Hi,
Based on the Selenium_Yelp_Review_Scraping, I am trying to scrap Tripadvisor review. Find Elements did append 1 row. But nothing appended beyond that.
Any advice? Thank you.
Regards - Faiz
Selenium_Review_Scraping.knwf (667.9 KB)
Hi,
Based on the Selenium_Yelp_Review_Scraping, I am trying to scrap Tripadvisor review. Find Elements did append 1 row. But nothing appended beyond that.
Any advice? Thank you.
Regards - Faiz
Selenium_Review_Scraping.knwf (667.9 KB)
Hi Faiz,
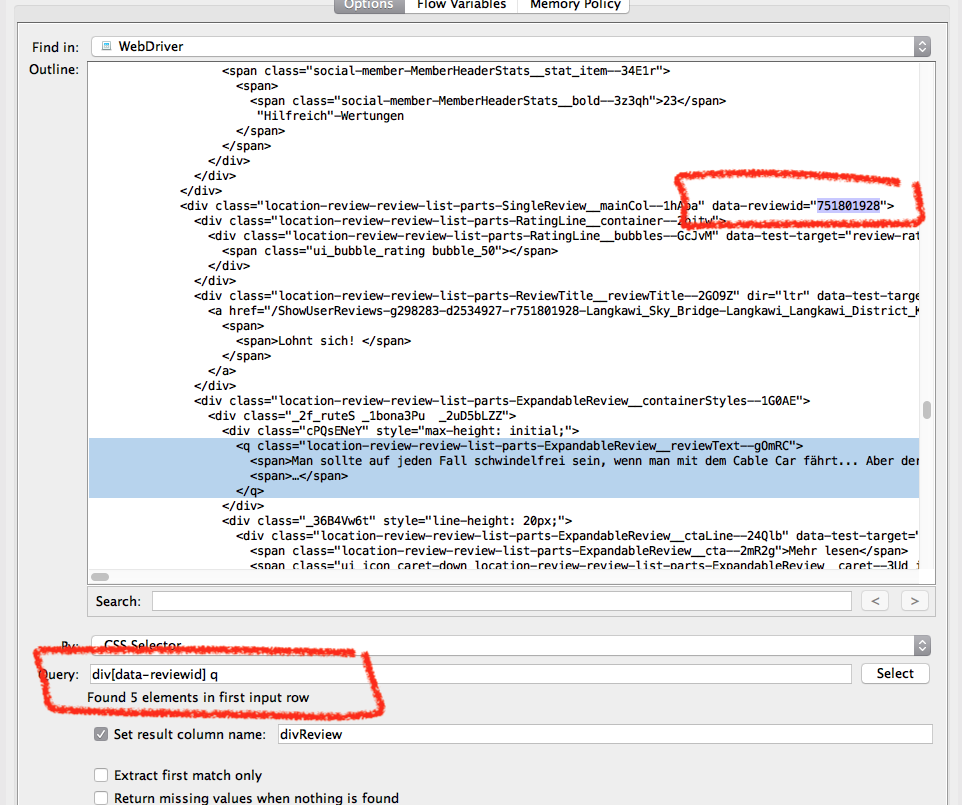
the current CSS selector will only extract the first row, b/c it is too specific:
:nth-child(3) > .location-review-review-list-parts-SingleReview__mainCol--1hApa > .location-review-review-list-parts-ExpandableReview__containerStyles--1G0AE > ._2f_ruteS > .cPQsENeY > .location-review-review-list-parts-ExpandableReview__reviewText--gOmRC > span
The automatically generated CSS selectors are built in such a way that they match the item which you click in the browser, but nothing else.
To make it work for all entries, you will have to modify it in a way to be more generic. The site’s class/ids attributes are not very “scraping friendly” – e.g. for location-review-review-list-parts-ExpandableReview__reviewText--gOmRC, the last part gOmRC will probably change every now and then, so you shouldn’t rely on this.
Looking at the DOM, there are some other “anchor points” which you can leverage:
I would suggest to extract the ancestor <div> with the attribute data-reviewid="XXXXXXXXXXXX" (note that the attribute value has some unique ID, but this doesn’t matter, we will jsut check whether the attribute is there, which should thus be more “robust” to changes) and work “downwards” from there. You can do this using div[data-reviewid] (which reads “a div with an attribute data-reviewid”), and from there on you can get straight to the <q> element div[data-reviewid] q.
For the given example, I get five results.
Does this help?
– Philipp
@mfhilmi Any feedback? Did it work?
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.