The general strategy is that you use follow-up Find Elements nodes, which operate within the <div> which you have extracted before (technically speaking, the Find Elements node allows either a WebDriver or a WebElement column as input). I’m attaching a fully-working example workflow (please also check the comments):
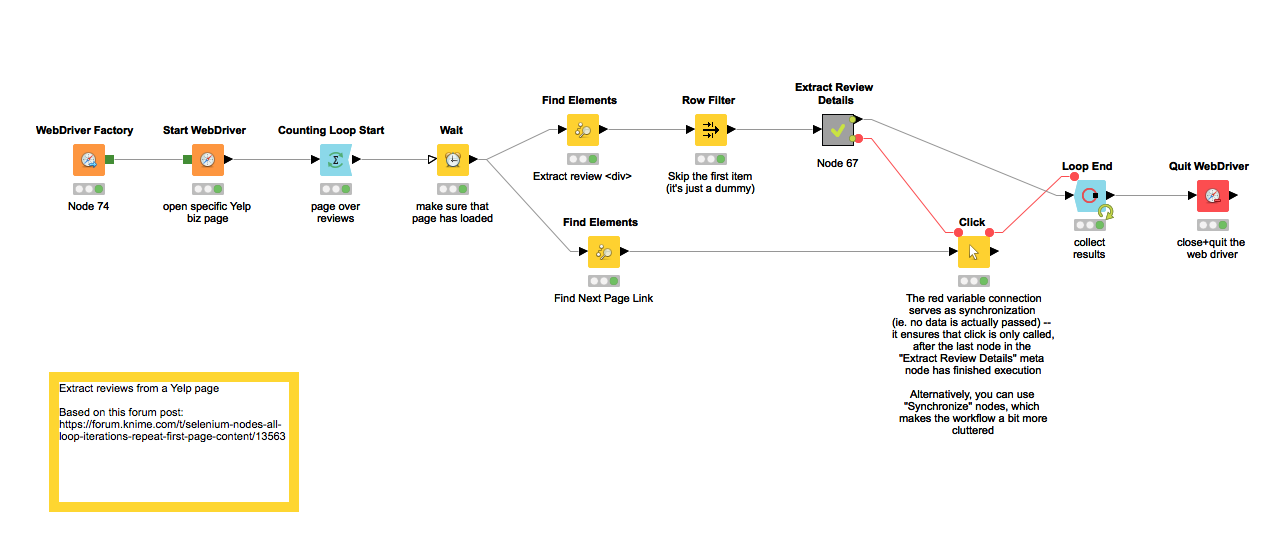
Some general remarks:
- I changed the initial query in the first Find Elements as suggested above
- I added a Row Filter to skip the first element which is just a no-content dummy
- Instead of the Execute JavaScript node I used the dedicated Extract InnerHTML and Extract Attribute nodes. This is faster than the JavaScript way.
- I replaced the Synchronize nodes with flow variables. The result is the same as with the Synchronize nodes, but the workflow is cleaner (we still keep the Synchronize nodes mostly for didactic reasons, as it might be easier to understand for people who haven’t used FWs before
 )
)
Yelp_Review_Scraping.knwf (26.6 KB)