I’m trying to pull review data from a site and the loop keeps repeating the first-page content.
What am I missing?
See the attached workflow.
Thank you.
Howtogetallpages.knwf (42.4 KB)
I’m trying to pull review data from a site and the loop keeps repeating the first-page content.
What am I missing?
See the attached workflow.
Thank you.
Howtogetallpages.knwf (42.4 KB)
Works for me. What’s the issue, exactly?
Apologies: Got it, the second iteration extracts the same results as the first one 
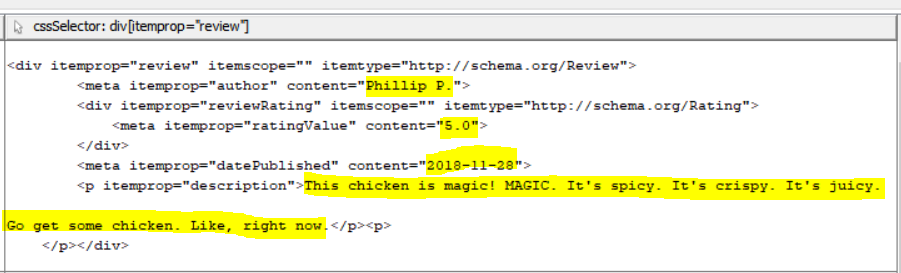
I’ve had a look at the Yelp website, and the peculiar point is, that they keep some of the review information in a visually hidden section – this is intended for search engines and not shown to the user. This information will remain constant, and always show the 20 first reviews, even when you use the pagination links. (the fact that this information is within <meta> tags gives a good indicator, that it’s not meant for human consumption.)
I’d thus suggest to change the query in the Find Elements node to div.review – this will correctly address the visible <div> elements on the page.
If I have some more time later, I’ll post an updated example workflow.
Thanks, Phillip.
I can use a little more help if/when you’re able to.
I can extract the div content but how do I extract sub components?
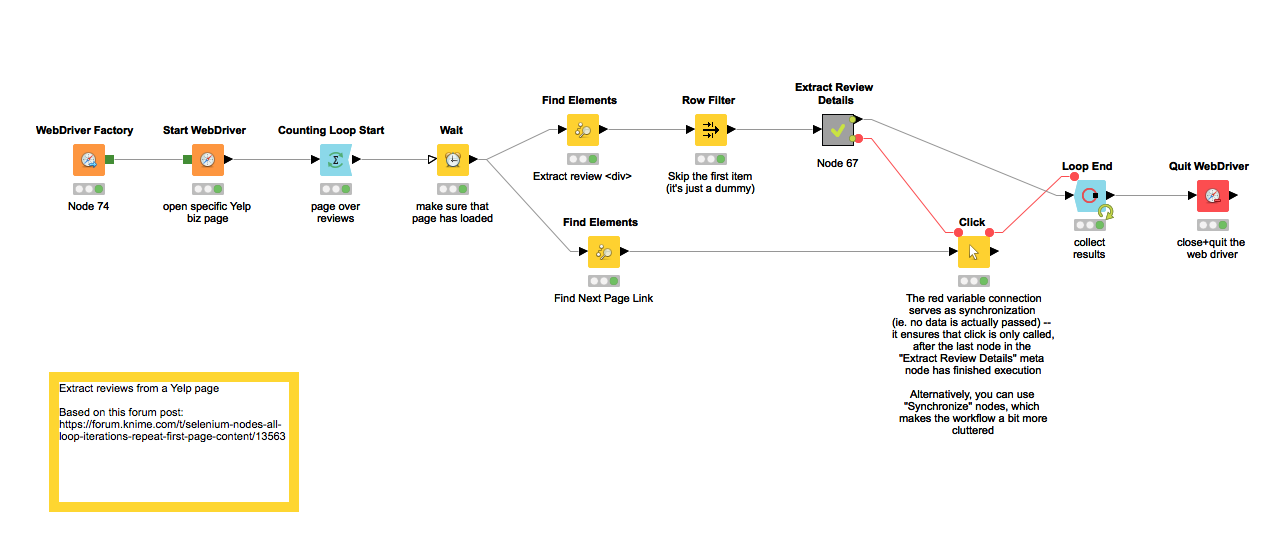
The general strategy is that you use follow-up Find Elements nodes, which operate within the <div> which you have extracted before (technically speaking, the Find Elements node allows either a WebDriver or a WebElement column as input). I’m attaching a fully-working example workflow (please also check the comments):
Some general remarks:
Yelp_Review_Scraping.knwf (26.6 KB)
This works beautifully, thank you.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.