all your earlier help on various questions.
I’m new to KNIME and haven’t figured out some things quite yet.
I have developed a webscraping routine on KNIME which needs to traverse through multiple pages (each page has multiple catalogue elements)
The issue I’m having is -
When the loop runs for a single page, it gathers information for 120 elements, after which if I find the “next page” button and use the “click” node, it appends the next page button’s xpath to each row, after which the click button is pressed 120 times.
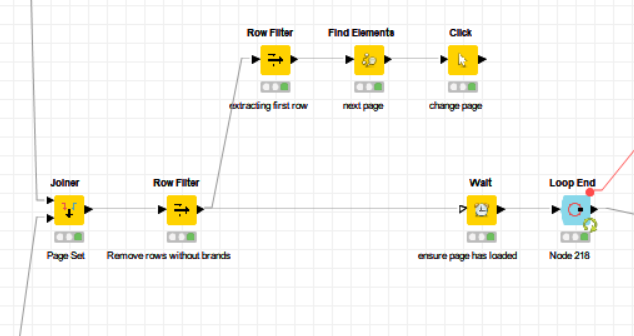
I tried splitting one row away from the main workflow into the page switcher, but I cant join it back to restart the loop of the pages as KNIME assigns missing values in even outer joins if there is no match.
Is there a way to execute this properly? (only click once irrespective of number of rows in the table)
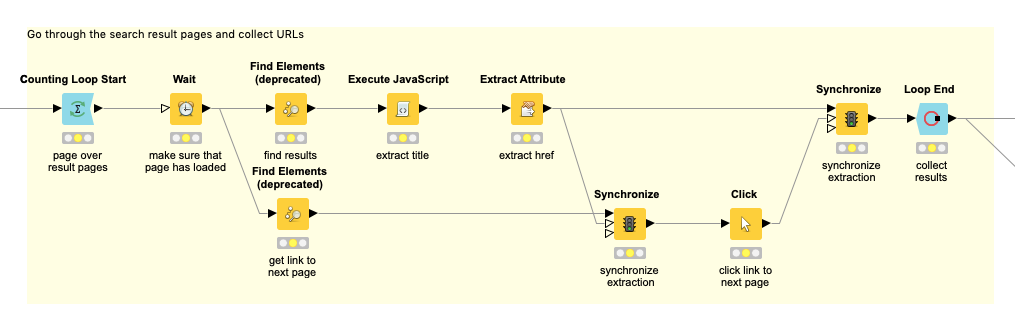
I’d recommend to create two branches, one for extracting your results, and a second one for just extracting the pagination. You can then first extract all the necessary information, and afterwards perform your click. This requires some synchronization, to make sure the click is just performed after all your results have been extracted.
Here’s an example how this might look (this is an older workflow, so don’t be puzzled that the Find Elements node is deprecated here):
Pro tipp: You can also avoid the Synchronize nodes alltogether and do your temporal synchronization via flow variables. This reduces clutter in your workflow with Synchronize nodes. I don’t currently have an example at hand, unfortunately.
Hope that helps – in case of further questions, please let me know.
Thanks Philipp, this is exactly what I was looking for! - just wasn’t aware of the synchronize node yet.
In the meanwhile I had created a makeshift workflow using a wait timer and an un-linked branch, which also works fine but is unreliable. Now I can switch to something similar.