Hi Phil,
as discussed yesterday, some input here. First straight to your question, then describing the rabbit hole into which I fell when playing with the data. Maybe it sparks some more ideas 
Scrolling Sections
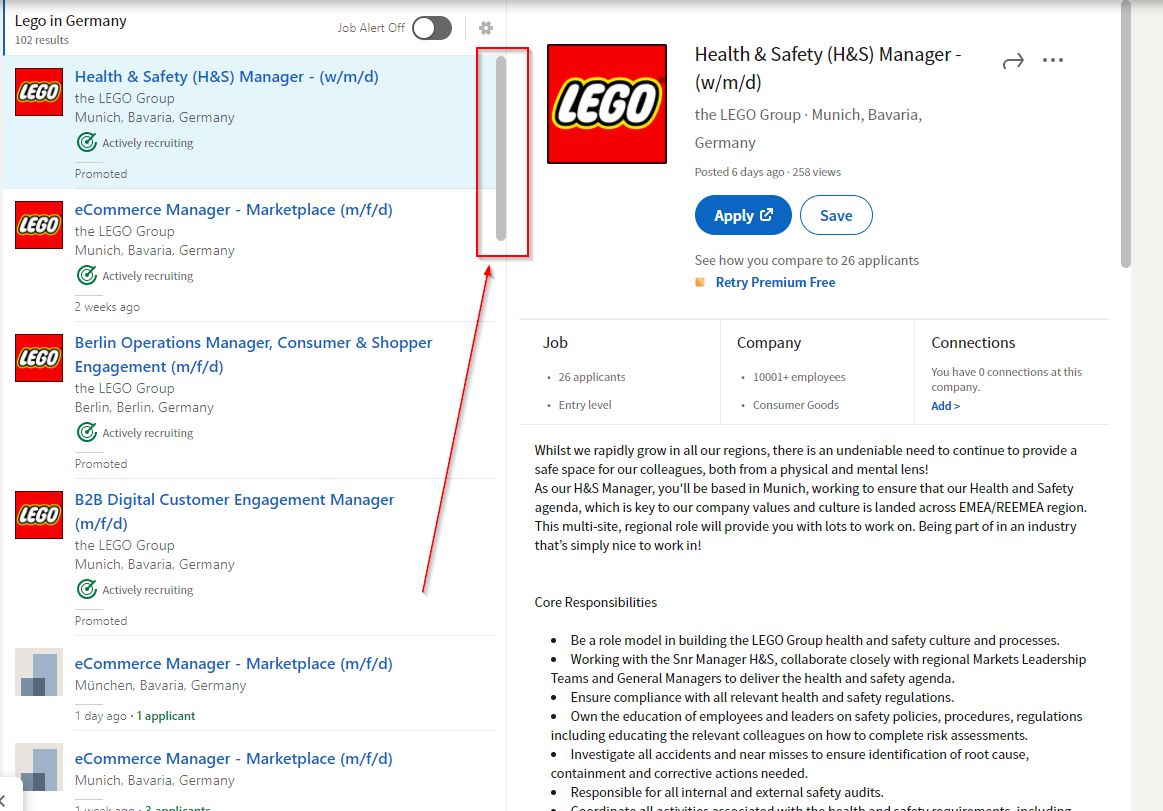
As you highlight in the screenshot, the scrollbars on this page only apply to specific sections (technically, these are <div> elements which are vertically scrollable).
In the Facebook example, we could scroll the entire window, which works as follows (using the Execute JavaScript node):
window.scrollTo(0, document.body.scrollHeight);
In contrast to that, we first need to narrow down the scrollable element on LinkedIn (i.e. the section which shows the scroll bars). I do this with a Find Elements node where I get the element with the .jobs-search-results class. Then I pass it to Execute JavaScript, where I scroll this element (instead of the document):
/* This is the element passed from the previous Find Elements node;
* I have selected it in the left column here. If I select a second,
* third, … element, they would be available as arguments[1],
* arguments[2], …
*/
const element = arguments[0];
/* Determine the hight of the element (includes height exceeding
* the current screen height
*/
const amountToScroll = element.scrollHeight;
/* Use the previously determined height to scroll */
element.scrollTop = amountToScroll;
Loading More Results
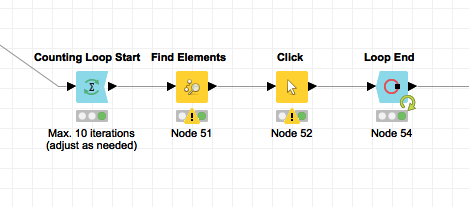
This works fine. At least the scrolling Unfortunately we’ll not get more results this way  Instead we have to keep clicking a “Load more” button to load more results. So instead to what I described above, I built a loop which would continuously click that button to load more data (below example is rather dumb, it will just try to keep clicking, even though there are no more results – but never mind it works!)
Instead we have to keep clicking a “Load more” button to load more results. So instead to what I described above, I built a loop which would continuously click that button to load more data (below example is rather dumb, it will just try to keep clicking, even though there are no more results – but never mind it works!)
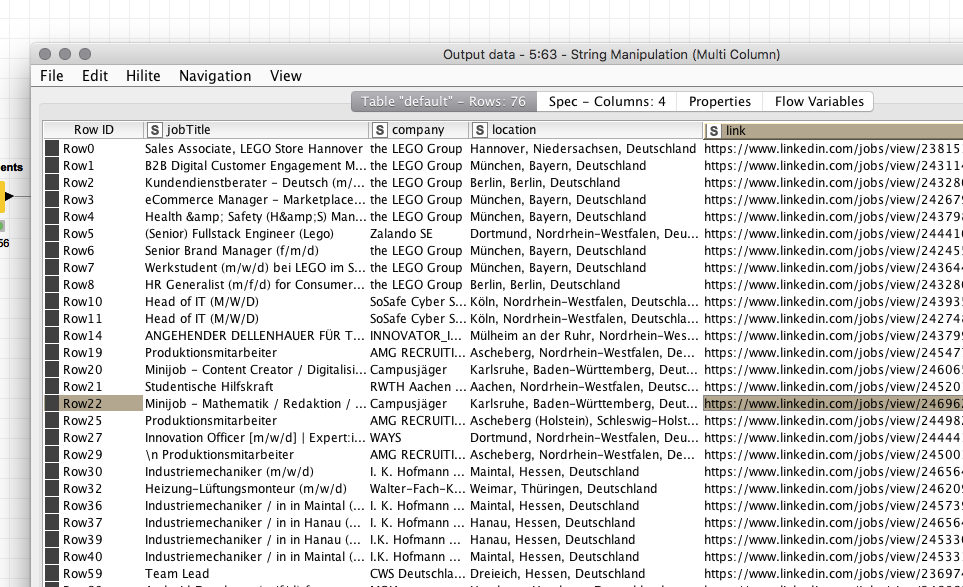
Adding some more Extract Attribute and Extract Text nodes, and some post processing using a String Manipulation (Multi Column) node I end up with a nicely extracted and structured job listings table with Lego jobs:
(Bonus) So, Where Are All These Jobs?
Looking at the “Location” column, I thought that this would be a great use case to do some spatial analysis. So let’s show the job offers on a map! The Palladian Location Extractor will allow us to transform the location strings to latitude/longitude coordinates (and it even has some magic, aka. “disambiguation” built-in for properly detecting, if “Paris” is about Paris in France or Paris in Texas – a while ago I even wrote a dissertation about this topic, but this is yet another rabbit hole which is fortunately closed now  ).
).
To use the Location Extractor, it’s necessary to set up a “Location Source” in the preferences (this is the database which is used for looking up the location data). You can use the free “Geonames” which allows 30,000 requests per day for free. (more information is shown in the node documentation, and we even offer a paid alternative for people who don’t feel comfortable sending their data to a public web service.)
After running this, and doing some filtering to only get the city names (e.g. not the regions or countries), I can then visualize the companies offering Lego jobs on the map.
I have shared the workflow on my public NodePit space (can definitely still improved, consider it a PoC for now ):
Have a good weekend,
Philipp