This forum thread is for questions related to KNIME self-paced course [L3-CD] Continuous Deployment and MLOps. For example, if you need help with an exercise or have some feedback, please post it here!
You can access the course here. This link will direct you to the learning management system.
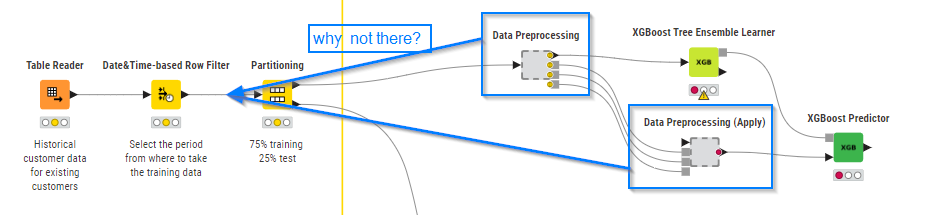
I am surprised that, in L3-CD the trainer predictor workflows do the identical data preprocessing after the partitioning. I feel this will lead to incorrect results, possibly just marginally, if statistical measures are applied. In the exercise part 1 workflow, e.g., there is outlier management. However, the criteria of being outlier or not is purely based on the training set. However, the test set is “recorded” data the same way as the training set. That could lead to rows in the test set being detected as outliers, that would not be classified as outliers if the whole set had been used to determine the outlier threshold.
Thank you for your interest in the course. This thread is the right place to ask your question about the course.
We partition the data before all the other preprocessing steps to avoid data leakage, i.e., to make sure no information from the test set is used in the during the model training (edited). Since we want to build a model that works well on unseen data, we also need to evaluate it on unseen data. Here is a short video explaining the concept of the data leakage.
Thanks for replying that quickly, providing your clip on data leakage. I feel, I will need some time to digest that what I saw as a benefit actually should be/is a flaw.
I have been mulling it over a bit. I do not see in how far applying data cleaning techniques to the whole data set results in data leakage, especially when the techniques result in removal of rows.
Could you expand on that?
It just comes to my mind that the parameter connection from the training cleansing nodes to the test nodes seems to infringe the “no data leak” paradigm, the “no information from the training set is used in the … model … evaluation”.
I just reread my previous answer and I think I indeed wrote it in a confusing way, what I should have written was: “make sure no information from the test set is used in the during the model training”. Let me try to explain in more detail.
What we want to achieve is that the test data plays the role of unseen new data for which you’re building the model and on which you want the model to perform well. Therefore, it is important, that no information from the test data is used during training. Because then it can’t be considered unseen by the model anymore.
If you take the whole dataset to do some calculations, for example, to calculate the quartiles to define the outliers or to calculate min and max to do min-max normalization, you use the information from the distribution of the whole dataset, including the test data, to prepare the data that will be used for the model training.
However, this would not be the possible when you apply the model to the new unseen data (independent on data preparation technique) because this data comes only after the model is trained. Since you want your test data to mimic the unseen new data, no information from test data should be used during training. In this case, during the evaluation, you can assume that the model will perform on unseen data as well as it performs on the test data.
There are rows I1 ad I2, that are extremely close to the threshold, but still good.
We split the data into sets Tr and Te.
O1, O2, O3, I1 go into Tr
O4, I2 go into Te
We do outlier filtering on the Te set. As O4 is missing, it could happen that I1 gets classified as outlier or that O3 gets classified as good. I do not know which will happen, but I do not feel, this matters.
We train on Tr, but we know that the training set is slightly faulty, as either I1 should have been used also or O3 should not have been used. Thus, I presume, that the model will not be optimal.
We apply the outlier threshold of the Tr set to the Te set. It can happen, that O4 will be not classified as outlier or I2 will get classified as outlier. I do not know which one happens, and I am not sure, that this matters, but I feel the performance is not measured as exact as it could.
I guess I just have to accept, somehow, that there is some to me counter-intuitive inherent.
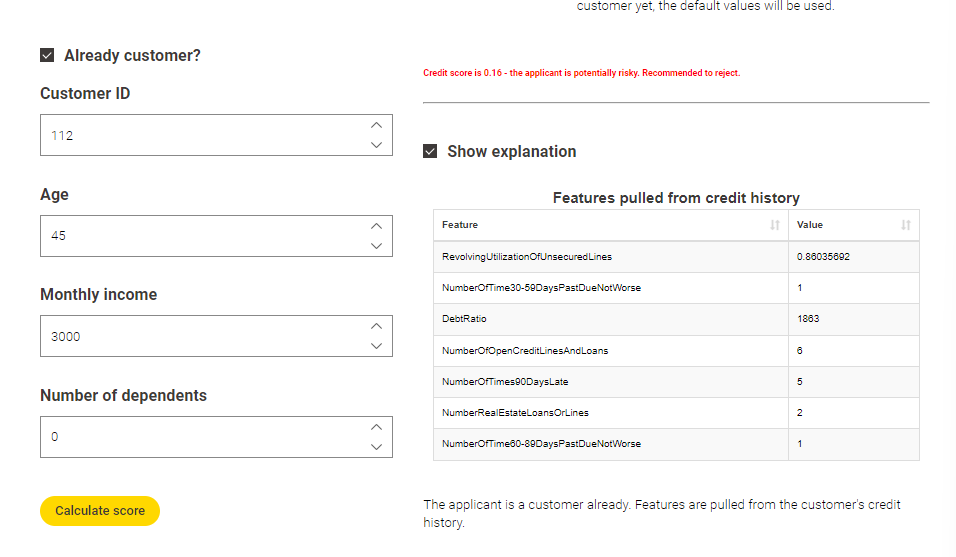
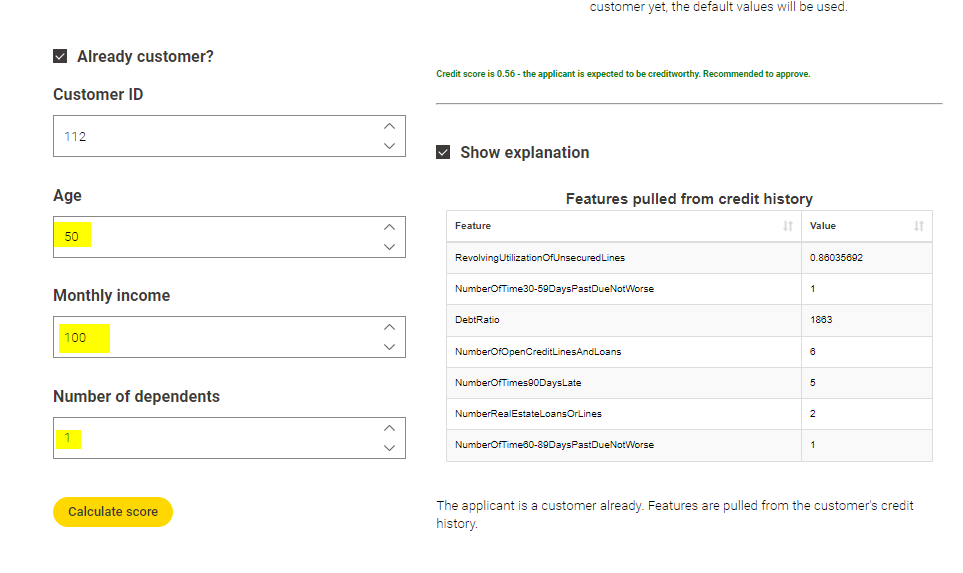
However, I fiddle the input to something, I would presume, that the score would get worse still, but the contrary is the case. Did I do something wrong, or is the model just so funny?
Regarding the question about the model - I think it might be indeed not the best model. The focus in this course is on the deployment, not on the development of the best model, so I guess it might not always behave as expected.
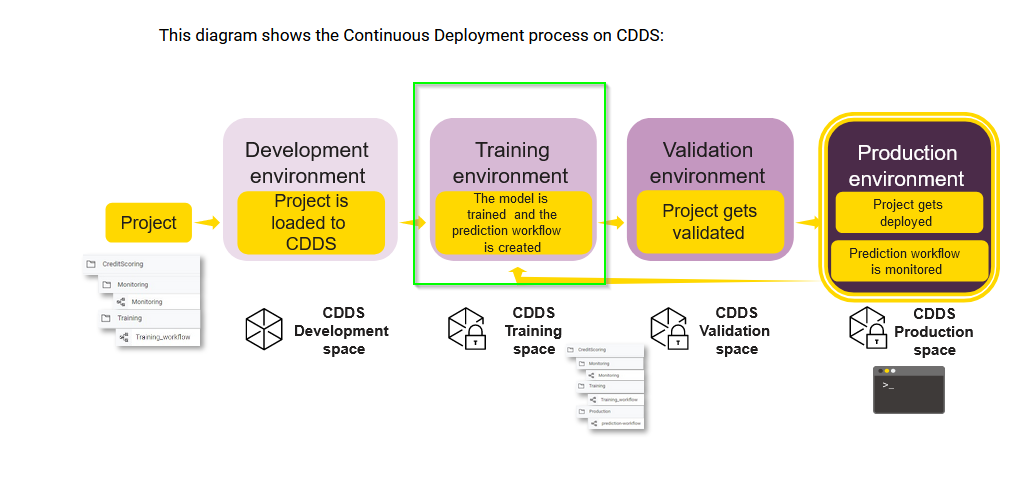
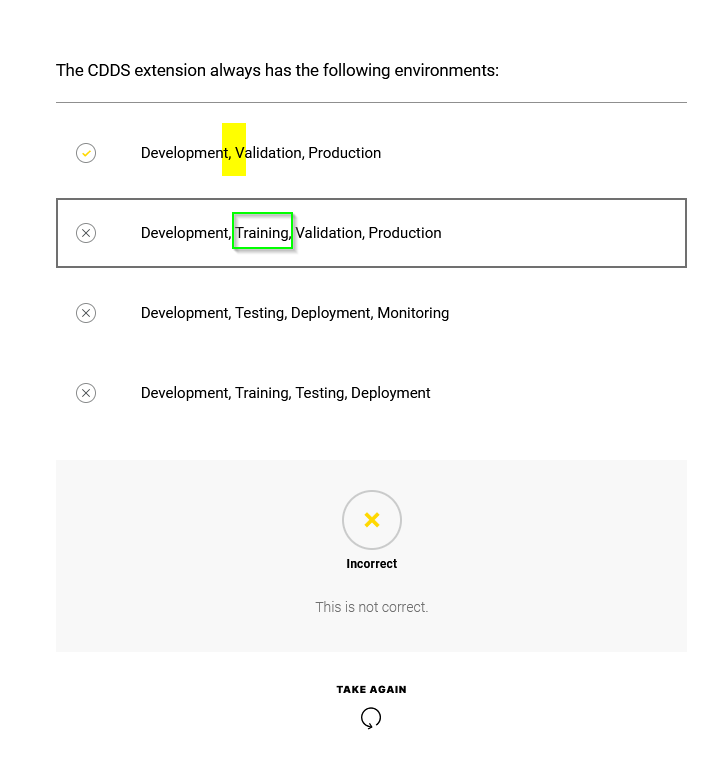
Regarding the question about the Training space always present in the CDDS extension - this is indeed not always the case because the CDDS extension has 3 levels: in the course they are called Simple, Automated and Continuous deployment (in the documentation, they are called respectively level 1, 2, and 3). When only Level 1 of the CDDS extension is installed (for simple deployment), the Training environment is not needed and the Training space is not created during the CDDS installation.
Finally, apparenty the Development space got deleted*. I am sorry for the inconvinience and thank you very much for reporting it. I reinstalled the CDDS extension and now it should work as described in the exercises. I hope you have time to try it out now.
Thank you for your comments! It will be useful feedback for the next course update. Please let us know if you find any other issues.
Best,
Lada
'* p.s. This is why the exercise instructions mention that this part of the exercises includes collaboration with other learners and it is important not to change or delete the CDDS spaces.
coming back to your question about outliers and partitioning. There are different ways to detect outliers, and even the Numeric Outliers node that applies the interquartile range to detect outliers, allows you to customize the interquartile range multiplier. This means that the threshold can differ. Next, if the outliers are extremely close to the threshold and also to the next non-outlier values, maybe they are not that extreme to change the model behaviour significantly.
Maye a simple way to think about it is that the idea of the test data is to mimic the data that you don’t have yet. And you can’t use the data you don’t hae yet in the preparation of your model.
Many thanks to get at the issue. To give feedback is the least, I can do for a course free of charge.
About the training space. I am very sorry, my bad. I now see, I was not looking that correct type of diagram. It the continuous one, not the simple…
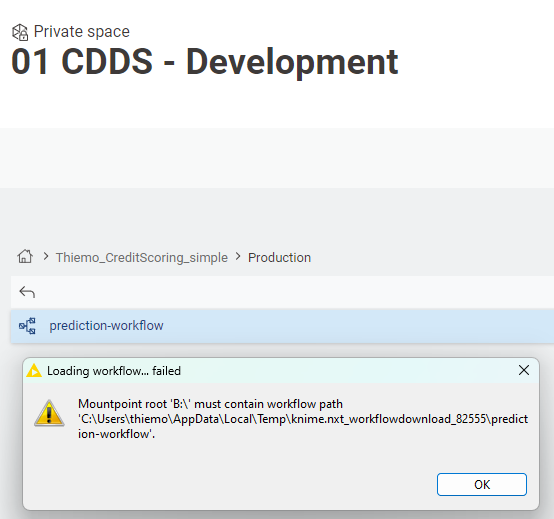
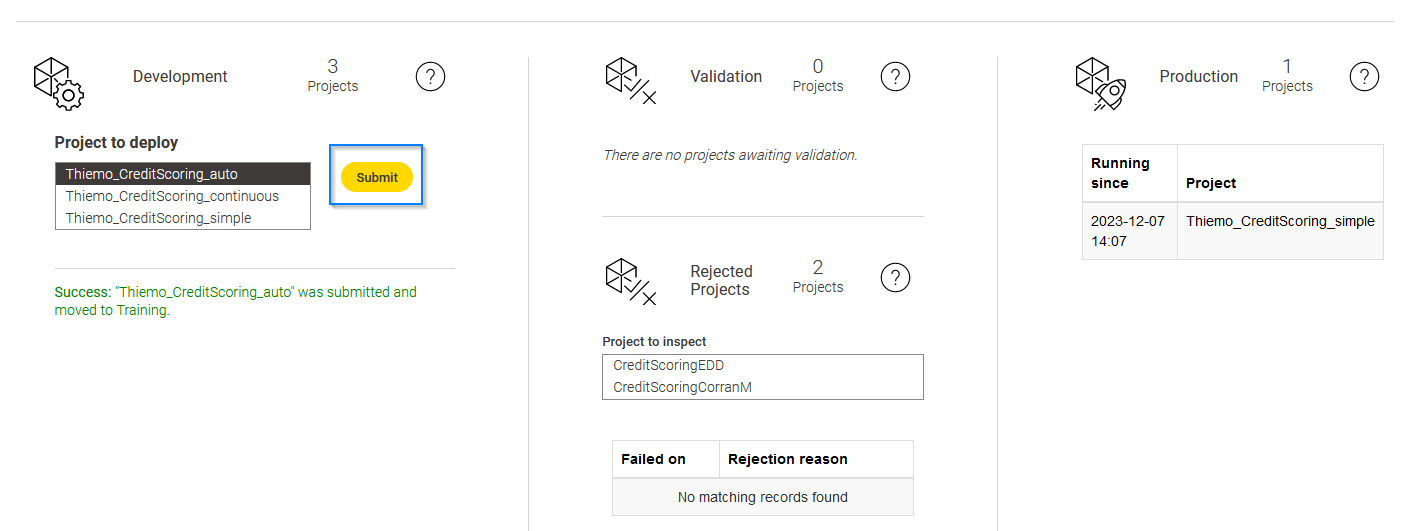
With respect to the missing Development space. I was afraid that someone had deleted it erroneously. Thanks for reinstalling it. I could deploy, but I am having still an issue.
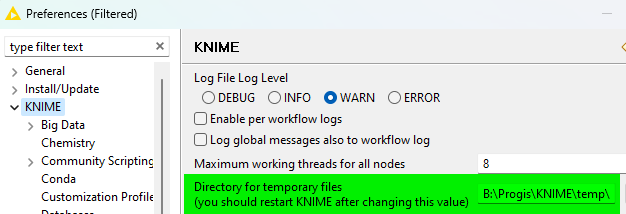
My KNIME installation is on the B drive while my Windows profile is on C. Does that error message mean, that the path of the temporary files must be within the installation?
I could make work the simple path and the continuous path. However, not the automated path. The upload worked bbut not the sending to training, even though it tells me it should have worked.
I am pretty sure, that addressing you with this issue is the wrong person, however, I hope you know to whom I should address, after having taken my L3 exam successfully.
First, in the exam I encountered a question that, to me at least, does not look like a question at all. I could attach a screenshot, but thought you might not want me to un-disclose it here. It starts with “A team …”.
Second, I would like to get an overview of my examination results such that I can figure out, which question I answered incorrectly to improve on that.
Thank you for your feedback about the certification question (and for not disclosing exam questions…). There was indeed a mistake in the question and we fixed it now.
I am exploring the L3 courses. That’s great for the new version of self-paced courses, but because of the network access we are not able to watch the videos. Is there any other way? Thank you.
Thanks for reaching out and letting us know that you can’t access the videos. We will try to find the solution as soon as possible and will get back to you.
Good day,
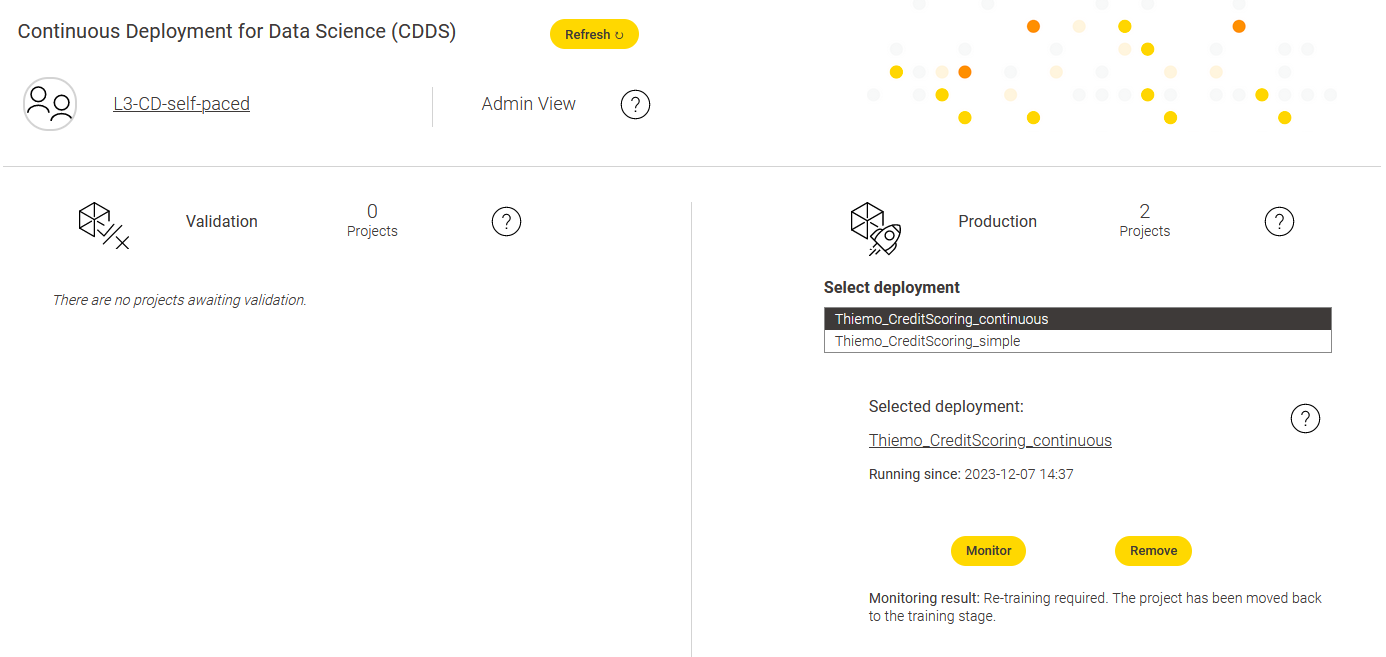
in module 8. Continuous Deployment for Data Science (CDDS) step 1 you talk about using the Configure Monitoring Output component. Is there an example of what this component might look like? I cannot find any hint on the forum for it.
I found this workflow Model Monitoring with Integrated Deployment but not sure if we refer to the same thing.
Thx :Kurt